

Mikä on Big Data ja Hadoop?
Tiedot kasvavat eksponentiaalisesti joka päivä, ja tällaisen kasvavan tiedon myötä on tarpeen käyttää näitä tietoja. Kuten vanhoina päivinä, meillä oli ennenkin levykkeitä tietojen tallentamiseen, ja tiedonsiirto oli myös hidasta, mutta nykyään nämä ovat riittämättömiä ja pilvivarastoa käytetään, koska meillä on teratavua dataa. Nykymaailmassa sosiaalisen median osuus tietojen kasvusta on suurin. Se koostuu ihmisten käyttäytymisestä, ajattelutavasta ja monista muista näkökohdista. Sanotaan, että joka minuutti ladataan YouTubeen 300 tunnin videotunnit, Facebookissa ja monissa muissa ladataan yli 20 miljoonaa kuvaa. Lisäksi ladattavien tietojen rakenteella ei ole asianmukaista rakennetta, mikä on suurin haaste näiden tietojen käsittelylle.
Koska valtavasti dataa syntyy suurella nopeudella, perinteiset RDBMS-järjestelmät eivät kyenneet käsittelemään niin nopeaa kasvua. Lisäksi ne eivät myöskään pysty käsittelemään jäsentämätöntä tietoa. Oli erittäin vaikeaa käsitellä niin suurta määrää heterogeenistä dataa, joka kasvaa nopeasti, ja käsitellä näitä tietoja suurella käsittelynopeudella. Siksi tuli tarve sellaiselle järjestelmälle, joka pystyy käsittelemään suuria aineistoja tehokkaasti. Siksi Hadoop syntyi skenaarion ratkaisemiseksi. HDFS on Hadoopin komponentti, joka käsitteli suuren tietojoukon tallennusongelmaa käyttämällä hajautettua tallennusta, kun taas YARN on komponentti, joka käsitteli prosessointikysymystä vähentäen käsittelyaikaa rajusti.
Hadoop on avoimen lähdekoodin ohjelmistokehys suurten tietojoukkojen varastointiin ja käsittelyyn käyttämällä hajautettua suurta hyödykelaitteiston klusteria. Sen ovat kehittäneet Doug Cutting ja Michael J. Cafarella, ja sen lisensointi on Apache. Se on kirjoitettu Java-ohjelmalla ja se on kehitetty Googlen MapReduce-järjestelmään kirjoittaman paperin pohjalta, ja siinä käytetään käsitteitä toiminnallisesta ohjelmoinnista. Se on luotettava, taloudellinen joustava ja skaalautuva.
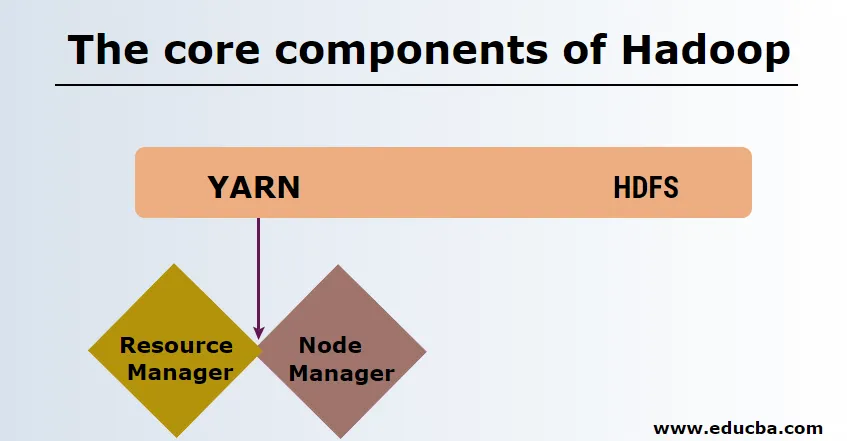
Hadoopin ydinkomponentit
Hadoopin ydinkomponentit ovat seuraavat
-
HDFS
HDFS- tai Hadoop-hajautetussa tiedostojärjestelmässä on Namenode- ja datasolmu. Namenode on isäntäsolmua johtava isäntäsolmu, joka hallitsee datasolmuja ja seuraa kaikkia toimintoja. Datanodit ovat orjia, joihin tiedot todella tallennetaan.
-
LANKA
Lanka koostuu kahdesta pääkomponentista:
1. ResourceManager: Se toimii isäntäsolmussa ja hallitsee kaikkia resursseja ja ajoittaa kaikki sovellukset. Siinä on Scheduler & ApplicationManager.
2. NodeManager: Se toimii jokaisella slave-solmulla ja vastaa konttien hallinnasta ja resurssien käytön seurannasta.
Useita Hadoopin komponentteja
Hadoopilla on useita komponentteja, kuten sika, pesä, sqoop, flume, mahout, oozie, zookeeper, HBase jne.
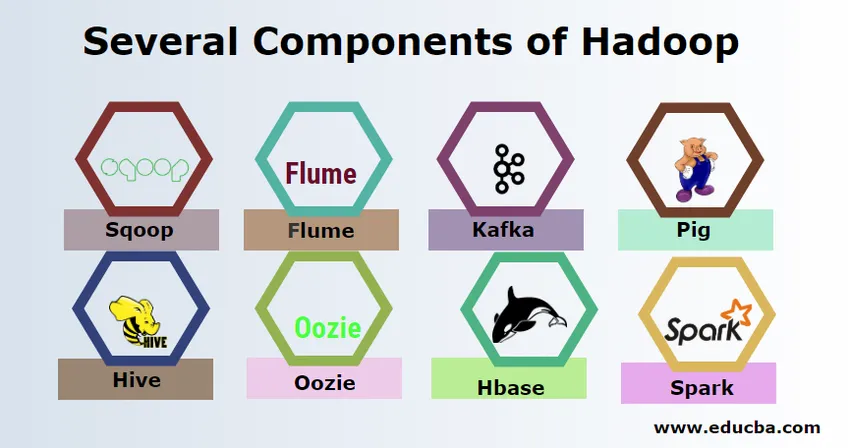
- Sqoop - Sitä käytetään tietojen tuontiin ja vientiin RDBMS: stä Hadoopiin ja päinvastoin.
- Flume - Sitä käytetään reaaliaikaisen tiedon vetämiseen Hadoopiin.
- Kafka - se on viestijärjestelmä, jota käytetään reaaliaikaisen tiedon reitittämiseen Hadoopiin.
- Sika - Sitä käytetään komentosarjojen kielenä tietojen käsittelyssä.
- Hive - Se on tietovarastokehys, joka perustuu HDFS: ään, jotta SQL: n tuntevat käyttäjät voivat suorittaa kyselyitä tietojen saamiseksi. Näitä kyselyitä kutsutaan HiveQL.
- Oozie - Sitä käytetään työn aikataulun ajoittamiseen tiettyjen tapahtumien tai ajan kulkemiseksi.
- Hbase - Se ei ole SQL-tietokanta, jota tarjotaan osana Apache Hadoop -sovellusta.
- Spark - Sitä käytetään muistiin tapahtuvaan käsittelyyn, joka on paljon nopeampaa kuin Hadoop map vähentää.
Hadoop-palveluntarjoajat
Hadoop-jakelua tarjoavia yrityksiä on paljon. Alla on muutama paras tarjoaja Hadoopille:
- Cloudera
- Hortonworks
- MapR
Hadoopin oppimiseen on vain vähän edellytyksiä. Aikaisempi kokemus Java- ja skriptikielestä on välttämätön. Vaikka Hadoopilla on jo omat korkean tason ohjelmointikielensä, kuten sika ja pesä, joka tuottaa taustakoodin jatkokäsittelyä varten, silti on mahdollista luoda oma kartta-vähentämisohjelma mille tahansa ohjelmointikielelle, kuten Ruby, Python, Perl ja jopa C-ohjelmointi.
Bigdatalla ja Hadoopilla on kysyntä nykypäivän markkinoilla. Se kasvaa entisestään tulevina päivinä. Monet organisaatiot ovat jo muuttaneet Hadoopiin, ja ne, jotka eivät aio muuttaa pian. Nykyisessä raportissa todetaan, että suuret yritykset ovat alkaneet investoida isojen tietojen analytiikkaan. Big data -markkinoinnin ennuste on aina nouseva trendi, eikä se ole ollenkaan lyhytikäinen. Kaikkien näiden lisäksi Hadoopin työpaikat ja big data tarjoavat aina korkean palkan verrattuna muihin tekniikoihin.
Suosituimmat Big Data- ja Hadoop-yritykset
Alla on muutama huippuyritys, jotka käyttävät eniten Hadoop-resursseja.
- Yahoo
- Amazon
- Skotlannin kuninkaallinen pankki
- British Airways
- Expedia
- Walmart
Suuria datasovelluksia käyttäviä yrityksiä on paljon. Nämä ovat:
-
Nokia
Se käyttää Cloudera- ja Hadoop-komponentteja, kuten HDFS, HBase, Sqoop, Scribe sovellukselle. Se käytti käyttäjätietoja tehokkaasti ymmärtää ja parantaa käyttäjän kokemusta. Se käyttää tietojenkäsittelyä ja monimutkaisia analyysejä kartan rakentamiseen ennustavilla liikenne- ja kerroskorkeusmalleilla.
-
SAS
Se on tehnyt yhteistyötä Hadoopin kanssa auttaakseen tietotekijöitä saamaan paremman käsityksen tarjoamalla visuaalisen ja vuorovaikutteisen kokemuksen tarjoavan ympäristön, mikä auttaa tutkimaan uusia suuntauksia. Analyyttiset ohjelmat poimivat merkitykselliset tiedot tiedoista ja muistin tekniikka auttaa nopeuttamaan tiedon saatavuutta.
On myös paljon muita yrityksiä, jotka käyttävät suuria tietoalustoja erilaisiin analyyseihin. Nämä ovat lentotekniikan mustan laatikon lentotietoanalyysi, erilainen osakemarkkinoiden analyysi jne.
Haddopin edut
Alla on muutama Hadoopin eduista
- Skaalautuva - Toisin kuin perinteinen RDBMS, se on erittäin skaalautuva alusta, koska se voi tallentaa suuria tietojoukkoja hajautettuihin klustereihin rinnakkain toimivien hyödykelaitteiden yli.
- Kustannustehokas - RDBMS: n kustannukset olivat liian korkeat tietojen tallentamiseksi, mikä on helpotettu Hadoopissa.
- Nopea ja joustava - Se tarjoaa tiedon nopeaan pääsyyn hajautetussa tiedostojärjestelmässään. Se tarjoaa myös liiketoimintatietojen saamisen puoliksi jäsennellystä ja jäsentämättömästä tiedosta.
- Vikasietoinen - Aina kun dataa lähetetään solmuun, sama data replikoidaan muihin solmuihin, joihin pääsee käsiksi ensimmäisen solmun vikaantumisen sattuessa.
Johtopäätös - mikä on Big Data ja Hadoop
Tietoja kasvatetaan jatkuvasti, ja siksi tarvitaan aina suuria tietoja ja Hadoopia, jotta näistä tiedoista olisi järkeä. Tästä syystä Hadoop-taitoja omaavat ammattilaiset löytävät aina runsaasti mahdollisuuksia lähipäivinä ja voivat olla tärkeä voimavara organisaatiolle, joka lisää yritystä ja heidän uransa.
Suositellut artikkelit
Tämä on opas siitä, mikä on Big Data ja Hadoop. Täällä olemme keskustelleet Big Data: n ja Hadoopin peruskäsitteistä ja komponenteista. Voit myös tarkastella seuraavaa artikkelia saadaksesi lisätietoja -
- Big Data Analytics -esimerkkejä
- Hadoopin käyttö
- Tietojen visualisoinnin opas
- Mikä on Big data -analytiikka?