
Johdanto koneoppimismalleihin
Katsaus useisiin käytännössä käytettyihin koneoppimismalleihin. Määritelmän mukaan koneoppimismalli on matemaattinen kokoonpano, joka saadaan tiettyjen koneoppimismenetelmien soveltamisen jälkeen. Laajaa sovellusliittymävalikoimaa käyttämällä koneoppimismallin rakentaminen on nykyään melko suoraviivaista vähemmällä koodirivillä. Soveltavan tietojenkäsittelytieteen ammattilaisen todellinen taito on kuitenkin oikean mallin valitsemisessa ongelmalausunnon ja ristiinvalidoinnin perusteella sen sijaan, että tietoja heitetään fancy-algoritmeihin satunnaisesti. Tässä artikkelissa keskustelemme erilaisista koneoppimismalleista ja siitä, kuinka niitä voidaan käyttää tehokkaasti ongelmien tyypin perusteella.
Koneoppimismallien tyypit
Tehtävien tyypin perusteella voimme luokitella koneoppimallit seuraaviin tyyppeihin:
- Luokittelumallit
- Regressiomallit
- klustereiden
- Dimensionality Reduction
- Syvä oppiminen jne.
1) Luokitus
Koneoppimisessa luokittelu on tehtävä ennustaa objektin tyyppi tai luokka rajallisessa määrässä vaihtoehtoja. Luokituksen lähtömuuttuja on aina kategorinen muuttuja. Esimerkiksi sähköpostin ennustaminen on roskapostia tai ei, on tavanomainen binaariluokitus. Nyt muistetaan joitain tärkeitä malleja luokitteluongelmiin.
- K-Lähin naapurien algoritmi - yksinkertainen, mutta laskennallisesti tyhjentävä.
- Naiivi Bayes - perustuu Bayes-lauseeseen.
- Logistic Regression - Lineaarinen malli binaariluokitukselle.
- SVM - voidaan käyttää binääri / moniluokka luokituksiin.
- Päätöspuu - ' Jos muualle ' perustuva luokitin, kestävämpi ulkopuolisille.
- Yhtyeet - Useiden koneoppimismallien yhdistelmä kerhottuna yhteen parempien tulosten saamiseksi.
2) Regressio
Koneessa regression oppiminen on joukko ongelmia, joissa lähtömuuttuja voi ottaa jatkuvia arvoja. Esimerkiksi lentoyhtiön hinnan ennustamista voidaan pitää tavanomaisena regressiotehtävänä. Otetaan muistiin joitain tärkeitä käytännössä käytettyjä regressiomalleja.
- Lineaarinen regressio - Yksinkertaisin perustason malli regressiotehtävälle, toimii hyvin vain, kun data on lineaarisesti erotettavissa ja jos moni-lineaarisuutta on vähän tai ei ollenkaan.
- Lasso-regressio - Lineaarinen regressio L2-vakioinnilla.
- Ridge Regression - Lineaarinen regressio L1-vakioinnilla.
- SVM-regressio
- Päätöksen puun regressio jne.
3) Klusterointi
Yksinkertaisin sanoin klusteroinnin tehtävänä on ryhmitellä samanlaisia objekteja yhteen. Koneoppimallit auttavat tunnistamaan samanlaisia kohteita automaattisesti ilman manuaalista puuttumista. Emme voi rakentaa tehokkaita ohjattuja koneoppimismalleja (malleja, jotka on koulutettava manuaalisesti kuratoidulla tai merkityllä tiedolla) ilman homogeenista tietoa. Klusterointi auttaa meitä saavuttamaan tämän älykkäämmällä tavalla. Seuraavassa on joitain laajalti käytettyjä klusterointimalleja:
- K tarkoittaa - yksinkertainen, mutta kärsii suuresta varianssista.
- K tarkoittaa ++ - K: n muokattu versio.
- K medoidit.
- Agglomeratiivinen klusterointi - hierarkkinen klusterointimalli.
- DBSCAN - tiheyspohjainen klusterointialgoritmi jne.
4) Mitat pienentäminen
Dimensionaalisuus on ennustajamuuttujien lukumäärä, jota käytetään ennustamaan riippumaton muuttuja tai tavoite.Fen reaalimaailman tietokokonaisuuksissa muuttujien lukumäärä on liian suuri. Liian monet muuttujat tuovat mallien ylikuormituksen kirouksen myöskin. Käytännössä näiden suuren määrän muuttujien joukossa kaikki muuttujat eivät osallistu tasaisesti tavoitteeseen ja useissa tapauksissa voimme todella säilyttää varianssit pienemmällä lukumäärällä muuttujia. Luettelemme joitain yleisesti käytettyjä malleja ulottuvuuden pienentämiseksi.
- PCA - Se luo pienemmän määrän uusia muuttujia suuresta määrästä ennustajia. Uudet muuttujat ovat toisistaan riippumattomia, mutta vähemmän tulkittavissa.
- TSNE - Tarjoaa korkeamman ulottuvuuden datapisteiden pienemmän upotuksen.
- SVD - Singulaariarvon hajoamista käytetään matriisin hajottamiseen pienempiin osiin tehokkaan laskennan mahdollistamiseksi.
5) Syvä oppiminen
Syväoppiminen on osa koneoppimista, joka käsittelee hermoverkkoja. Luettelemme hermoverkkojen arkkitehtuuriin perustuvat tärkeät syvän oppimisen mallit:
- Monikerroksinen perceptron
- Neuvontaverkot
- Toistuvat hermoverkot
- Boltzmann-kone
- Autokooderit jne.
Mikä malli on paras?
Edellä otimme ideoita monista koneoppimismalleista. Nyt mieleemme tulee ilmeinen kysymys 'Mikä on paras malli heistä?' Se riippuu käsiteltävästä ongelmasta ja muista siihen liittyvistä ominaisuuksista, kuten poikkeavuuksista, käytettävissä olevan tiedon määrästä, tiedon laadusta, ominaisuuksien suunnittelusta jne. Käytännössä on aina suositeltavaa aloittaa yksinkertaisimmalla mallilla, jota sovelletaan ongelmaan, ja lisäämään monimutkaisuutta vähitellen asianmukaisella parametrien virityksellä ja ristiinvalidoinnilla. Tietotekniikan maailmassa on sananlasku - ”ristivalidointi on luotettavampi kuin verkkotunnuksen tieto”.
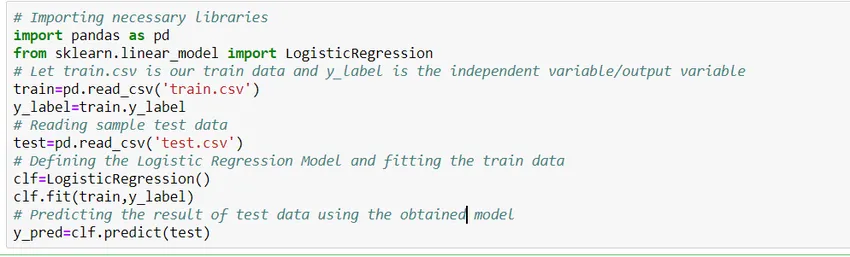
Kuinka rakentaa malli?
Katsotaan kuinka rakentaa yksinkertainen logistinen regressiomalli käyttämällä Pythonin Scikit Learn -kirjastoa. Yksinkertaisuuden vuoksi oletamme, että ongelma on vakioluokitusmalli ja 'train.csv' on juna ja 'test.csv' on juna- ja testitiedot.
johtopäätös
Tässä artikkelissa keskustelimme käytännön tarkoituksiin käytetyistä tärkeistä koneoppimismalleista ja siitä, kuinka rakentaa yksinkertainen koneoppimismalli pythoniin. Oikean mallin valinta tietylle käyttötapaukselle on erittäin tärkeää, jotta saadaan oikea tulos koneoppimistehtävästä. Suorituskyvyn vertaamiseksi eri mallien välillä määritetään arviointitiedot tai KPI-arvot tietyille liiketoimintaongelmille ja paras malli valitaan tuotantoon tilastollisen suoritustarkistuksen soveltamisen jälkeen.
Suositellut artikkelit
Tämä on opas koneoppimismalleihin. Tässä keskustellaan viidestä tyypistä koneoppimismallia sen määritelmän kanssa. Voit myös käydä läpi muiden ehdotettujen artikkeleidemme saadaksesi lisätietoja -
- Koneoppimismenetelmät
- Koneoppimisen tyypit
- Koneoppimisen algoritmit
- Mikä on koneoppiminen?
- Hyperparametrinen koneoppiminen
- KPI Power BI: ssä
- Hierarkkinen klusterointialgoritmi
- Hierarkkinen ryhmittely | Agglomeratiivinen ja jakautuva klusterointi