

Ero Apache Nifin jaApache Sparkin välillä
Kauan asti, kun oli raskas työ, joka piti suorittaa loppuun, ihmiset luottavat hevosiin vetääkseen raskaita tavaroita, ylläpitää nopeutta tai jotain muuta niiden välillä. Kaikki hevoset eivät kuitenkaan sopineet jokaiseen tehtävään. Sama pätee nykyään tekniikkaan. Joka päivä ilmestyvän uuden tekniikan myötä on erittäin tärkeää tuntea niiden todelliset sovellukset. Kaksi tällaista tekniikkaa ovat Apache Nifi ja Apache Spark, ja aiomme tutkia niitä tässä viestissä.
Apache Spark on klusterin laskennallinen avoimen lähdekoodin kehys, jonka tarkoituksena on tarjota käyttöliittymä koko klusterisarjan ohjelmointiin implisiittisen vikatoleranssin ja datan rinnakkaisuuden kanssa. Siinä käytetään RDD: tä (Resilient Distributed Datasets) ja prosessoidaan tiedot diskreisoituneiden virtojen muodossa, jota käytetään edelleen analyyttisiin tarkoituksiin.
Apache Nifi (joka on NiagaraFilesin lyhyt muoto) on toinen ohjelmistoprojekti, jonka tavoitteena on automatisoida tiedonkulku ohjelmistojärjestelmien välillä. Suunnittelu perustuu virtauspohjaiseen ohjelmointimalliin, joka tarjoaa ominaisuuksia, jotka sisältävät toiminnan klusterikyvyllä. Se on helppokäyttöinen, luotettava ja tehokas järjestelmä tietojen käsittelyyn ja jakeluun. Se tukee skaalattavia suunnattuja kuvaajia datan reititykseen, järjestelmän välitykseen ja muunnoslogiikkaan. Keskustelemme molempien aiheiden vertailuihin.
Head to head -vertailu Apache Nifin ja Apache Sparkin (Infographics) välillä
Alla on 9 parasta vertailua Apache Nifi: n ja Apache Sparkin välillä
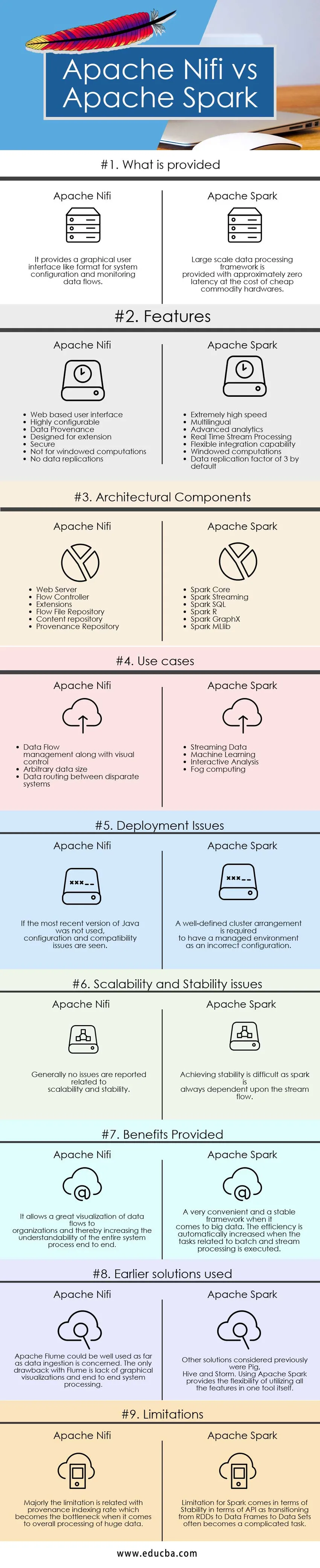
Keskeiset erot Apache Nifi ja Apache Spark välillä
Apache Nifin ja Apache Sparkin väliset erot selitetään alla esitetyissä kohdissa:
- Apache Nifi on tiedonkeruutyökalu, jota käytetään toimittamaan helppokäyttöinen, tehokas ja luotettava järjestelmä, jotta tietojen käsittelystä ja jakamisesta resurssien välillä tulee helppoa, kun taas Apache Spark on erittäin nopea klusterien laskennallinen tekniikka, joka on suunniteltu nopeampaan laskentaan hyödyntämällä tehokkaasti vuorovaikutteisia kyselyitä muistinhallinta- ja stream-prosessointimahdollisuuksissa.
- Apache Nifi toimii itsenäisessä tilassa ja klusteritilassa, kun taas Apache Spark toimii hyvin paikallisessa tai itsenäisessä tilassa, Mesos, Lanka ja muun tyyppiset suuret data klusteritilat.
- Apache Nifi: n ominaisuuksiin kuuluu taattu tietojen toimittaminen, tehokas tietojen puskurointi, priorisoitu jonotus, Flow-erityinen QoS, Data Provenance, Roll-puskurin palautus, Visuaalinen komento ja hallinta, Flow-mallit, Turvallisuus, Rinnakkaisvirtausominaisuudet, kun taas apache-kipinän ominaisuudet sisältävät Salamanopeuden nopeudenkäsittelyominaisuudet, monikieliset, muistilla tapahtuva laskenta, hyödykelaitteistojen tehokas käyttö, Advanced Analytics, tehokas integrointikyky.
- Apache Nifi mahdollistaa järjestelmän paremman luettavuuden ja yleisen ymmärryksen tarjoamalla visualisointiominaisuuksia ja vetämällä ja pudottamalla -ominaisuuksia. Tietojenkulkua voidaan helposti hallita ja hallita tavanomaisilla tekniikoilla ja prosesseilla, kun taas Apache Sparkin tapauksessa tällaisten visualisointien tarkastelemiseksi tarvitaan klusterinhallintajärjestelmä, kuten Ambari. Apache Spark ei sinällään tarjoa visualisointiominaisuuksia ja on ohjelmoinnin kannalta hyvä vain. Se on ylivoimaisesti erittäin kätevä ja vakaa järjestelmä valtavien tietojen käsittelyyn.
- Apache Nifi -rajoitus liittyy siihen, mikä on sen etu. Ainoa vedä ja pudota -ominaisuus rajoittaa sitä, ettei voida skaalata ja antaa tukevuutta integroitaessa sitä muihin komponentteihin ja työkaluihin, kun taas Apache Sparkin tapauksessa ensisijainen rajoitus liittyy laajan hyödykelaitteiston käyttöön ja niiden hallintaan. tulee toisinaan tylsiä tehtävää. Toinen ilmoitettu rajoitus liittyy diskredisoituun suoratoistoon ja ikkuna- tai erävirtaan liittyviin suoratoistoominaisuuksiin, joissa RDD: n muuntaminen tietokehykseksi ja tietojoukkoiksi aiheuttaa epävakauden toisinaan.
Apache Nifi vs Apache Spark -vertailutaulukko
| Vertailun perusteet | Apache Nifi | Apache Spark |
| Mitä tarjotaan | Se tarjoaa graafisen käyttöliittymän, kuten muodon järjestelmän kokoonpanolle ja tietovirtojen seurannalle. | Laajamittaisessa tietojenkäsittelyjärjestelmässä on noin nollalatenssi halvan hyödykelaitteiston kustannuksella. |
| ominaisuudet |
|
|
| Arkkitehtoniset komponentit |
|
|
| Käytä koteloita |
|
|
| Käyttöönotto-ongelmat | Jos viimeisintä Java-versiota ei käytetty, asetuksiin ja yhteensopivuuteen liittyvät ongelmat ilmenevät | Tarvitaan selkeä klusterijärjestely, jotta hallitussa ympäristössä olisi väärä konfiguraatio |
| Skaalautuvuus- ja vakausongelmat | Yleensä skaalautuvuuteen ja vakauteen liittyviä ongelmia ei ilmoiteta | Vakauden saavuttaminen on vaikeaa, koska kipinä riippuu aina virran virtauksesta. |
| Tarjotut edut | Se mahdollistaa organisaatioille suuntautuvien tietovirtojen suuren visualisoinnin ja lisää siten koko järjestelmäprosessin ymmärrettävyyttä päästä päähän | Erittäin kätevä ja vakaa kehys isotietojen suhteen. Tehokkuus kasvaa automaattisesti, kun erä- ja virtakäsittelyyn liittyvät tehtävät suoritetaan. |
| Aikaisemmat ratkaisut | Apache Flume -laitetta voitaisiin käyttää hyvin tietojen syöttämisen kannalta. Ainoa Flume-haittapuoli on graafisten visualisointien ja päästä päähän -järjestelmän prosessoinnin puute | Muita aikaisemmin tarkasteltuja ratkaisuja olivat sika, pesää ja myrsky. Apache Sparkin käyttö tarjoaa joustavuuden käyttää kaikkia ominaisuuksia yhdessä työkalussa. |
| rajoitukset | Rajoitus liittyy lähinnä lähtöpaikan indeksointitasoon, josta tulee pullonkaula, kun kyse on valtavan tiedon kokonaiskäsittelystä. | Spark-rajoitukset koskevat API: n vakautta, koska siirtäminen RDD: stä tietokehyksiin datajoukkoihin tulee usein monimutkaiseksi tehtäväksi. |
Johtopäätös - Apache Nifi vs Apache Spark
Viestin lopuksi voidaan sanoa, että Apache Spark on raskas sotahevonen, kun taas Apache Nifi on ketterä kilpahevonen. Molemmilla on omat edut ja rajoitukset, joita käytetään omalla alueellaan. Sinun on päätettävä oikea työkalu yrityksellesi. Pysy ajan tasalla blogiimme, niin saat uusia artikkeleita, jotka liittyvät uuden datan tekniikkaan.
Suositeltava artikkeli
Tämä on opas Apache Nifi vs. Apache Spark -sovellukseen, niiden merkitykseen, Head to Head -vertailuun, avainerot, vertailutaulukko ja johtopäätökset. Voit myös katsoa seuraavia artikkeleita saadaksesi lisätietoja -
- Apache Hadoop vs Apache Spark | 10 parasta vertailua, jotka sinun on tiedettävä!
- Apache Storm vs Apache Spark - Opi 15 hyödyllistä eroa
- 7 tärkeätä asiaa Apache Sparkista (opas)
- 15 parasta asiaa, jotka sinun on tiedettävä MapReduce vs Spark -sovelluksesta