

Ero Hadoopin ja pesän välillä
Hadoop:
Hadoop on kehys tai ohjelmisto, joka keksittiin hallitsemaan valtavaa dataa tai suuria tietoja. Hadoop-sovellusta käytetään suurten tietojen varastointiin ja käsittelemiseen hyödykepalvelinklusterien välillä.
Hadoop tallentaa tiedot Hadoopin hajautetulla tiedostojärjestelmällä ja käsittelee / hae sitä käyttämällä Map Reduce -ohjelmointimallia.
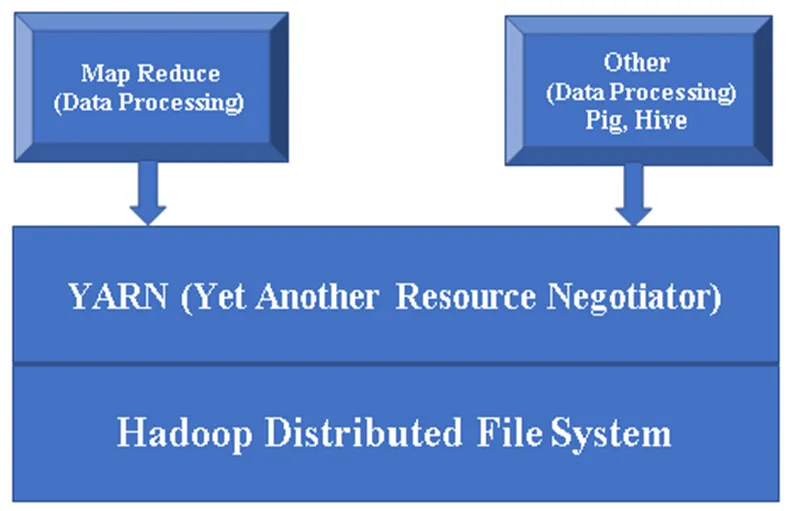
Kuvio 1, Hadoop-komponentin perusarkkitehtuuri.
Hadoopin tärkeimmät komponentit:
Hadoop Base / Common: Hadoop common tarjoaa sinulle yhden alustan kaikkien komponenttien asentamiseksi.
HDFS (Hadoop Distributed File System): HDFS on tärkeä osa Hadoop-kehystä, ja se huolehtii kaikista Hadoop-klusterin tiedoista. Se toimii Master / Slave -arkkitehtuurissa ja tallentaa tiedot replikoinnin avulla.
Master / Slave -arkkitehtuuri ja replikointi:
- Pääsolmu / nimisolmu: Nimesolmu tallentaa kunkin HDFS: ään tallennetun lohkon / tiedoston metatiedot, HDFS: llä voi olla vain yksi isäntäsolmu (HA: n tapauksessa toinen isäntäsolmu toimii toissijaisena isäntäsolmuna).
- Slave Solmu / datasolmu: Tietosolmut sisältävät todelliset datatiedostot lohkoina. HDFS: llä voi olla useita datasolmuja.
- Replikointi: HDFS tallentaa tietonsa jakamalla ne lohkoihin. Oletuslohkon koko on 64 Mt. Replikoitumisen takia tiedot tallennetaan 3: een (oletusreplikaatiotekijä, jota voidaan lisätä vaatimuksen mukaan) erilaisiin datasolmuihin, joten on pienin mahdollisuus menettää data missä tahansa solmun vikaantumisessa.
Lanka (vielä yksi resurssineuvottelija): Sitä käytetään periaatteessa Hadoop-resurssien hallintaan, ja sillä on myös tärkeä rooli käyttäjien sovellusten ajoittamisessa.
MR (Map Reduce): Tämä on Hadoopin perusohjelmointimalli. Sitä käytetään tietojen käsittelemiseen / kyselyyn Hadoop-kehyksessä.
Pesä:
Hive on sovellus, joka ajaa Hadoop-kehystä ja tarjoaa SQL-tyyppisen käyttöliittymän tietojen käsittelemiseen / kyselyyn. Facebook on suunnitellut ja kehittänyt pesän, ennen kuin hänestä tulee osa Apache-Hadoop-hanketta.
Hive suorittaa kyselynsä HQL: llä (pesän kyselykieli). Hivellä on sama rakenne kuin RDBMS: llä ja melkein samoja komentoja voidaan käyttää Hivessä.
Pesä voi tallentaa tietoja ulkoisiin taulukoihin, joten HDFS: n käyttäminen ei ole pakollista. Se tukee myös tiedostomuotoja, kuten ORC-, Avro-, sekvenssitiedosto- ja tekstitiedostoja jne.
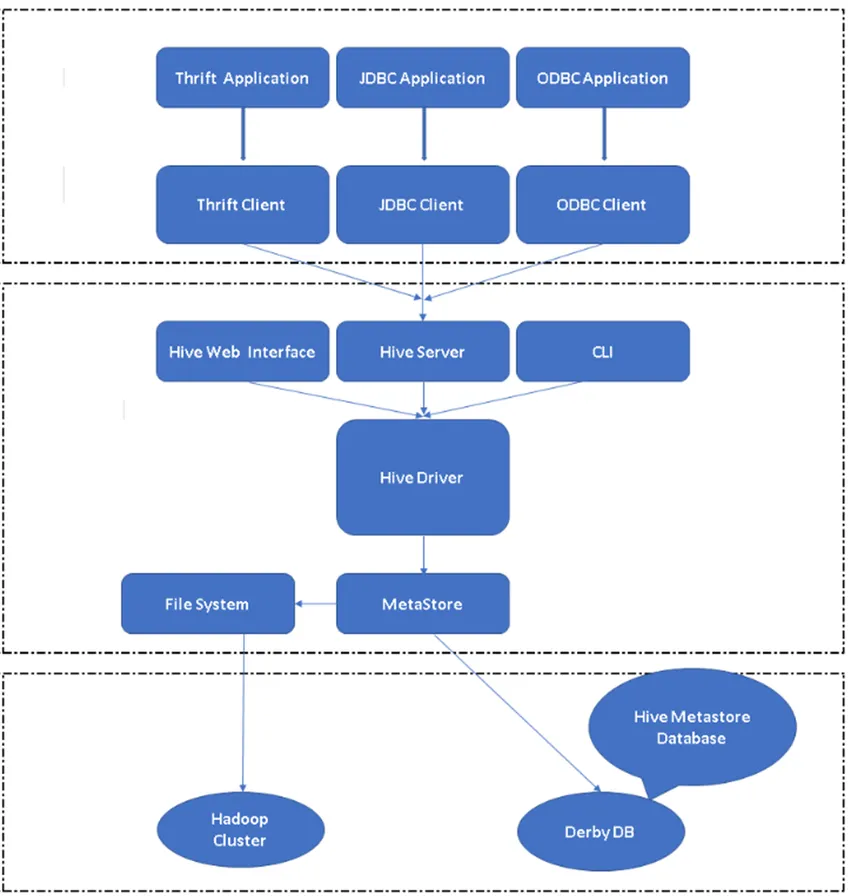
Kuva 2, pesän arkkitehtuuri ja sen tärkeimmät komponentit.
Pesän pääkomponentti:
Hive Clients: Ei vain SQL, Hive tukee myös ohjelmointikieliä, kuten Java, C, Python, käyttämällä erilaisia ohjaimia, kuten ODBC, JDBC ja Thrift. Voidaan kirjoittaa mikä tahansa pesän asiakassovellus muilla kielillä ja voidaan suorittaa pesässä näiden asiakkaiden avulla.
Pesän palvelut: pesän palveluissa komennot ja kyselyt suoritetaan. Hive web -rajapinnalla on viisi alakomponenttia.
- CLI: Hive : n oletus komentoriviliittymä Hive-kyselyjen / -komentojen suorittamiseen.
- Hive-verkkoliittymät: Se on yksinkertainen graafinen käyttöliittymä. Se on vaihtoehto Hive-komentoriville ja sitä käytetään kyselyiden ja komentojen suorittamiseen Hive-sovelluksessa.
- Hive Server: Sitä kutsutaan myös nimellä Apache Thrift. Se on vastuussa komentojen ottamisesta eri komentoriviliittymistä ja lähettämällä kaikki komennot / kyselyt Hivelle. Se myös saa lopullisen tuloksen.
- Apache Hive Driver: Se on vastuussa panosten ottamisesta CLI: n, web-käyttöliittymän, ODBC: n, JDBC: n tai Thrift-rajapintojen kautta asiakkaan toimesta ja siirtävän tiedot metastore-palveluun, jossa kaikki tiedostotiedot on tallennettu.
- Metastore: Metastore on arkisto, joka tallentaa kaikki Hive-metatiedot. Hive'n metatiedot tallentavat tiedot, kuten taulukkorakenteen, osiot ja sarakkeen tyypin jne.…
Pesän varastointi: Se on paikka, jossa varsinainen tehtävä suoritetaan. Kaikki Hivestä peräisin olevat kyselyt suorittivat toimet pesän varastoinnin sisällä.
Head to Head -vertailu Hadoopin ja pesän välillä (Infografia)
Alla on 8 parasta eroa Hadoop vs Hive välillä
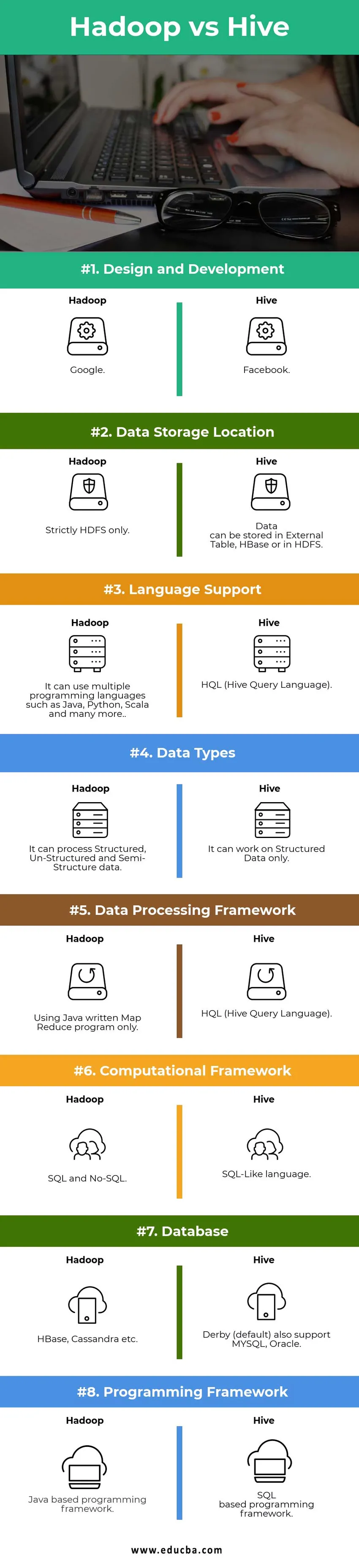
Keskeiset erot Hadoop vs Hive:
Alla on luettelo pisteistä, kuvaile Hadoopin ja Hiven tärkeimmistä eroista:
1) Hadoop on kehys suurten tietojen käsittelemiseen / kyselyyn, kun taas Hive on SQL-pohjainen työkalu, joka rakentaa Hadoopin päälle tietojen käsittelemiseksi.
2) Hive prosessi / kysytä kaikki tiedot HQL: llä (Hive Query Language), joka on SQL-tyyppinen kieli, kun taas Hadoop ymmärtää vain Map Reduce -sovelluksen.
3) Karttavähennys on olennainen osa Hadoopia, Hiven kysely muunnetaan ensin Karttavähennykseksi kuin Hadoop käsittelee tietoja.
4) Hive toimii SQL: n tavoin kuin kysely, kun taas Hadoop ymmärtää sen vain Java-pohjaisella Map Reduce -sovelluksella.
5) Hivessä, aikaisemmin käytettyjä perinteisiä ”relaatiotietokannan” komentoja voidaan käyttää myös suurten tietojen kyselyyn, kun Hadoopissa on kirjoitettava monimutkaisia Map Reduce -ohjelmia Java: n avulla, joka ei ole samanlainen kuin perinteinen Java.
6) pesä voi prosessoida / kyselyä vain jäsennellystä tiedosta, kun taas Hadoop on tarkoitettu kaiken tyyppiselle tiedolle, onko se rakenteellista, jäsentämätöntä tai puolirakennettua.
7) Hive-sovelluksella voidaan käsitellä / hakea tietoja ilman monimutkaista ohjelmointia, kun taas Simple Hadoop -ekosysteemissä täytyy kirjoittaa monimutkainen Java-ohjelma samoille tiedoille.
8) Yhden puolen Hadoop-kehykset tarvitsevat 100 s: n rivin Java-pohjaisen MR-ohjelman valmisteluun, toinen puoli Hadoop Hive: llä voi hakea samoja tietoja 8-10 rivillä HQL: tä.
9) Hivessä on erittäin vaikeaa lisätä yhden kyselyn tulosta toisen kyselyyn, kun taas sama kysely voidaan tehdä helposti käyttämällä Hadoopia MR: n kanssa.
10) Metastoren pitäminen Hadoop-klusterissa ei ole pakollista. Hadoop tallentaa kaikki metatiedot HDFS: ään (Hadoop Distributed File System).
Hadoop vs. pesän vertailutaulukko
| Vertailupisteet | Pesä | Hadoop |
|
Suunnittelu ja kehitys | ||
| Tietojen tallennuspaikka |
Tietoja voidaan tallentaa ulkoiseen Taulukko, HBase tai HDFS. | Vain HDFS. |
| Kielen tuki | HQL (pesän kyselykieli) |
Se voi käyttää useita ohjelmointikieliä, kuten Java, Python, Scala ja monia muita. |
| Tyypit | Se voi toimia vain rakenteellisissa tiedoissa. |
Se voi käsitellä rakenteellisia, rakenteettomia ja puolirakenteisia tietoja. |
| Tietojenkäsittelyjärjestelmä |
HQL (pesän kyselykieli) | Vain Java-kirjoitetun Map Reduce -ohjelman käyttäminen. |
|
Laskennallinen kehys | SQL-tyyppinen kieli. | SQL ja No-SQL. |
| Tietokanta |
Derby (oletus) tukee myös MYSQL, Oracle … | HBase, Cassandra jne. |
| Ohjelmointikehys |
SQL-pohjainen ohjelmointikehys. | Java-pohjainen ohjelmointikehys. |
Johtopäätös - Hadoop vs.
Hadoop ja Hive käytetään molemmat käsittelemään suuria tietoja. Hadoop on kehys, joka tarjoaa alustan muille sovelluksille kysellä / käsitellä suuria tietoja, kun taas Hive on vain SQL-pohjainen sovellus, joka käsittelee tietoja HQL: llä (Hive Query Language)
Hadoop-ohjelmaa voidaan käyttää ilman pesää suurten tietojen käsittelemiseen, kun taas Hive-työkalun käyttäminen ilman Hadoop-sovellusta ei ole helppoa.
Yhteenvetona voidaan todeta, että emme voi verrata Hadoopia ja Hiveä millään tavalla ja millään tavalla. Sekä Hadoop että Hive ovat täysin erilaisia. Molempien tekniikoiden käyttäminen yhdessä voi tehdä Big Data -kyselyprosessista paljon helpompaa ja mukavampaa Big Data -käyttäjille.
Suositellut artikkelit:
Tämä on opas Hadoop vs Hive -sovellukseen, niiden merkitykseen, Head to Head -vertailuun, avainerot, vertailutaulukko ja johtopäätökset. Voit myös katsoa seuraavia artikkeleita saadaksesi lisätietoja -
- Hadoop vs Apache Spark - Mielenkiintoisia asioita, jotka sinun täytyy tietää
- HADOOP vs. RDBMS | Tunne 12 hyödyllistä eroa
- Kuinka suuri tieto muuttaa terveydenhuollon kasvoja
- Apache Hive: n 12 parasta vertailua Apache HBase -sovellukseen (Infographics)
- Upea opas Hadoop vs Spark -sovelluksesta