

Ero isojen tietojen ja Apache Hadoopin välillä
Kaikki on Internetissä. Internetissä on paljon dataa. Siksi kaikki on iso data. Tiesitkö, että 2, 5 kvintillin tavua tietoja luodaan joka päivä ja kasataan suurena datana? Päivittäinen toimintamme, kuten kommentit, tykkäämiset, viestit jne. Sosiaalisessa mediassa, kuten Facebookissa, LinkedInissä, Twitterissä ja Instagramissa, ovat suurena tietona. Oletetaan, että vuoteen 2020 mennessä luodaan melkein 1, 7 megatavua dataa joka sekunti jokaiselle maapallon henkilölle. Voit kuvitella ja pohtia kuinka paljon tietoa syntyy olettaen, että jokainen ihminen maapallolla. Tänään olemme yhteydessä toisiinsa ja jaamme elämäämme verkossa. Suurin osa meistä on yhteydessä verkkoon. Elämme älykkäässä kodissa ja käytämme älykkäitä ajoneuvoja ja kaikki ovat yhteydessä älypuhelimiin. Kuvitteletko koskaan, kuinka näistä laitteista tulee älykkäitä? Haluan antaa teille hyvin yksinkertaisen vastauksen, koska se on analysoitu erittäin suurta tietomäärää eli Big Data. Viiden vuoden kuluessa maailmassa on yli 50 miljardia älykytkettyä laitetta, jotka kaikki on kehitetty keräämään, analysoimaan ja jakamaan tietoja elämämme mukavuuden parantamiseksi.
Seuraavat ovat Big Data vs. Apache Hadoopin esittelyt
Esittelyssä Term Big Data
Mikä on Big Data? Minkä koon tietoja pidetään isoina ja niitä kutsutaan isoiksi tiedoiksi? Meillä on monia suhteellisia oletuksia termelle Big Data. On mahdollista, että 50 teratavun tietomäärää voidaan pitää suurena datana Start-up-yrityksille, mutta se ei välttämättä ole Big Data yrityksille, kuten Google ja Facebook. Se johtuu siitä, että heillä on infrastruktuuri tällaisen tietomäärän tallentamiseksi ja käsittelemiseksi. Haluaisin määritellä termin Big Data seuraavasti:
- Big Data on tietomäärä, joka ylittää tekniikan kyvyn tallentaa, hallita ja prosessoida tehokkaasti.
- Big Data on tietoa, jonka mittakaava, monimuotoisuus ja monimutkaisuus vaativat uutta arkkitehtuuria, tekniikoita, algoritmeja ja analytiikkaa sen hallitsemiseksi ja arvon ja piilotetun tiedon poimimiseksi siitä.
- Big data on suuren määrän, nopeuden ja monimuotoisuuden tietoresursseja, jotka vaativat kustannustehokkaita, innovatiivisia tietojenkäsittelymuotoja, jotka mahdollistavat paremman ymmärryksen, päätöksenteon ja prosessien automatisoinnin.
- Big Data viittaa tekniikoihin ja aloitteisiin, jotka sisältävät tietoja, jotka ovat liian monimuotoisia, nopeasti muuttuvia tai massiivisia perinteisten tekniikoiden, taitojen ja infrastruktuurin kannalta, jotta niitä voidaan käsitellä tehokkaasti. Toisin sanoen datan määrä, nopeus tai monimuotoisuus on liian suuri.
3 V: n suuria tietoja
- Määrä: Määrä tarkoittaa määrää / määrää, jolla tietoja luodaan kuten joka tunti, Wal-Mart-asiakkaiden liiketoimet tarjoavat yritykselle noin 2, 5 petatavua dataa.
- Nopeus: Nopeudella tarkoitetaan tietojen liikkumisen nopeutta, kuten Facebookin käyttäjät lähettävät keskimäärin 31, 25 miljoonaa viestiä ja katselevat 2, 77 miljoonaa videota minuutissa joka päivä Internetissä.
- Variety: Variety viittaa erilaisiin datamuotoihin, jotka luodaan, kuten strukturoitu, osittain jäsentämätön ja jäsentämätön data. Kuten sähköpostien lähettäminen liitteineen Gmailiin on jäsentämätöntä tietoa, kun taas kommenttien lähettäminen joidenkin ulkoisten linkkien kanssa kutsutaan myös rakenteettomiksi tiedoiksi. Kuvien, äänileikkeiden ja videoleikkeiden jakaminen on jäsentämätöntä tietomuotoa.
Tämän suuren tiedon määrän, nopeuden ja monimuotoisuuden tallentaminen ja käsitteleminen on iso ongelma. Meidän on ajateltava muuta tekniikkaa kuin RDBMS for Big Data. Se johtuu siitä, että RDBMS pystyy tallentamaan ja käsittelemään vain jäsenneltyjä tietoja. Joten täällä Apache Hadoop on pelastus.
Esittelyssä Term Apache Hadoop
Apache Hadoop on avoimen lähdekoodin ohjelmistokehys tietojen tallentamiseksi ja sovellusten ajamiseksi hyödykelaitteistoklustereissa. Apache Hadoop on ohjelmistokehys, joka mahdollistaa suurten tietojoukkojen hajautetun käsittelyn tietokoneiden klusterien välillä yksinkertaisilla ohjelmointimalleilla. Se on suunniteltu laajentamaan yksittäisistä palvelimista tuhansiksi koneiksi, joista jokainen tarjoaa paikallisen laskennan ja tallennuksen. Apache Hadoop on kehys suurten tietojen tallentamiseen ja käsittelyyn. Apache Hadoop pystyy tallentamaan ja käsittelemään kaikkia tiedostomuotoja, kuten jäsenneltyä, osittain jäsentämätöntä ja jäsentämätöntä tietoa. Apache Hadoop on avoimen lähdekoodin ja hyödykelaitteistot toivat vallankumouksen IT-teollisuudelle. Se on helposti kaikkien tasojen yritysten käytettävissä. Niiden ei tarvitse investoida enemmän Hadoop-klusterin perustamiseen ja erilaisiin infrastruktuureihin. Joten voimme nähdä hyödyllisen eron Big Data: n ja Apache Hadoopin välillä yksityiskohtaisesti tässä viestissä.
Apache Hadoop -kehys
Apache Hadoop -kehys on jaettu kahteen osaan:
- Hadoop-hajautettu tiedostojärjestelmä (HDFS): Tämä kerros vastaa tietojen tallentamisesta.
- MapReduce: Tämä kerros vastaa tietojen käsittelystä Hadoop-klusterissa.
Hadoop Framework on jaettu master- ja slave-arkkitehtuuriin. Hadoop-hajautetun tiedostojärjestelmän (HDFS) kerroksen nimisolmu on pääkomponentti, kun taas datasolmu on orjakomponentti, kun taas MapReduce-kerroksessa Job Tracker on pääkomponentti, kun taas tehtäväseuranta on orjakomponentti. Alla on kaavio Apache Hadoop -kehyksestä.
Miksi Apache Hadoop on tärkeä?
- Kyky tallentaa ja käsitellä nopeasti valtavia määriä kaikenlaista tietoa
- Laskentateho: Hadoopin hajautettu laskentamalli käsittelee suurta dataa nopeasti. Mitä enemmän laskusolmuja käytät, sitä enemmän prosessointitehoa sinulla on.
- Vikasietoisuus: Tietojen ja sovellusten käsittely on suojattu laitteistovirheiltä. Jos solmu menee alas, työt ohjataan automaattisesti muihin solmuihin varmistaakseen, että hajautettu laskenta ei epäonnistu. Useita kopioita kaikista tiedoista tallennetaan automaattisesti.
- Joustavuus: Voit tallentaa niin paljon tietoja kuin haluat ja päättää, miten sitä käytetään myöhemmin. Se sisältää jäsentämätöntä tietoa, kuten tekstiä, kuvia ja videoita.
- Alhaiset kustannukset: Avoimen lähdekoodin kehys on ilmainen ja käyttää hyödykelaitteistoa suurten tietomäärien tallentamiseen.
- Skaalautuvuus: Voit helposti kasvattaa järjestelmääsi käsittelemään enemmän tietoja yksinkertaisesti lisäämällä solmuja. Tarvitaan vähän hallintoa
Head to Head -vertailu Big Data: n ja Apache Hadoopin välillä (Infographics)
Alla on 4 suosituinta vertailua Big Data: n ja Apache Hadoopin välillä
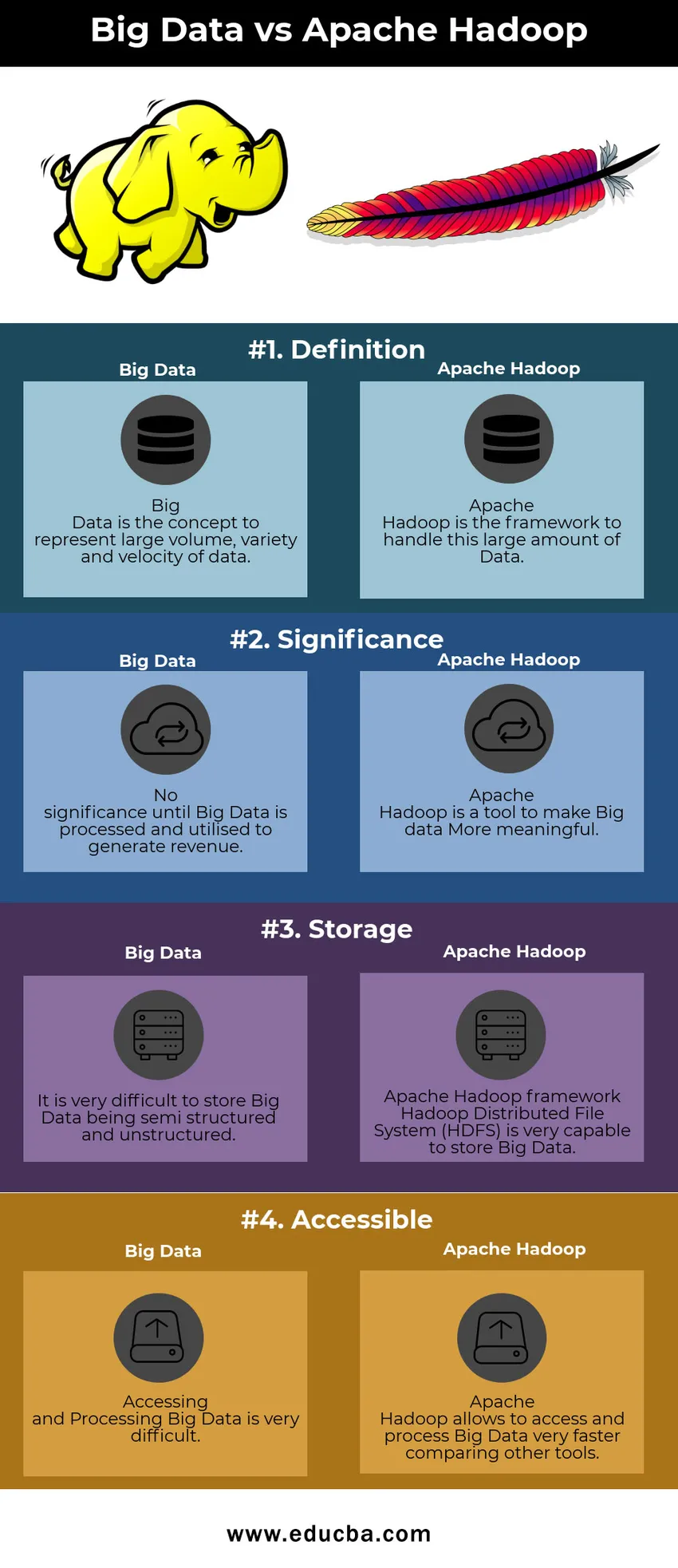
Big Data vs. Apache Hadoop -vertailutaulukko
Keskustelen tärkeimmistä esineistä ja eron Big Data vs Apache Hadoop välillä
| Suuri data | Apache Hadoop | |
| Määritelmä | Big Data on käsite edustaa suuren tiedon määrää, monimuotoisuutta ja nopeutta | Apache Hadoop on kehys tämän suuren tietomäärän käsittelemiseen |
| Merkitys | Ei merkitystä, ennen kuin Big Data on käsitelty ja hyödynnetty tulojen tuottamiseksi | Apache Hadoop on työkalu, jonka avulla iso data voidaan tehdä merkityksellisemmäksi |
| varastointi | On erittäin vaikeaa tallentaa Big Data -tekniikkaa puoliksi jäsenneltynä ja rakenteettomana | Apache Hadoop-kehys Hadoopin hajautettu tiedostojärjestelmä (HDFS) pystyy tallentamaan suuria tietoja |
| Saatavilla | Suurten tietojen käyttö ja käsittely on erittäin vaikeaa | Apache Hadoop antaa pääsyn Big Data -sovellukseen ja käsitellä sitä nopeammin verrattuna muihin työkaluihin |
Johtopäätös - Big Data vs. Apache Hadoop
Et voi verrata Big Data -sovellusta ja Apache Hadoop -sovellusta. Se johtuu siitä, että iso data on ongelma, kun Apache Hadoop on ratkaisu. Koska datan määrä kasvaa eksponentiaalisesti kaikilla sektoreilla, on siis erittäin vaikeaa tallentaa ja käsitellä tietoja yhdestä järjestelmästä. Joten tämän suuren tietomäärän käsittelemiseksi tarvitsemme hajautettua tietojen käsittelyä ja tallentamista. Siksi Apache Hadoop keksii ratkaisun erittäin suuren tietomäärän tallentamiseksi ja käsittelemiseksi. Lopuksi totean, että Big Data on suuri määrä monimutkaista dataa, kun taas Apache Hadoop on mekanismi isojen tietojen tallentamiseksi ja käsittelemiseksi erittäin tehokkaasti ja sujuvasti.
Suositeltava artikkeli
Tämä on opas Big Data vs. Apache Hadoop -sovellukseen, niiden merkitykseen, Head to Head -vertailuun, avainerot, vertailutaulukko ja johtopäätökset. Tämä artikkeli sisältää kaikki hyödylliset erot Big Data- ja Apache Hadoop -sovellusten välillä. Voit myös katsoa seuraavia artikkeleita saadaksesi lisätietoja -
- Big Data vs. Data Science - Kuinka ne eroavat?
- 5 suosituinta suurten tietojen kehityssuuntausta, jotka yritysten on hallittava
- Hadoop vs Apache Spark - Mielenkiintoisia asioita, jotka sinun täytyy tietää
- Apache Hadoop vs Apache Spark | 10 parasta vertailua, jotka sinun on tiedettävä!