

Johdatus lineaarisen regression analyysiin
On usein hämmentävää oppia jotain käsitettä, joka on jopa osa päivittäistä elämäämme. Mutta se ei ole ongelma, voimme auttaa ja kehittää itsemme oppimaan jokapäiväisestä toiminnastamme vain analysoimalla asioita ja älä pelkää kysyä kysymyksiä. Miksi hinta vaikuttaa tavaroiden kysyntään, miksi korkotason muutos vaikuttaa rahan tarjontaan. Kaikkiin näihin voidaan vastata yksinkertaisella lähestymistavalla, joka tunnetaan nimellä lineaarinen regressio. Ainoa monimutkaisuus, joka tuntuu käsitellessään lineaarista regressioanalyysiä, on riippuvaisten ja riippumattomien muuttujien tunnistaminen.
Meidän on löydettävä mikä vaikuttaa mihin, ja puolet ongelmasta on ratkaistu. Meidän on selvitettävä, vaikuttaako hinta tai kysyntä toistensa käyttäytymiseen. Kun olemme oppineet tietää mikä on riippumaton muuttuja ja riippuvainen muuttuja, meillä on hyvä mennä analyysiimme. Regressioanalyysiä on saatavana monen tyyppisinä. Tämä analyysi riippuu käytettävissä olevista muuttujista.
Regressioanalyysin 3 tyyppiä
Näillä kolmella regressioanalyysillä on maksimaalinen käyttötapaus todellisessa maailmassa, muuten regressioanalyysejä on yli 15 tyyppiä. Regressioanalyysityypit, joista aiomme keskustella, ovat:
- Lineaarinen regressioanalyysi
- Moninkertainen lineaarinen regressioanalyysi
- Logistinen regressio
Tässä artikkelissa keskitymme yksinkertaiseen lineaarisen regression analyysiin. Tämä analyysi auttaa meitä tunnistamaan riippumattoman tekijän ja riippuvaisen tekijän välisen suhteen. Regression malli auttaa yksinkertaisemmin sanoen havaitsemaan, kuinka riippumattoman tekijän muutokset vaikuttavat riippuvaiseen tekijään. Tämä malli auttaa meitä monin tavoin, kuten:
- Se on yksinkertainen ja tehokas tilastollinen malli
- Se auttaa meitä tekemään ennusteita ja ennusteita
- Se auttaa meitä tekemään paremman liiketoimintapäätöksen
- Se auttaa meitä analysoimaan tulokset ja korjaamaan virheet
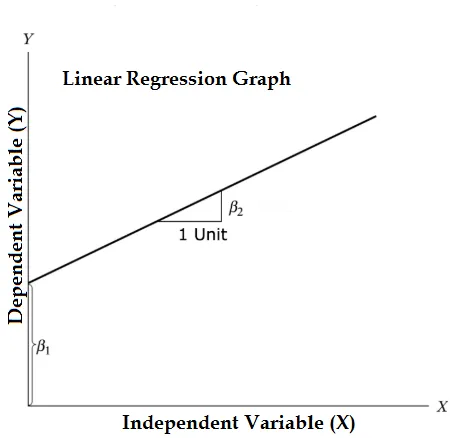
Lineaarisen regression yhtälö ja jaa se osiin
Y = β1 + β2X + ϵ
- Missä β1 matemaattisessa terminologiassa, joka tunnetaan leikkauksena, ja β2 matemaattisessa terminologiassa, jota kutsutaan kaltevuudeksi. Ne tunnetaan myös regressiokertoimina. ϵ on virhetermi, se on osa Y: tä, jota regressiomalli ei pysty selittämään.
- Y on riippuvainen muuttuja (muut termit, joita käytetään vaihdettavasti riippuvaisille muuttujille, ovat vastemuuttuja, regressi, mitattu muuttuja, havaittu muuttuja, vastaava muuttuja, selitetty muuttuja, tulosmuuttuja, kokeellinen muuttuja ja / tai lähtömuuttuja).
- X on riippumaton muuttuja (regressorit, hallittu muuttuja, manipuloitu muuttuja, selittävä muuttuja, valotuksen muuttuja ja / tai syöttömuuttuja).
Ongelma: Jotta ymmärtäisimme, mikä on lineaarinen regressioanalyysi, otamme ”Autot” -joukon, joka tulee oletuksena R-hakemistoihin. Tässä tietoaineistossa on 50 havaintoa (periaatteessa rivejä) ja 2 muuttujaa (sarake). Sarakkeiden nimet ovat “Dist” ja “Speed”. Täällä meidän täytyy nähdä vaikutus nopeusmuuttujien muutoksen aiheuttamiin etäisyysmuuttujiin. Tietojen rakenteen näkemiseksi voimme suorittaa koodin Str (tietojoukko). Tämä koodi auttaa meitä ymmärtämään tietojoukon rakenteen. Nämä toiminnot auttavat meitä tekemään parempia päätöksiä, koska mielessämme on parempi kuva tietojoukon rakenteesta. Tämä koodi auttaa meitä tunnistamaan tietotyyppien tyypit.
Koodi:

Samoin tietoaineiston tilastollisten tarkistuspisteiden tarkistamiseen voidaan käyttää koodia Yhteenveto (autot). Tämä koodi tarjoaa keskimääräisen, mediaanin, tietojoukon kantaman, jota tutkija voi käyttää ongelmaa käsitellessään.
lähtö:
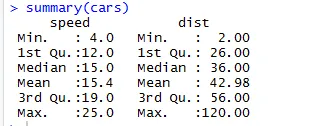
Täällä näemme jokaisen tietojoukkomme muuttujan tilastollisen tuotoksen.
Tietoaineistojen graafinen esitys
Graafisen esityksen tyypit, joita tässä käsitellään, ovat ja miksi:
- Hajontapiirros: Graafin avulla voimme nähdä, mihin suuntaan lineaarinen regressiomalli kulkee, onko olemassa mitään vahvaa näyttöä mallimme todistamiseksi vai ei.
- Box-tontti: Auttaa meitä löytämään poikkeamia.
- Tiheyskäyrä: Auta meitä ymmärtämään riippumattoman muuttujan jakauma, tässä tapauksessa riippumaton muuttuja on ”Nopeus”.
Graafisen esityksen edut
Tässä ovat seuraavat edut:
- Helppo ymmärtää
- Auttaa meitä tekemään nopean päätöksen
- Vertaileva analyysi
- Vähemmän vaivaa ja aikaa
1. Hajontakaavio: Se auttaa visualisoimaan riippumattoman muuttujan ja riippuvaisen muuttujan väliset suhteet.
Koodi:

lähtö:
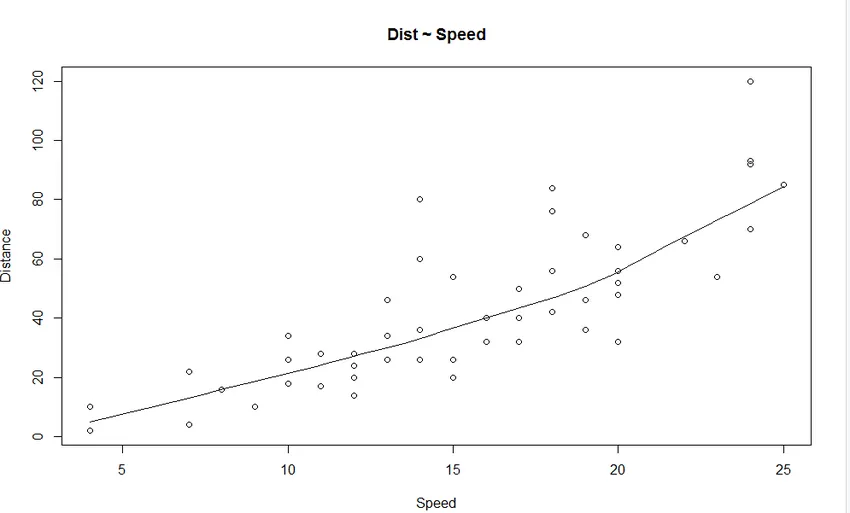
Graafista voidaan nähdä lineaarisesti kasvava suhde riippuvaisen muuttujan (etäisyys) ja riippumattoman muuttujan (nopeus) välillä.
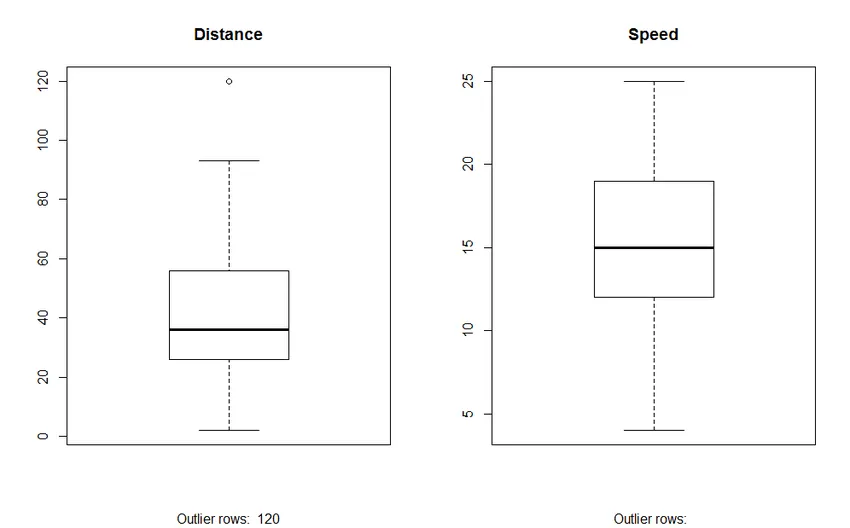
2. Box Plot: Box plot auttaa meitä tunnistamaan poikkeamat tietojoukossa. Box-tontin käytön edut ovat:
- Graafinen näyttö muuttujien sijainnista ja leviämisestä.
- Se auttaa meitä ymmärtämään tietojen vinoutumista ja symmetriaa.
Koodi:

lähtö:
3. Tiheyspiirros (jakauman normaalisuuden tarkistamiseksi)
Koodi:
 lähtö:
lähtö:
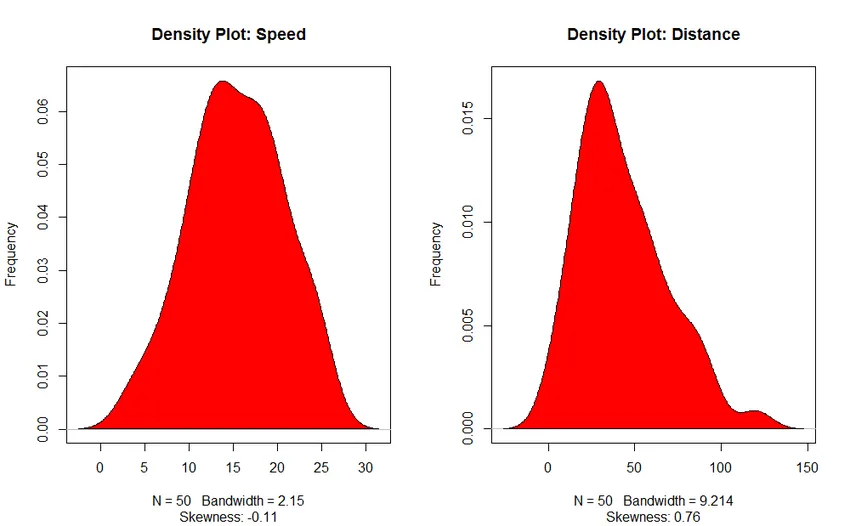
Korrelaatioanalyysi
Tämä analyysi auttaa meitä löytämään muuttujien välisen suhteen. Korrelaatioanalyysejä on pääasiassa kuusi.
- Positiivinen korrelaatio (0, 01–0, 99)
- Negatiivinen korrelaatio (-0, 99 - -0, 01)
- Ei korrelaatiota
- Täydellinen korrelaatio
- Vahva korrelaatio (arvo lähempänä ± 0, 99)
- Heikko korrelaatio (arvo lähempänä arvoa 0)
Hajotuskaavio auttaa meitä tunnistamaan, minkä tyyppisillä korrelaatioaineistoilla on niiden joukossa, ja koodi korrelaation löytämiseksi on

lähtö:
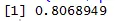
Tässä nopeuden ja etäisyyden välillä on vahva positiivinen korrelaatio, mikä tarkoittaa, että heillä on suora yhteys keskenään.
Lineaarinen regressiomalli
Tämä on analyysin ydinkomponentti, aiemmin yritimme vain testata asioita, onko meillä oleva tietojoukko riittävän looginen tällaisen analyysin suorittamiseksi vai ei. Toiminto, jota aiomme käyttää, on lm (). Tämä toiminto sisältää kaksi elementtiä, jotka ovat kaava ja data. Ennen kuin määrität sen, mikä muuttuja on riippuvainen tai riippumaton, meidän on oltava siitä erittäin varmoja, koska koko kaava riippuu siitä.
Kaava näyttää tältä,
Lineaarinen regressio <- lm (riippuva muuttuja ~ itsenäinen muuttuja, data = päivämäärä.kehys)
Koodi:

lähtö:
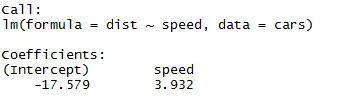
Kuten artikkelin yllä olevasta segmentistä voidaan muistaa, lineaarisen regression yhtälö on:
Y = β1 + β2X + ϵ
Nyt sovitamme tietoihin, jotka saimme yllä olevasta koodista tässä yhtälössä.
dist = −17.579 + 3.932 ∗ nopeus
Vain lineaarisen regression yhtälön löytäminen ei riitä, meidän on tarkistettava myös sen tilastollinen merkitsevyys. Tätä varten meidän on läpäistävä koodi “Yhteenveto” lineaarisella regressiomallillamme.
Koodi:

lähtö:

Mallin tilastollisen merkitsevyyden tarkistamiseen on useita tapoja, tässä käytetään P-arvomenetelmää. Voimme pitää mallia tilastollisesti sopivana, kun P-arvo on pienempi kuin ennalta määritetty tilastollinen merkitsevä taso, joka on ihannetapauksessa 0, 05. Voimme nähdä yhteenvetoraportissa (lineaarinen_regressio), että P-arvo on alle 0, 05-tason, joten voimme päätellä, että mallimme on tilastollisesti merkitsevä. Kun olemme varmoja mallistamme, voimme käyttää tietojoukkoamme ennustamaan asioita.
Suositellut artikkelit
Tämä on opas lineaarisen regression analyysiin. Tässä keskustellaan kolmesta lineaarisen regression analyysin tyypistä, tietoaineistojen graafisesta esityksestä ja sen eduista sekä lineaarisen regression malleista. Voit myös käydä läpi muiden aiheeseen liittyvien artikkeleidemme saadaksesi lisätietoja-
- Regressiokaava
- Regressiotestaus
- Lineaarinen regressio R: ssä
- Tietoanalyysitekniikoiden tyypit
- Mikä on regressioanalyysi?
- Regression tärkeimmät erot vs. luokittelu
- Lineaarisen regression kuuden tärkeimmät erot vs. logistisen regression