

Ero Apache Hive: n ja Apache HBase: n välillä -
Apache Hive -tarina alkaa vuonna 2007, kun muiden kuin Java-ohjelmoijien on kamppailtava käyttäessään Hadoop MapReducea. Tutkijat ja kehittäjät ennustivat, että huomenna on Big Data -kausi. Jo erilaisia datamuotoja, kuten jäsennelty, osittain jäsentämätön ja jäsentämätön, kasaantui. Jopa Facebook kamppaili suuremman tietomäärän käsittelyn kanssa. Facebookin tutkijat esittelivät Apache Hive -sovelluksen tietojenkäsittelyä varten Hadoop-klusteriin. Facebook oli ensimmäinen yritys, joka keksi Apache Hiven.
Apache HBase -tarina alkaa vuonna 2006, kun San Franciscossa toimiva startup Powerset yritti rakentaa luonnollisen kielen hakukoneen verkolle. HBase on Googlen Bigtable-sovelluksen toteutus. Tajusimmeko koskaan, miksi oli tarpeen keksiä vielä yksi tallennusarkkitehtuuri? Relaatiotietokannan hallintajärjestelmä on ollut käytössä 1970-luvun alusta. Monissa käyttötapauksissa relaatiotietokannat ovat täysin järkeviä, mutta joissakin erityisissä ongelmissa relaatiomalli ei sovi kovin hyvin.
Selitän Apache Hivestä ja Apache HBaseesta tarkemmin.
Erot Apache Hive: n ja Apache HBase: n välillä
Apache Hive on Apache-avoimen lähdekoodin projekti, joka on rakennettu Hadoopin päälle suurten tietojoukkojen kyselyä, tiivistämistä ja analysointia varten SQL-tyyppisen käyttöliittymän avulla. Apache Hive tarjoaa SQL-tyyppisen kielen, nimeltään HiveQL, joka muuntaa kyselyt avoimesti MapReduce-sovellukseksi suorittamista varten Hadoopin hajautettuun tiedostojärjestelmään (HDFS) tallennettuihin suuriin tietojoukkoihin. Apache Hive on Hadoop-klusterikomponentti, jonka data-analyytikot yleensä käyttävät. Apache-pesää käytetään suurten ETL-töiden eräkäsittelyyn. Apache Hive tukee myös eräissä SQL-kyselyissä erittäin suuria tietojoukkoja. Apache Hive lisää kaavion suunnittelun joustavuutta sekä tietojen sarjoittamista ja ansioitumista. Apache Hive ei tue OLTP: tä (Online Transaction Processing), koska pesä ei tue kyselyitä reaaliajassa ja rivitason päivityksissä.
Apache HBase on avoimen lähdekoodin NoSQL-tietokanta, joka tarjoaa reaaliaikaisen, luku- ja kirjoitusoikeuden suuriin tietojoukkoihin. NoSQL on ei-relaatiotietokanta. Apache HBase on hajautettu sarakekeskeinen tietokanta, joka toimii Hadoopin hajautetun tiedostojärjestelmän (HDFS) päällä. Joten, HBase tuo NoSQL: n etuja Hadoopille. Apache HBase tarjoaa HDFS: ssä olevan datan hajasaantiominaisuudet. Se hyödyntää HDFS: n tarjoamaa vikasietoisuutta. Käyttäjä voi tallentaa tiedot HDFS: ään joko suoraan tai HBase: n kautta.
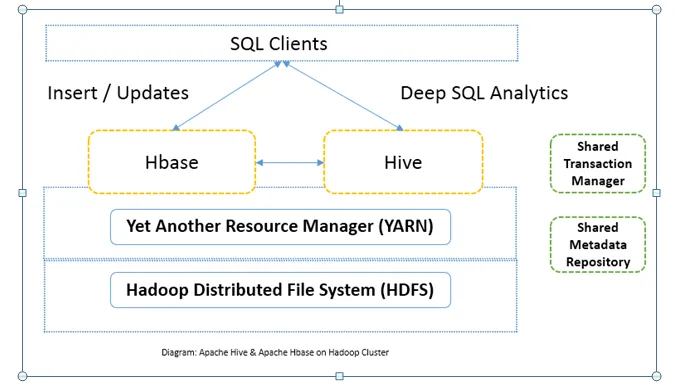
Head to Head -vertailu Apache Hive: n ja Apache HBase: n välillä (Infographics)
Alla on 12 parasta eroa Apache Hive: n ja Apache HBase: n välillä

Keskeiset erot - Apache Hive vs Apache HBase
Alla on pisteluettelot, kuvaile keskeisiä eroja Apache Hive ja Apache HBase: n välillä:
- Apache HBase on tietokanta, kun taas Apache Hive on tietokantamoottori.
- Apache-pesää käytetään pääasiassa eräkäsittelyyn (OLAP), kun taas Apache HBase -käyttöä käytetään pääasiassa tapahtumakäsittelyyn (OLTP).
- Apache Hive suorittaa suurimman osan SQL-kyselyistä, kun taas Apache HBase ei salli SQL-kyselyjä suoraan.
- Apache Hive ei tue tietuetason toimintoja, kuten päivitystä, lisäämistä ja poistamista, kun taas Apache HBase tukee tietuetason toimintoja, kuten päivitystä, lisäämistä ja poistamista.
- Apache Hive toimii MapReducen päällä, kun Apache HBase toimii Hadoopin hajautetun tiedostojärjestelmän (HDFS) päällä.
Apache Hive kysyy tiedostoja määrittelemällä virtuaalitaulukon ja suorittamalla sen päälle HQL-kyselyt. Tämä on prosessi, jossa tiedostot kytketään käytännössä taulukkoon, kuten rakenne, ja käyttäjä voi suorittaa HQL-kyselykielen (Hive), ja nämä kyselyt muunnetaan Hive: n MapReduce Job -työksi. Käyttäjän ei tarvitse kirjoittaa MapReduce-työtä, HQL-kyselyt muunnetaan sisäisesti jar-tiedostoiksi ja nämä jar-tiedostot otetaan käyttöön tietojoukkoihin.
Apache HBase -sovelluksessa ollessa taulukot on jaettu alueisiin ja aluepalvelimet palvelevat niitä. Muut alueet on jaettu pystysuoraan sarakeperheiden mukaan sarakkeiksi myymälöiksi ja Kaupat tallennetaan tiedostoina HDFS: ään.
Milloin Apache Hiveä käytetään:
- Tietovarastointia koskevat vaatimukset
- Analyyttiset kyselyt
- Tietojen analysointi, jotka tuntevat SQL: n
Milloin Apache HBase -sovellusta käytetään:
- Nopea ja vuorovaikutteinen tietojenkäsittely
- Reaaliaikaiset kyselyt
- Pikahaut
- Palvelinpuolen käsittely
- Big Data -sovellus satunnaisesti
- Sovelluksen skaalautuvuus
Apache Hive -sovelluksella voidaan laskea sähköisen kaupan verkkosivustojen trendejä ja lokit tietyn keston, alueen tai aikavyöhykkeen mukaan. Sitä voidaan käyttää eräkyselyjen käsittelemiseen historiallisen datan yli, kun taas Facebook tai LinkedIn voi käyttää Apache HBase -sovellusta viestintään ja reaaliaikaiseen analysointiin. Sitä voidaan käyttää myös tykkien laskemiseen.
Apache Hive vs Apache HBase -vertailutaulukko
Keskustelen tärkeimmistä esineistä ja eron Apache Hive ja Apache HBase välillä.
| Apache-pesä | Apache HBase | |
| Tietojenkäsittely | Apache-pesää käytetään
eräkäsittely eli online Analytical Processing (OLAP) | Apache HBase -tapahtumaa käytetään tapahtumien käsittelyyn eli online-transaktiomenetelmään (OLTP) |
| Käsittelynopeus | Apache Hivellä on pidempi viive, koska MapReduce-työ suoritetaan taustalla | Apache HBase toimii reaaliaikaisessa kyselyssä ja paljon nopeammin kuin Apache Hive |
| Yhteensopivuus Hadoopin kanssa | Apache Hive toimii MapReducen päällä | Apache HBase toimii HDFS: n päällä |
| Määritelmä | Apache Hive on avoimen lähdekoodin ja samanlainen kuin SQL, jota käytetään analyyttisiin kyselyihin | Apache HBase on avoimen lähdekoodin NoSQL-tietokanta, jota käytetään reaaliaikaisiin kyselyihin |
| Jaetut metatiedot | Apache Hivessä luodut tiedot näkyvät automaattisesti Apache HBase: lle | Apache HBase -sovelluksessa luodut tiedot näkyvät automaattisesti Apache Hivelle |
| kaavio | Apache-pesä tukee Schemaa tietojen lisäämiseen taulukoihin | Apache HBase on Schema-vapaa tietokanta. |
| Päivitä ominaisuus | Päivitysominaisuus on monimutkainen Apache Hivessä | Käyttäjä voi helposti päivittää tietoja Apache HBase -sovelluksessa |
| toiminnot | Operaatiot Apache Hivessä eivät toimi reaaliajassa | Operaatiot Apache HBase -operaatiossa reaaliajassa |
| Tyypit | Apache Hive on tarkoitettu rakenteelliseen ja osittain rakenteelliseen dataan | Apache HBase on tarkoitettu jäsentelemättömälle tiedolle. |
| Johdonmukaisuustaso | Apache-pesä tukee lopullista johdonmukaisuutta | Apache HBase tukee välitöntä johdonmukaisuutta |
| Jakamismenetelmät | Apache Hive tukee Sharding-ominaisuuksia | Apache HBase tukee myös Sharding-ominaisuuksia |
| Tietovarasto | Päivämäärä tallennetaan Hive Metastore -sovellukseen, osiot ja kauhat Apache Hive -sovellukseen | Tiedot tallennetaan sarake- ja rivitasolla taulukoihin Apache HBase -sovelluksessa |
Johtopäätös - Apache Hive vs Apache HBase
Yleensä Apache Hive vs. Apache HBase: ta käytetään yhdessä samassa klusterissa. Molempia voidaan käyttää yhdessä tehostamaan prosessointitehoa. Koska pesä parantaa HDFS: n analyyttisiä puolia, kun taas HBase parantaa tapahtumia reaaliajassa. Käyttäjä voi käyttää Hiveä ETL-työkaluna erälisäkkeisiin, joissa on tietoja HBaseen, ja suorittaa sitten kyselyitä, jotka voivat edelleen liittää HBase-taulukoissa olevan datan datan kanssa, joka on jo HDFS: ssä. Tietoja voidaan lukea ja kirjoittaa Apache Hivestä HBaseen ja takaisin. Apache Hive: n ja Apache HBase: n välinen rajapinta on vielä kypsymässä. Tulevaa on paljon enemmän. Voin silti sanoa, että Sekä Apache Hive vs. Apache HBase tekevät Hadoop-klusterista vankeamman ja tehokkaamman.
Aiheeseen liittyvät artikkelit:
Tämä on opas Apache Hive vs Apache HBase -sovellukseen, niiden merkitys, Head to Head -vertailu, avainerot, vertailutaulukko ja johtopäätös. Voit myös katsoa seuraavia artikkeleita saadaksesi lisätietoja -
- 5 suosituinta suurten tietojen suuntausta
- 5 Big Data Analytics -haastetta
- Kuinka murtaa Hadoopin kehittäjähaastattelu?
- 5 Big Data Analytics -haastetta