

Yleiskatsaus klusterointityypeistä
Ymmärretään ennen klusterointityyppien oppimista, mikä on klusterointi ja miksi se on nyt niin tärkeä koneoppimisalalla.
Mikä on klusterointi? Klusterointi on prosessi, jossa algoritmi jakaa datapisteet joukkoon ryhmiä perustuen periaatteeseen, että samanlaiset datapisteet pysyvät lähellä toisiaan ja ne kuuluvat samaan ryhmään.
Miksi se on niin tärkeä nyt? Ymmärtäkäämme, että näkemällä esimerkki esimerkiksi verkossa olevasta vaatekaupasta, ja he haluavat ymmärtää asiakkaitaan paremmin, jotta he voivat tehdä mainostrategiastasi tehokkaamman. Heillä ei ole mahdollista luoda jokaiselle asiakkaalle ainutlaatuista strategiaa, vaan sen sijaan, että he voivat jakaa asiakkaat tiettyyn määrään ryhmiä (aiempien ostojensa perusteella) ja omata erillinen strategia erillisistä ryhmistä. Tämä tehostaa yritystoimintaa, tästä syystä klusterointi on tärkeä teollisuudessa.
Klusterointityypit
Yleisesti ottaen klusterointitekniikat luokitellaan kahteen tyyppiin, jotka ovat kovia ja pehmeitä menetelmiä. Hard-klusterointimenetelmässä kukin datapiste tai havainto kuuluu vain yhteen klusteriin. Pehmeässä klusterointimenetelmässä kukin datapiste ei kuulu kokonaan yhteen klusteriin, vaan se voi olla useamman kuin yhden klusterin jäsen. Sillä on joukko jäsenyyskertoimia, jotka vastaavat todennäköisyyttä olla tietyssä klusterissa.
Tällä hetkellä käytössä on erityyppisiä klusterointimenetelmiä, tässä artikkelissa nähdään joitain tärkeistä, kuten hierarkkinen klusterointi, osiointi klusterointi, sumea klusterointi, tiheyspohjainen klusterointi ja jakelumalli pohjainen klusterointi. Keskustelemme nyt jokaisesta näistä esimerkillä:
1. Osiointi klusterointi
Osiointi Klusterointi on eräänlainen klusterointitekniikka, joka jakaa datajoukon joukkoon ryhmiä. (Esimerkiksi K: n arvo KNN: ssä ja siitä päätetään ennen mallin kouluttamista). Sitä voidaan kutsua myös centroidipohjaiseksi menetelmäksi. Tässä lähestymistavassa klusterin keskipiste (centroidi) on muodostettu siten, että datapisteiden etäisyys kyseisessä klusterissa on pienin laskettaessa muiden klusterin keskikoiden kanssa. Suosituin esimerkki tästä algoritmista on KNN-algoritmi. Näin näyttää osioitu klusterointialgoritmi
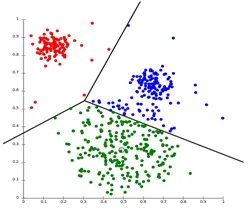
2. Hierarkkinen klusterointi
Hierarkkinen klusterointi on eräänlainen klusterointitekniikka, joka jakaa kyseisen tietojoukon joukkoon klustereita, joissa käyttäjä ei määrittele luotavien klusterien lukumäärää ennen mallin kouluttamista. Tämän tyyppinen klusterointitekniikka tunnetaan myös liitettävyyspohjaisina menetelmin. Tässä menetelmässä tietojoukon yksinkertaista osiointia ei tehdä, kun taas se tarjoaa meille hierarkian klusterien kanssa, jotka sulautuvat toisiinsa tietyn etäisyyden jälkeen. Kun hierarkkinen klusterointi on tehty tietojoukossa, tuloksena on puupohjainen esitys datapisteistä (Dendogram), jotka on jaettu klusteriin. Näin hierarkkinen klusterointi näyttää koulutuksen jälkeen
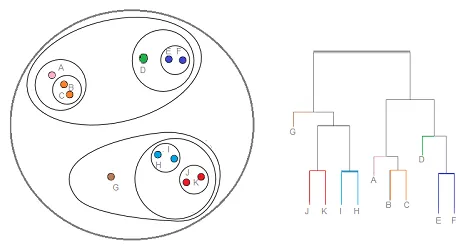
Lähdelinkki: Hierarkkinen klusterointi
Osiointiklusteroinnissa ja hierarkkisessa klusteroinnissa yksi tärkeä ero, jonka voimme huomata, on osiointiryhmittely. Määritämme etukäteen, kuinka monta klusteria haluamme tietojoukon jakautuvan, emmekä määritä tätä arvoa hierarkkisessa klusteroinnissa. .
3. Tiheyspohjainen klusterointi
Tässä klusteroinnissa muodostuu tekniikkaklustereita eriyttämällä erilaisia tiheysalueita erilaisten tiheyksien perusteella datakaaviossa. Tiheyspohjainen alueellinen klusterointi ja sovellus melun kanssa (DBSCAN) on eniten käytetty algoritmi tämän tyyppisissä tekniikoissa. Tämän algoritmin pääideana on, että kussakin klusterin pisteessä tulisi olla minimimäärä pisteitä, jotka sisältävät tietyn säteen läheisyydessä. Toistaiseksi edellä tarkastelluissa klusterointitekniikoissa, jos tarkkaillaan tarkkaan, voimme huomata yhden yhteisen asian kaikissa tekniikoissa, jotka ovat muodostuneiden klustereiden muotoja, jotka ovat joko pallomaisia tai soikeita tai koveran muotoisia. DBSCAN voi muodostaa klustereita eri muodoissa, tämäntyyppinen algoritmi on sopivin, kun aineisto sisältää kohinaa tai poikkeavia. Näin näyttää tiheyspohjainen spatiaalinen klusterointialgoritmi koulutuksen jälkeen.
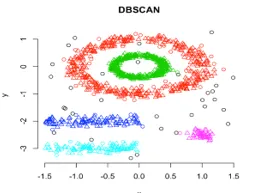
Lähdelinkki: Tiheyspohjainen klusterointi
4. Levitysmallipohjainen klusterointi
Tämän tyyppisessä klusteroinnissa muodostuu tekniikkaklustereita tunnistamalla todennäköisyydellä, että klusterin kaikki datapisteet tulevat samasta jakaumasta (normaali, Gaussin). Suosituin algoritmi tämäntyyppisessä tekniikassa on odotuksen-maksimoinnin (EM) klusterointi Gaussin sekoitusmalleja (GMM) käyttämällä.
Normaalit klusterointitekniikat, kuten hierarkkinen klusterointi ja osioint klusterointi, eivät perustu muodollisiin malleihin, osiintaryhmittelyn KNN tuottaa erilaisia tuloksia erilaisilla K-arvoilla. Koska KNN ja KMN pitävät klusterikeskuksen keskiarvoa, se ei sovellu parhaiten joissakin tapauksissa Gaussin sekoitusmallien kanssa, oletamme, että datapisteet ovat Gaussin jakautuneita, tällä tavalla meillä on kaksi parametria, jotka kuvaavat klusterien keskiarvon muotoa ja keskihajontaa. Tällä tavalla jokaiselle klusterille osoitetaan yksi Gaussin jakauma, jotta saadaan näiden parametrien optimaaliset arvot (keskiarvo ja keskihajonta) käytetään optimointialgoritmia, nimeltään Expectation Maximization. Näin EM-GMM näyttää koulutuksen jälkeen.
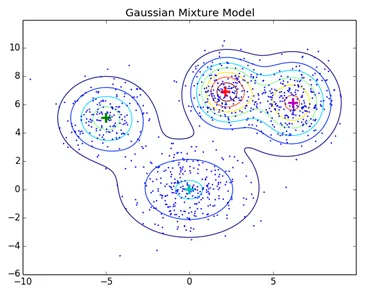
Lähdelinkki: Levitysmallipohjainen klusterointi
5. Sumuinen klusterointi
Kuuluu pehmeiden menetelmien klusterointitekniikoiden haaraan, kun taas kaikki edellä mainitut klusterointitekniikat kuuluvat kovien menetelmien klusterointitekniikoihin. Tämän tyyppisessä klusterointitekniikassa osoitetaan lähellä keskustaa, ehkä osa toista klusteria korkeammalle kuin saman klusterin reunassa olevat kohdat. Tiettyyn klusteriin kuuluvan pisteen todennäköisyys on arvo, joka on välillä 0 - 1. Tämän tyyppisessä tekniikassa suosituin algoritmi on FCM (sumea C-tarkoittaa algoritmia). Tässä klusterin keskikohta lasketaan keskiarvona. kaikista pisteistä, painotettuna niiden todennäköisyyteen kuulua klusteriin.
Johtopäätös - klusterointityypit
Nämä ovat joitain parhaillaan käytössä olevista klusterointitekniikoista, ja tässä artikkelissa olemme käsittäneet yhden suositun algoritmin jokaisessa klusterointitekniikassa. Meidän on valittava käyttämämme tekniikka perustuen tietojoukkoomme ja vaatimuksiin, jotka meidän on täytettävä.
Suositellut artikkelit
Tämä on opas klusterointityypeille. Tässä keskustellaan erityyppisestä klusteroinnista heidän esimerkkinsä kanssa. Saatat myös katsoa seuraavia artikkeleita saadaksesi lisätietoja -
- Hierarkkinen klusterointialgoritmi
- Klusterointi koneoppimisessa
- Koneoppimisen algoritmien tyypit
- Tietoanalyysitekniikoiden tyypit
- Kuinka käyttää ja poistaa taulukon hierarkiaa?
- Täydellinen opas tietotyyppityyppeihin