

Johdanto Python Pandas DataFrame -sovellukseen
Python-kirjaston, Pandan, useita laajennuksia löytyy verkosta. Yksi sellainen on paneelitiedot (das). Tämä sana * Paneeli * viittaa hienovaraisesti tässä kirjastossa esiintyvään 2-ulotteiseen tietorakenteeseen, joka antaa käyttäjän käyttäjille valtavan valinnan. Tätä rakennetta kutsutaan DataFrame-kehykseksi.
Se on lähinnä rivien ja sarakkeiden matriisi, joka sisältää koko tietojoukon, ja erittäin indeksoidut vaihtoehdot indeksoida sama. DataFrame (DF) voidaan kuvitella kuvallisesti hyvin samankaltaiseksi kuin Excel-arkki. Mutta mikä tekee siitä tehokkaan, on se, kuinka helposti analyyttiset ja muunnosoperaatiot voidaan suorittaa DataFrame-kehykseen tallennetulle tiedolle.
Mikä tarkalleen on Python Pandas DataFrame?
Pydata-sivulle voidaan viitata jollain virallisella määritelmällä.
Jos se ymmärretään oikein, siinä mainitaan DataFrame pylväsrakenteena, joka pystyy tallentamaan minkä tahansa python-objektin (mukaan lukien itse DataFrame) yhden solun arvona. (Solu indeksoidaan käyttämällä ainutlaatuista rivi- ja sarakkeyhdistelmää)
DataFrames koostuu kolmesta tärkeästä komponentista: tiedoista, riveistä ja sarakkeista.
- Data: Se viittaa DataFrame-kehyksen soluun tallennettuihin todellisiin objekteihin / olioihin ja arvoihin, joita nämä entiteetit edustavat. Objekti on mitä tahansa kelvollista python-tietotyyppiä, onko se sisäänrakennettu tai käyttäjän määrittelemä.
- Rivit: Viittauksia, joita käytetään tietyn havaintojoukon tunnistamiseen (tai indeksointiin) DataFrame-tietokantaan tallennetusta täydellisestä tiedosta, kutsutaan riviksi. Vain selvyyden vuoksi se edustaa käytettyjä indeksejä eikä vain tietyn havainnon tietoja.
- Sarakkeet: Viitteet, joita käytetään määrittelemään (tai indeksoimaan) joukko attribuutteja kaikille DataFrame-kehyksen havainnoille. Kuten rivien tapauksessa, nämä viittaavat sarakeindeksiin (tai sarakeotsikoihin) pelkän sarakkeen tietojen sijaan.
Joten kokeilee joitain tapoja luoda nämä uskomattoman voimakkaat rakenteet ilman lisäohjeita.
Vaiheet Python Panda DataFrame -kehysten luomiseen
Python Pandas DataFrame voidaan luoda käyttämällä seuraavaa koodin toteutusta,
1. Tuo pandat
DataFrames-kehyksen luomiseen pandastekirjasto on tuotava (ei yllätystä). Tuomme sen aliaksella pd viiteobjekteihin moduulin alla sopivasti.
Koodi:
import pandas as pd
2. Ensimmäisen DataFrame-objektin luominen
Kun kirjasto on tuotu, kaikki menetelmät, toiminnot ja rakentajat ovat käytettävissä työtilassa. Yritetään siis luoda vanilja DataFrame.
Koodi:
import pandas as pd
df = pd.DataFrame()
print(df)
lähtö:
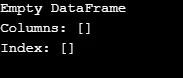
Kuten tuotos osoittaa, rakentaja palauttaa tyhjän DataFrame-kehyksen.
Keskitytään nyt DataFrame-kehyksen luomiseen tietoihin, jotka on tallennettu joihinkin todennäköisiin esityksiin.
- DataFrame sanakirjasta: Oletetaan, että meillä on sanakirja, joka tallentaa luettelon ohjelmistoalueen yrityksistä ja niiden aktiivisten vuosien lukumäärästä.
Koodi:
import pandas as pd
df = pd.DataFrame(
('Company':('Google', 'Amazon', 'Infosys', 'Directi'),
'Age':('21', '23', '38', '22') ))
print (df)
Katsotaanpa palautetun DataFrame-objektin esitys tulostamalla se konsoliin.
lähtö:

Kuten voidaan nähdä, sanakirjan kutakin näppäintä käsitellään sarakkeena DataFrame-kehyksessä, ja rivi-indeksit luodaan automaattisesti nollasta 0 alkaen. Melko helppo, eikö totta!
Oletetaan nyt, että halusit antaa sille mukautetun hakemiston 0, 1, 4 sijaan. Sinun on vain välitettävä haluttu luettelo parametrina rakentajalle, ja pandat tekevät tarpeelliset.
Koodi:
df = pd.DataFrame(
('Company':('Google', 'Amazon', 'Yahoo', 'Infosys', 'Directi'),
'Age':('21', '23', '24', '38', '22') ),
index=('Alpha', 'Beta', 'Gamma', 'Delta'))
print(df)
lähtö:
Yrityksen ikä
Alfa Google 21
Beta Amazon 23
Gamma Infosys 38
Delta Directi 22
Nyt voit asettaa rivi-indeksit mihin tahansa haluttuun arvoon.
- DataFrame CSV-tiedostosta: Luodaan CSV-tiedosto, joka sisältää samat tiedot kuin sanakirjamme tapauksessa. Soitetaan tiedostoksi CompanyAge.csv
Google, 21
Amazon, 23
Infosys, 38
Suorai, 22
Tiedosto voidaan ladata tietokehykseen (olettaen, että se on nykyisessä työhakemistossa) seuraavasti.
Koodi:
csv_df = pd.read_csv(
'CompanyAge.csv', names=('Company', 'Age'), header=None)
print(csv_df)
lähtö:
Yrityksen ikä
0 Google 21
1 Amazon 23
2 Infosys 38
3 Directi 22
Parametrien nimien asettaminen ohittamalla arvojen luettelon antaa ne sarakeotsikoiksi samassa järjestyksessä kuin ne ovat luettelossa. Samoin rivi-indeksit voidaan asettaa siirtämällä luettelo hakemistoparametrille, kuten edellisessä osassa esitetään. Otsikko = Ei mitään osoittaa puuttuvat sarakkeen otsikot datatiedostossa.
Oletetaan nyt, että sarakkeiden nimet olivat osa datatiedostoa. Sitten otsikon asettaminen = False suorittaa vaaditun työn.
3. CompanyAgeWithHeader.csv
Yritys, ikä
Google, 21
Amazon, 23
Infosys, 38
Suorai, 22
Koodi vaihtuu
csv_df = pd.read_csv(
'CompanyAgeWithHeader.csv', header=False)
print(csv_df)
lähtö:
Yrityksen ikä
0 Google 21
1 Amazon 23
2 Infosys 38
3 Directi 22
- DataFrame Excel-tiedostosta: Usein tietoja jaetaan Excel-tiedostoihin, koska ne ovat edelleen suosituin työkalu, jota tavalliset ihmiset käyttävät Adhocin seurantaan. Siksi keskusteluissamme ei pidä sivuuttaa sitä.
Oletetaan, että tiedot, samat kuin CompanyAgeWithHeader.csv, on nyt tallennettu CompanyAgeWithHeader.xlsx -lehdelle, jonka nimi on Company Age. Sama DataFrame kuin yllä luodaan seuraavalla koodilla.
Koodi:
excel_df= pd.read_excel('CompanyAgeWithHeader.xlsx', sheet_name='CompanyAge')
print(excel_df)
lähtö:
Yrityksen ikä
0 Google 21
1 Amazon 23
2 Infosys 38
3 Directi 22
Kuten näette, sama DataFrame voidaan luoda siirtämällä tiedostonimi ja arkin nimi.
Lisälukemat ja seuraavat vaiheet
Esitetyt menetelmät muodostavat hyvin pienen alajoukon verrattuna kaikkiin erilaisiin tapoihin, joilla DataFrames voidaan luoda. Ne luotiin tarkoituksella päästä alkuun. Sinun tulisi ehdottomasti tutkia lueteltuja viitteitä ja yrittää tutkia muita tapoja, mukaan lukien yhteyden muodostaminen tietokantaan lukeaksesi tietoja suoraan DataFrame-kehykseen.
johtopäätös
Pandas DataFrame on osoittautunut pelinvaihtajaksi datatieteen ja data-analyysin maailmassa, ja se on myös kätevä tapauskohtaisille lyhytaikaisille projekteille. Sen mukana tulee armeija työkaluja, jotka pystyvät viipaloimaan ja pilkkomaan datajoukon erittäin helposti. Toivottavasti tämä toimii askeleena matkalla eteenpäin.
Suositellut artikkelit
Tämä on opas Python-Pandas DataFrame -sovellukseen. Tässä keskustellaan vaiheista python-pandas-datakehyksen luomiseksi yhdessä koodin toteutuksen kanssa. Voit myös katsoa seuraavia artikkeleita saadaksesi lisätietoja -
- Pythonin 15 parasta ominaisuutta
- Erityyppiset python-sarjat
- Pythonin 4 suosituinta muuttujatyyppiä
- Pythonin kuusi parasta toimittajaa
- Tietorakenteen taulukot