
Ero HBase: n ja Cassandran välillä
HBase on tietokanta, joka käyttää Hadoopin hajautettua tiedostojärjestelmää tallennukseen. HBase on tärkeä osa HDFS: ää ja toimii Hadoop-klusterin päällä. HBase ei ole perinteinen relaatiotietokanta, se vaatii erilaista mallinnusmenetelmää. Cassandra toimii datan replikaatiomallin kanssa, joten jos mitään solmua ei ole käytettävissä, data ei mene. Cassandra on hajautettu tietokanta tarkoittaa, että asiakas voi käyttää tietoja mistä tahansa klusterista ja mistä tahansa solmusta
1.1) Cassandra:
Facebook aloitti sen, koska se on aina sovellusvaatimuksessa. Cassandra aloitettiin vuonna 2005, ja se saatettiin yleisön saataville vuonna 2008. Cassandra kehitettiin aina käytössä oleviin sovelluksiin, kuten sosiaalisiin verkostoihin, kuten Facebook ja Twitter.
Cassandra työskentelee "aina päällä" -arkkitehtuurilla ja sillä on aktiivinen-aktiivinen solmumalli, joten SPoF: ää (yksittäinen vikakohta) ei ole. CQL (Cassandra Query Language) on Cassandran kyselykieli, mutta sen syntaksi on sama kuin SQL. Se tukee kaikkia tärkeimpiä käyttöjärjestelmiä, kuten Linux, Unix, OSX ja Windows.
Aina päällä:
Cassandra on tietokanta, jolla on jakelumalli, ja kaikki solmut ovat samat klusterissa. Tiedot toistetaan konfiguroitavissa olevissa solmuissa, joten jos jotkut ei. solmujen määrä ei johda tietojen häviämiseen.
(Aina mallissa)
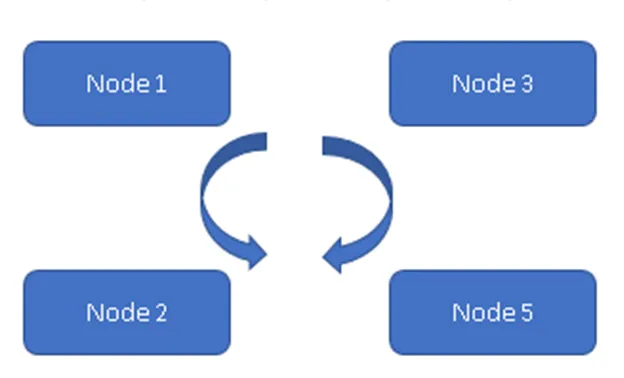
Kuviossa 1 kaikki neljä solmua ovat tahdissa keskenään ja replikoivat dataa klusterissa. Kaikki työskentelevät aktiivisen aktiivisen mallin parissa, joten minkään solmun vikaantuminen ei aiheuta tietojen menetystä. Asiakas voi lukea tietoja muista käytettävissä olevista solmuista / solmuista.
1.2) HBase:
HBase on NoSQL-pohjainen tietokanta, joka on suunniteltu käsittelemään kyselyitä suurissa taulukoissa, joissa on miljardeja rivejä miljoonilla sarakkeilla ja jotka kulkevat hyödyke / normaalin laitteiston klusterin läpi. Se tarjoaa sinulle reaaliaikaisen kyselyominaisuuden “ avain- / arvovaraston ” nopeudella.
HBase tosiasiallisesti perustuu / toimii nelidimensioisessa datamallissa.
- Rivin tunnus / rivinäppäin
- Sarake perhe.
- Avain-arvoparit.
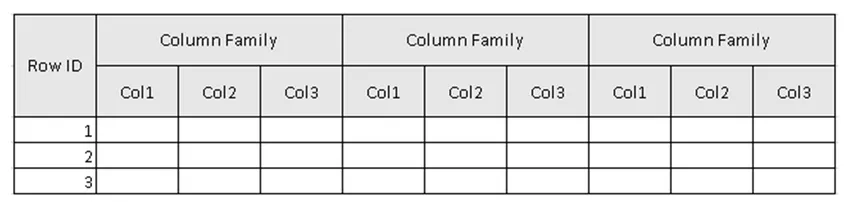
(Kuva 2, esimerkki taulukosta HBase-taulukossa.)
Kuvassa 2 taulukko on kokoelma sarakeperhettä ja sarakeperhe on kokoelma sarakkeita. Sarakkeet ovat avain-arvoparien kokoelma
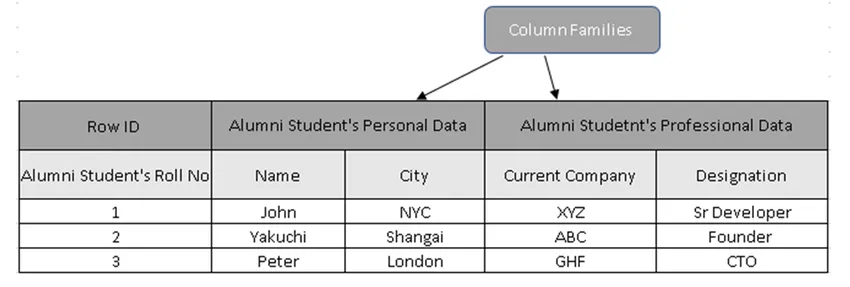
(Kuva 3, HBase-näytetaulukko)
Kuviossa 3 sarakeperheet ovat alumiini-opiskelijoiden tietojen kokoelma ja Rivitunnukset (Row Keys) sisältävät Opiskelijan Roll No.
Itse asiassa Rivinäppäimet pitävät ainutlaatuisen arvon sarakeperheen tietojen perusteella. Rivinäppäintä käyttämällä voidaan purkaa kaikki yksityiskohdat, syyt siihen, miksi sarakekeskeiset tietokannat ovat paljon nopeampia kuin perinteiset tietokannat.
Apache HBase -sovellusta voidaan käyttää satunnaiseen luku- / kirjoitusoikeuteen ja se tarjoaa vikatukea. Se tukee myös kopiointia ja levitystietokantamallin käsittelyä.
Head of Head -vertailu HBase vs. Cassandra (Infografia)
Alla on 9 parasta eroa HBase: n ja Cassandran välillä
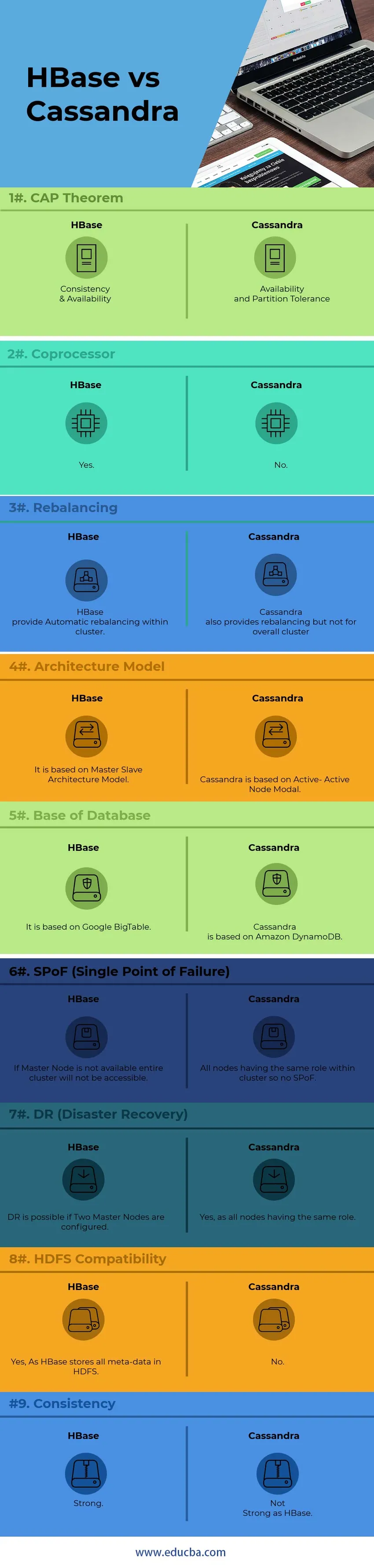 Keskeiset erot HBase ja Cassandra välillä
Keskeiset erot HBase ja Cassandra välillä
Alla on pisteluettelot, kuvaile HBase: n ja Cassandran tärkeimmät erot:
1) Sisäiseen solmujen viestintään Cassandra käyttää GOSSIP-protokollaa, kun taas HBase perustuu Zookeeperiin. GOSSIP-protokollan palvelut on integroitu Cassandran toiseen puoleen. Zookeeper on täysin erillinen jakelusovellus.
2) Cassandra-arkkitehtuurissa kaikki solmut toimivat aktiivisena solmuna, kun taas HBase-arkkitehti seuraa Master-Slave -solmumallia. Aktiivisissa-aktiivisissa solmu malleissa ei ole SPoF (Single Point of Failure). Jos HBase-järjestelmässä isäntäsolmu laskee, koko klusteria ei voida käyttää.
3) HBase-tuki Binaaripuunhakumalli, kun taas Cassandra ei tue B-puumallia Ilman B-puuta, et voi etsiä käyttäjän sarakeperhettä kaikille, joilla on vuosipäivä huhtikuussa, kun taas voit etsiä kaikkia, jotka asuvat Pekingissä Vuosipäivä huhtikuussa.
4) HBase, tuki C, C ++, Java, Python, Scala skriptikielet, kun taas Cassandra tukee myös JavaScriptiä ja Rubya.
5) HBaseella on yksi ominaisuus, jota kutsutaan kopioprosessoriksi, kun taas Cassandralla ei ole sellaista ominaisuutta kuin nyt. Kopioprosessorit tarjoavat kirjasto- ja ajonaikaisen ympäristön käyttäjäkoodin suorittamiseen HBase-alueen palvelimessa ja isäntäprosesseissa.
6) HBase on suunniteltu tukemaan tietovarastoa, kun taas Cassandra on täydellinen kaikkien aikojen sovelluksiin, kuten Web- ja mobiilisovelluksiin.
7) HBase-kyselykieli on mukautettu kieli, joka on opittava, kun taas Cassandra käyttää omaa kehitettyä CQL (Cassandra Query Language), joka on SQL-kaltainen kieli
8) Cassandran hallinta on paljon helpompaa kuin HBase. Cassandrassa on suoritettava yksi Java-prosessi solmua kohden, kun taas HBase: lle, täysin toiminnalliselle HDFS: lle, useille HBase-prosesseille ja Zookeeper-järjestelmälle tarvitaan.
9) HBase loppuu tarkistussummiin ja automaattiseen tasapainotukseen, kun taas Cassandra ei tue klusterin tasapainottamista kokonaisuudessaan.
10) CAP-lauseen perusteella Cassandra työskentelee AP-mallilla, kun taas HBase on CP-malli.
CAP-lause
Tätä lausea käytetään hajautettuihin järjestelmiin. C tarkoittaa johdonmukaisuutta, A tarkoittaa saatavuutta ja P on osiotoleranssi. YMP-lause alla selitetty:
C (johdonmukaisuus): Johdonmukaisuus tarkoittaa, että jos joku on kirjoittanut arvon tietokantaan, muut voivat heti lukea saman arvon.
A (Saatavuus) : Saatavuus tarkoittaa, että jotkut solmut eivät ole käytettävissä klusterissasi (Solmut menivät alas tai eivät asu klusterissa jonkin ongelman takia) eivät vaikuta koko klusteriin ja hajautettu järjestelmä / tietokanta on käytettävissä tietojen käyttämiseen. Klusteriin pääsee kaikenlaisissa tehtävissä.
P (osion toleranssi): osion toleranssi tarkoittaa, että yhden tietokeskuksen laskiessa edelleen, sen ei pitäisi vaikuttaa solmujen esitykseen ja kaikkien tietojen pitäisi olla käytettävissä milloin tahansa. Tarkoittaa, osiotoleranssi mahdollistaa datan paremman replikoinnin myös muihin tietokeskuksiin ja klusteriympäristössä.
HBase vs. Cassandra -vertailutaulukko
| pistettä | HBase | Cassandra |
| CAP-lause | Johdonmukaisuus ja saatavuus | Saatavuus ja osiotoleranssi |
| rinnakkaissuorittimen | Joo | Ei |
| tasapainottaminen | HBase tarjoaa automaattisen tasapainotuksen klusterissa. | Cassandra tarjoaa myös tasapainotuksen, mutta ei koko klusterille |
| Arkkitehtuurimalli | Se perustuu Master-Slave -arkkitehtuurimalliin | Cassandra perustuu Active-Active Node -modaaliin |
| Tietokannan perusta | Se perustuu Google BigTable -sovellukseen | Cassandra perustuu Amazon DynamoDB: hen |
| SPoF (yksittäinen vikakohta) | Jos isäntäsolmua ei ole käytettävissä, koko klusteria ei voida käyttää | Kaikilla solmuilla, joilla on sama rooli klusterissa, ei siis SPoF |
| DR (katastrofien palauttaminen) | DR on mahdollista, jos kaksi isäntäsolmua on määritetty. | Kyllä, koska kaikilla solmuilla on sama rooli |
| HDFS-yhteensopivuus | Kyllä, koska HBase tallentaa kaikki metatiedot HDFS: ään | Ei |
| johdonmukaisuus | Vahva | Ei vahva kuin HBase |
Johtopäätös - HBase vs. Cassandra
Facebook ja toinen sosiaalisen verkostoitumisen puoli mieluummin HBasea (aikaisemmin molemmat käyttivät Cassandraa, katso Facebook-viesti) saatavuuden takia toinen sivupankkien verkkotunnusala etsii turvallisuutta jokaiselle taloudelliselle tapahtumalleen, jotta he valitsevat Cassandran HBaseen.
Cassandran avainominaisuuksiin kuuluu korkea käytettävyys, minimaalinen hallinta ja ilman SPoF (Single Point of Failure) -puolen HBase on hyvä tietojen nopeampaan lukemiseen ja kirjoittamiseen lineaarisella skaalautuvuudella.
Yritykset, kuten Verizon, Bloomberg, Bank of America ja paljon muuta, käyttävät HBasea, ja Cassandraa käyttävät suuret sosiaalisen verkottumisen sivustot, kuten Twitter, Facebook jne.…
Emme voi päätellä kumpi on paras, HBasella ja Cassandralla on molemmat omat etunsa ja haittansa. Sekä HBase- että Cassandra-tietokantojen todellinen suorituskyky näkyy tuotantoympäristössä.
Suositellut artikkelit:
Tämä on opas HBase vs. Cassandra -sovellukselle, niiden merkitykselle, vertailulle pään ja pään välillä, keskeiset erot, vertailutaulukko ja johtopäätökset. Voit myös katsoa seuraavia artikkeleita saadaksesi lisätietoja -
- Hadoop vs Apache Spark - Mielenkiintoisia asioita, jotka sinun täytyy tietää
- Kuinka murtaa Hadoopin kehittäjähaastattelu?
- 5 suosituinta suurten tietojen suuntausta
- 5 Big Data Analytics -haastetta