
Mikä on GLM R: ssä?
Generalisoidut lineaariset mallit ovat lineaaristen regressiomallien osajoukko, joka tukee tehokkaasti ei-normaalijakaumaa. Tämän tukemiseksi on suositeltavaa käyttää glm () -toimintoa. GLM toimii hyvin muuttujan kanssa, kun varianssi ei ole vakio ja jakautuu normaalisti. Linkkifunktio määritetään vastausmuuttujan muuttamiseksi sopivaksi malliksi. LM-malli tehdään sekä perheen että kaavan kanssa. GLM-mallissa on kolme avainkomponenttia, joita kutsutaan satunnaiseksi (todennäköisyys), systemaattinen (lineaarinen ennustaja), linkkikomponentiksi (logit-toiminnolle). Glm: n käytön etuna on, että niillä on mallin joustavuus, ei tarvitse jatkuvaa varianssia ja tämä malli sopii suurimman todennäköisyyden arviointiin ja sen suhteisiin. Tässä aiheesta aiomme oppia GLM: stä R.
GLM-toiminto
Syntaksi: glm (kaava, perhe, data, painot, alajoukko, alku = nolla, malli = tosi, menetelmä = ””…)
Perhetyypit (mukaan lukien mallityypit) sisältävät binomi-, Poisson-, Gaussian-, gamma-, kvasi-tyypit. Jokainen jakelu suorittaa erilaisen käytön ja sitä voidaan käyttää joko luokittelussa ja ennustamisessa. Ja kun malli on gaussialainen, vastauksen tulisi olla todellinen kokonaisluku.
Ja kun malli on binomiaalinen, vasteen tulisi olla luokka binaariarvoilla.
Ja kun malli on Poisson, vasteen tulisi olla ei-negatiivinen numeerisella arvolla.
Ja kun malli on gamma, vasteen tulisi olla positiivinen numeerinen arvo.
glm.fit () - sopii malliin
Lrfit () - tarkoittaa logistista regressiosovitusta.
päivitys () - auttaa mallin päivittämisessä.
anova () - se on valinnainen testi.
Kuinka luoda GLM R: ssä?
Tässä nähdään kuinka luoda helppo yleistetty lineaarinen malli binaaritiedoilla käyttämällä glm () -toimintoa. Ja jatkamalla Trees-tietojoukkoa.
esimerkit
// Kirjaston tuominenlibrary(dplyr)
glimpse(trees)

Kategoristen arvojen näkemiseksi määritetään tekijät.
levels(factor(trees$Girth))
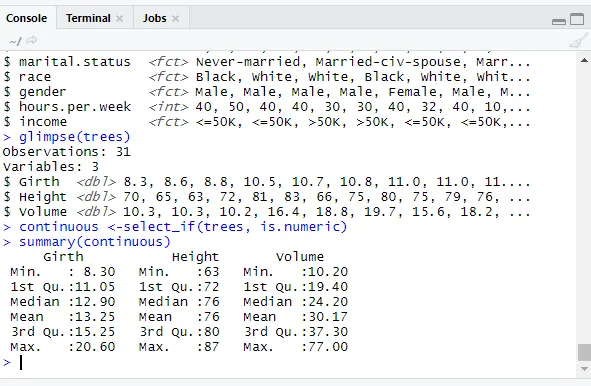
// Jatkuvien muuttujien tarkistaminen
library(dplyr)
continuous <-select_if(trees, is.numeric)
summary(continuous)
// Sisältää puutietoaineiston R-haussa Pathattach (puut)
x<-glm(Volume~Height+Girth)
x
lähtö:
| Soita: glm (kaava = äänenvoimakkuus ~ korkeus + ympärysmitta)
kertoimet: Korkeusmitta -57.9877 0.3393 4.7082 Vapausaste: 30 Yhteensä (eli nolla); 28 jäännös Null Deviance: 8106 Jäännöspoikkeus: 421, 9 AIC: 176, 9 |
summary(x)
| Puhelu:
glm (kaava = tilavuus ~ korkeus + ympärysmitta) Deviance-jäännökset: Min 1Q Median 3Q Max -6, 4065 -2, 6493 -0, 2876 2, 2003 8, 4847 kertoimet: Estimate Std. Virhe t-arvo Pr (> | t |) (Leikkaus) -57.9877 8.6382 -6.713 2.75e-07 *** Korkeus 0.3393 0.1302 2.607 0.0145 * Pituus 4.7082 0.2643 17.816 <2e-16 *** - SIGNIF. koodit: 0 '***' 0, 001 '**' 0, 01 '*' 0, 05 '.' 0, 1 '' 1 (Hajaantumisparametri gaussialaiselle perheelle on 15.06862) Nollapoikkeama: 8106.08 30 vapausasteessa Jäännöspoikkeama: 421, 92 28 vapausastetta AIC: 176, 91 Fisherin pisteytyskertojen lukumäärä: 2 |
Yhteenveto-toiminnon lähtö antaa puhelut, kertoimet ja jäännökset. Yllä olevat vastaukset osoittavat, että sekä korkeuden että ympäryskertoimen tehot eivät ole merkitseviä, koska niiden todennäköisyys on alle 0, 5. Ja poikkeamia on kaksi, nimeltään nolla ja jäännös. Lopuksi kalastajan pisteytys on algoritmi, joka ratkaisee suurimpaan todennäköisyyteen liittyvät kysymykset. Binomiaalilla vaste on vektori tai matriisi. cbind (): tä käytetään sitomaan pylväsvektoreita matriisissa. Ja saadaksesi yksityiskohtaiset tiedot sopivuusyhteenvedosta käytetään.
Todella kuin huppu-testi, seuraava koodi suoritetaan.
step(x, test="LRT")
Start: AIC=176.91
Volume ~ Height + Girth
Df Deviance AIC scaled dev. Pr(>Chi)
421.9 176.91
- Height 1 524.3 181.65 6.735 0.009455 **
- Girth 1 5204.9 252.80 77.889 < 2.2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Call: glm(formula = Volume ~ Height + Girth)
Coefficients:
(Intercept) Height Girth
-57.9877 0.3393 4.7082
Degrees of Freedom: 30 Total (ie Null); 28 Residual
Null Deviance: 8106
Residual Deviance: 421.9 AIC: 176.9
Malli sopii
a<-cbind(Height, Girth - Height)
> a
Yhteenveto (puut)
Girth Height Volume
Min. : 8.30 Min. :63 Min. :10.20
1st Qu.:11.05 1st Qu.:72 1st Qu.:19.40
Median :12.90 Median :76 Median :24.20
Mean :13.25 Mean :76 Mean :30.17
3rd Qu.:15.25 3rd Qu.:80 3rd Qu.:37.30
Max. :20.60 Max. :87 Max. :77.00
Saadaksesi sopiva keskihajonta
apply(trees, sd)
Girth Height Volume
3.138139 6.371813 16.437846
predict <- predict(logit, data_test, type = 'response')
Seuraavaksi viitataan laskentavastemuuttujaan malliksi hyvä vastesovellus. Tämän laskemiseksi käytämme USAccDeath-tietojoukkoa.
Anna meidän kirjoittaa seuraavat katkelmat R-konsoliin ja katsoa, kuinka vuosilaskenta ja vuosiruutu suoritetaan heille.
data("USAccDeaths")
force(USAccDeaths)
// Analysoida vuotta 1973-1978.
disc <- data.frame(count=as.numeric(USAccDeaths), year=seq(0, (length(USAccDeaths)-1), 1)))
yearSqr=disc$year^2
a1 <- glm(count~year+yearSqr, family="poisson", data=disc)
summary(a1)
| Puhelu:
glm (kaava = laskea ~ vuosi + vuosiSqr, perhe = “poisson”, data = levy) Deviance-jäännökset: Min 1Q Median 3Q Max -22, 4344 -6, 4401 -0, 0981 6, 0508 21, 4578 kertoimet: Estimate Std. Virhe z-arvo Pr (> | z |) (Leikkaus) 9.187e + 00 3.557e-03 2582.49 <2e-16 *** vuosi -7.207e-03 2.354e-04 -30.62 <2e-16 *** yearSqr 8.841e-05 3.221e-06 27.45 <2e-16 *** - SIGNIF. koodit: 0 '***' 0, 001 '**' 0, 01 '*' 0, 05 '.' 0, 1 '' 1 (Dispersioparametri Poisson-perheelle on 1) Nollapoikkeama: 7357.4 71 vapausasteessa Jäännöspoikkeama: 6358, 0 69 vapauden asteella AIC: 7149, 8 Fisherin pisteytyskertojen lukumäärä: 4 |
Seuraavan komennon avulla voidaan varmistaa mallin parhaan sopivuuden löytäminen
testin jäännökset. Alla olevan tuloksen perusteella arvo on 0.
1 - pchisq(deviance(a1), df.residual(a1))
Käytä QuasiPoisson-perhettä suurempana variaationa annettuihin tietoihin
a2 <- glm(count~year+yearSqr, family="quasipoisson", data=disc)
summary(a2)
| Puhelu:
glm (kaava = laskea ~ vuosi + vuosiSqr, perhe = “kvaasipoisson”, data = levy) Deviance-jäännökset: Min 1Q Median 3Q Max -22, 4344 -6, 4401 -0, 0981 6, 0508 21, 4578 kertoimet: Estimate Std. Virhe t-arvo Pr (> | t |) (Leikkaus) 9.187e + 00 3.417e-02 268.822 <2e-16 *** vuosi -7.207e-03 2.261e-03 -3.188 0.00216 ** yearSqr 8.841e-05 3.095e-05 2.857 0.00565 ** - (Kvasipoissoniperheen dispersioparametri on 92, 28857) Nollapoikkeama: 7357.4 71 vapausasteessa Jäännöspoikkeama: 6358, 0 69 vapauden asteella AIC: NA Fisherin pisteytyskertojen lukumäärä: 4 |
Poissonin vertaaminen binomiaaliseen AIC-arvoon eroaa merkittävästi. Niitä voidaan analysoida tarkkuuden ja palautussuhteen avulla. Seuraava askel on varmistaa, että jäännösvarianssi on verrannollinen keskiarvoon. Sitten voimme piirtää ROCR-kirjaston avulla mallin parantamiseksi.
johtopäätös
Siksi olemme keskittyneet erityiseen malliin, jota kutsutaan yleistetyksi lineaarimalliksi, joka auttaa keskittymään ja arvioimaan mallin parametreja. Se on ensisijaisesti potentiaali jatkuvalle vastemuuttujalle. Ja olemme nähneet kuinka glm sopii sisäänrakennettuihin R-paketteihin. Ne ovat suosituimpia lähestymistapoja laskentatietojen mittaamiseen ja vankka työkalu tietotieteilijöiden käyttämiin luokittelutekniikoihin. R-kieli auttaa tietysti suorittamaan monimutkaisia matemaattisia tehtäviä
Suositellut artikkelit
Tämä on opas GLM: ään R. Tässä keskustelemme GLM-toiminnosta ja kuinka luoda GLM R: ssä puutietojoukkojen esimerkkien ja tulosteen kanssa. Voit myös tarkastella seuraavaa artikkelia saadaksesi lisätietoja -
- R-ohjelmointikieli
- Big Data -arkkitehtuuri
- Logistinen regressio R: ssä
- Big Data Analytics -työt
- Poisson-regressio R: ssä Poisson-regression toteuttaminen