
Mikä on SVM-algoritmi?
SVM on tukivektorikone. SVM on valvottu koneoppimisalgoritmi, jota käytetään yleisesti luokittelu- ja regressiohaasteisiin. SVM-algoritmin yleisiä sovelluksia ovat tunkeutumisen tunnistusjärjestelmä, käsialan tunnistus, proteiinirakenteen ennustaminen, steganografian havaitseminen digitaalisissa kuvissa jne.
SVM-algoritmissa kukin piste esitetään tietoelementtinä n-ulotteisessa tilassa, jossa jokaisen ominaisuuden arvo on tietyn koordinaatin arvo.
Piirtämisen jälkeen luokittelu on suoritettu etsimällä hype-taso, joka erottaa kaksi luokkaa. Katso kuva alla ymmärtääksesi tätä käsitettä.
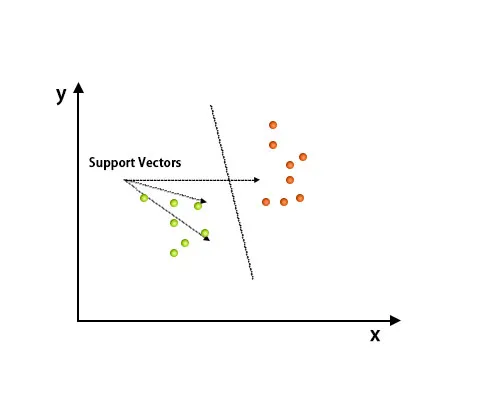
Support Vector Machine -algoritmia käytetään pääasiassa luokitteluongelmien ratkaisemiseen. Tukivektorit ovat vain kunkin tietokohteen koordinaatteja. Tukivektorikone on raja, joka erottaa kaksi luokkaa hypertason avulla.
Kuinka SVM-algoritmi toimii?
Yllä olevassa osassa olemme keskustelleet kahden luokan erottelusta hypertason avulla. Nyt aiomme nähdä miten tämä SVM-algoritmi todella toimii.
Skenaario 1: Tunnista oikea hypertaso
Täällä olemme ottaneet kolme hypertasoa eli A, B ja C. Nyt meidän on tunnistettava oikea hypertaso luokitellaksesi tähti ja ympyrä.
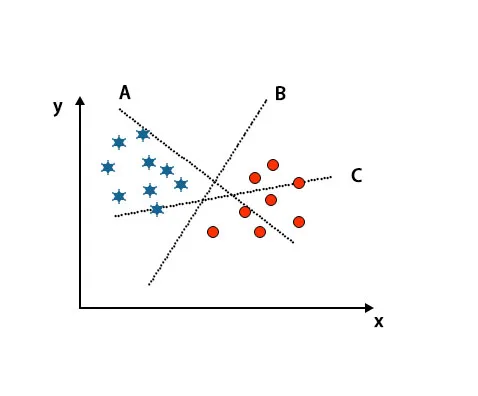
Oikean hypertason tunnistamiseksi meidän pitäisi tietää peukalon sääntö. Valitse hypertaso, joka erottaa kaksi luokkaa. Edellä mainitussa kuvassa hypertaso B erottaa kaksi luokkaa erittäin hyvin.
Skenaario 2: Tunnista oikea hypertaso
Täällä olemme ottaneet kolme hypertasoa eli A, B ja C. Nämä kolme hypertasoa erottavat luokittelut jo hyvin.
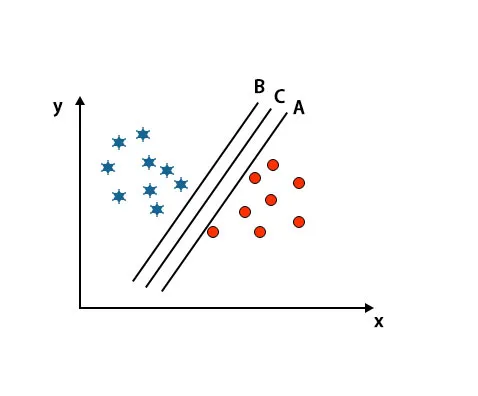
Tässä skenaariossa oikean hypertason tunnistamiseksi lisäämme etäisyyttä lähimpien datapisteiden välillä. Tämä etäisyys on vain marginaali. Katso kuvan alla.
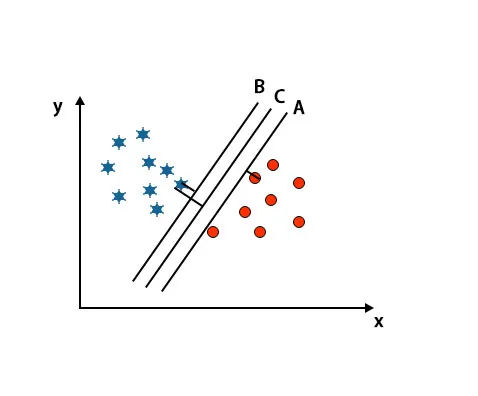
Yllä mainitussa kuvassa hypertason C marginaali on korkeampi kuin hypertason A ja hypertason B. Joten tässä skenaariossa C on oikea hypertaso. Jos valitsemme hyperlevyn minimimarginaalilla, se voi johtaa väärään luokitteluun. Siksi valitsimme hyperkortin C, jolla on suurin marginaali kestävyyden takia.
Skenaario 3: Tunnista oikea hypertaso
Huomaa: Hyper-tason tunnistamiseksi noudata samoja sääntöjä kuin aiemmissa kappaleissa.
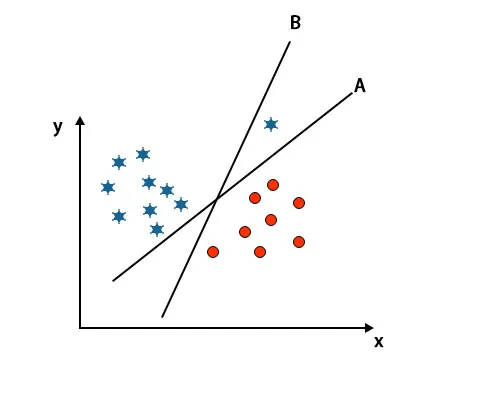
Kuten yllä mainitusta kuvasta voidaan nähdä, hypertason B marginaali on korkeampi kuin hypertason A marginaali, siksi jotkut valitsevat hypertason B oikealle. Mutta SVM-algoritmissa se valitsee sen hypertason, joka luokittelee luokkien tarkat ennen marginaalin maksimointia. Tässä skenaariossa hypertaso A on luokitellut kaikki tarkasti, ja hypertason B luokittelussa on joitain virheitä. Siksi A on oikea hypertaso.
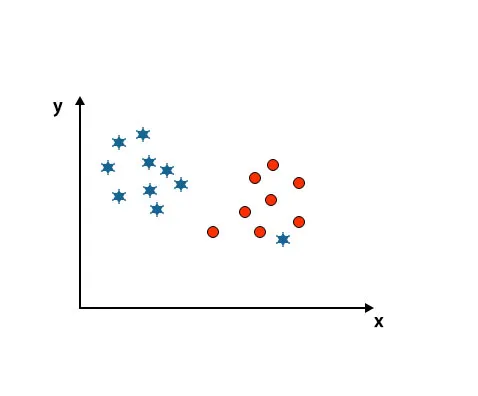
Skenaario 4: Luokittele kaksi luokkaa
Kuten alla olevasta kuvasta voidaan nähdä, emme pysty erottelemaan kahta luokkaa suoralla, koska yksi tähti sijaitsee toisella ympyräluokalla.
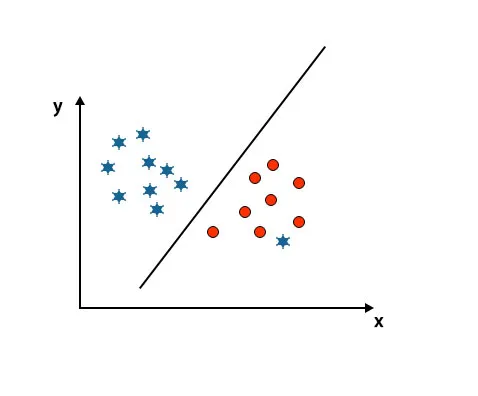
Täällä yksi tähti on toisessa luokassa. Tähtitunnilla tämä tähti on poikkeavin. SVM-algoritmin kestävyysominaisuuden takia se löytää oikean korkeammalla marginaalilla varustetun hypertason huomioimatta poikkeavuuden.
Skenaario 5: Hieno hypertaso luokkien erottamiseksi
Tähän asti olemme katsoneet lineaarista hypertasoa. Alla mainitussa kuvassa meillä ei ole lineaarista hypertasoa luokkien välillä.
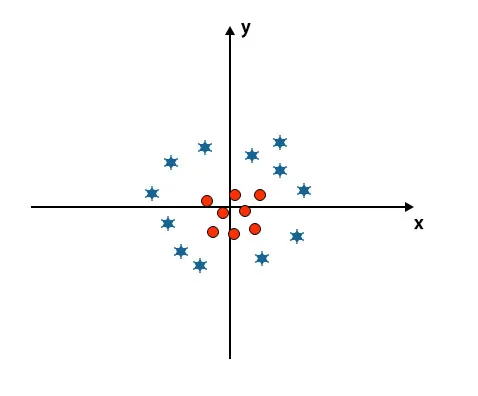
Näiden luokkien luokittelemiseksi SVM esittelee joitain lisäominaisuuksia. Tässä skenaariossa aiomme käyttää tätä uutta ominaisuutta z = x 2 + y 2.
Piirrä kaikki x- ja z-akselin datapisteet.

Huomautus
- Kaikkien z-akselin arvojen tulisi olla positiivisia, koska z on yhtä suuri kuin x: n ja y: n neliön summa.
- Edellä mainitussa kaaviossa punaiset ympyrät ovat suljettuina x-akselin ja y-akselin alkuperään, mikä johtaa arvon z laskemiseen ja tähti on täsmälleen vastakkaiset ympyrälle, se on poispäin x-akselin alkuperästä ja y-akseli, mikä johtaa z: n arvoon korkeaan.
SVM-algoritmissa on helppo luokitella lineaarisella hypertasolla kahden luokan välillä. Mutta tässä herää kysymys, pitäisikö lisätä tämä SVM: n ominaisuus hypertason tunnistamiseksi. Joten vastaus on ei, tämän ongelman ratkaisemiseksi SVM: llä on tekniikka, jota kutsutaan ytimen tempuksi.
Ydin Temppu on toiminto, joka muuttaa tiedon sopivaan muotoon. SVM-algoritmissa käytetään erityyppisiä ydinfunktioita, ts. Polynomi-, lineaarinen, epälineaarinen, radiaalisen perustoiminnon jne. Täällä ytimen temppulla pienimuotoinen syöttötila muunnetaan ylemmän ulottuvuuden tilaksi.
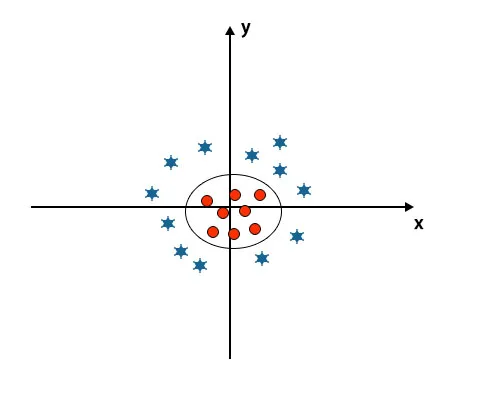
Kun tarkastelemme akselin ja y-akselin lähtöpinta-alaa, se näyttää ympyrältä. Katso kuvan alla.
Plussaa SVM-algoritmista
- Vaikka syöttötiedot ovat epälineaarisia ja erottamattomia, SVM: t tuottavat tarkkoja luokitustuloksia sen kestävyyden takia.
- Päätöstoiminnossa se käyttää tukipisteiksi kutsuttujen koulutuspisteiden osajoukkoa, joten se on muistitehokas.
- On hyödyllistä ratkaista kaikki monimutkaiset ongelmat sopivalla ytintoiminnolla.
- Käytännössä SVM-mallit yleistyvät, ja SVM: n liiallisen asennuksen riski on pienempi.
- SVM: t toimivat erinomaisesti tekstien luokittelussa ja parhaan lineaarierottimen löytämisessä.
Miinukset SVM Algorithm
- Suurten tietojoukkojen kanssa työskentely vie pitkän harjoitusajan.
- Lopullista mallia ja yksittäisiä vaikutuksia on vaikea ymmärtää.
johtopäätös
Se on opastettu tukemaan vektorikonealgoritmia, joka on koneoppimisalgoritmi. Tässä artikkelissa keskustelimme siitä, mikä on SVM-algoritmi, miten se toimii ja sen edut yksityiskohtaisesti.
Suositellut artikkelit
Tämä on opas SVM-algoritmiin. Tässä keskustellaan sen työskentelystä SVM-algoritmin skenaarion, etujen ja haittojen kanssa. Voit myös katsoa seuraavia artikkeleita saadaksesi lisätietoja -
- Tietojen louhinnan algoritmit
- Tietojen louhintatekniikat
- Mikä on koneoppiminen?
- Konetyökalut
- Esimerkkejä C ++ -algoritmista