
Johdatus tietojenkäsittelytieteen elinkaareen
Data Science: n elinkaari kiertää koneoppimisen ja muiden analyyttisten menetelmien avulla tuotettaessa tietoa oivalluksia ja ennusteita liiketoiminnan tavoitteen saavuttamiseksi. Koko prosessi sisältää useita vaiheita, kuten tietojen puhdistaminen, valmistelu, mallintaminen, mallin arviointi jne. Se on pitkä prosessi, ja saattaa viedä useita kuukausia. Joten on erittäin tärkeää, että meillä on yleinen rakenne, jota noudatetaan jokaisessa käsiteltävänä olevassa ongelmassa. Kaikkien analyyttisten ongelmien ratkaisemisessa yleisesti tunnustettua rakennetta kutsutaan datan louhinnan toimialaväliseksi standardiprosessiksi tai CRISP-DM-kehykseksi.
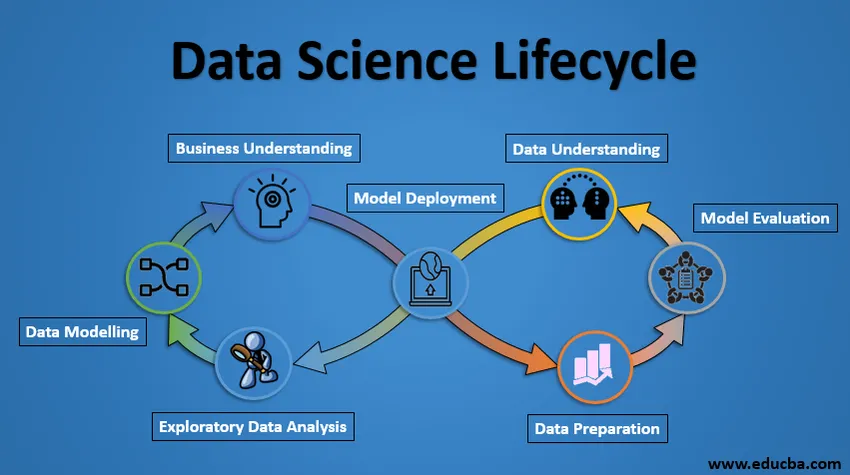
Tietotieteen elinkaari
Alla on Data Science -projektin elinkaari.
1. Liiketoiminnan ymmärtäminen
Koko sykli pyörii liiketoimintatavoitteen ympärillä. Mitä ratkaista, jos sinulla ei ole tarkkaa ongelmaa? On erittäin tärkeää ymmärtää liiketoiminnan tavoite selkeästi, koska se on analyysiin lopullinen tavoite. Vain asianmukaisen ymmärtämisen jälkeen voimme asettaa analyysin erityisen tavoitteen, joka on tahdissa liiketoiminnan tavoitteen kanssa. Sinun on tiedettävä, haluaako asiakas vähentää luottotappioita vai haluaako hän ennustaa hyödykkeen hinnan jne.
2. Tietojen ymmärtäminen
Yritystoiminnan ymmärtämisen jälkeen seuraava askel on datan ymmärtäminen. Tähän sisältyy kaikkien käytettävissä olevien tietojen kerääminen. Täällä sinun on tehtävä tiivistä yhteistyötä yritysryhmän kanssa, koska he ovat tosiasiassa tietoisia siitä, mitä tietoja on läsnä, mitä tietoja voidaan käyttää tähän liiketoimintaongelmaan ja muuta tietoa. Tässä vaiheessa kuvataan tiedot, niiden rakenne, relevanssi ja tietotyyppi. Tutustu tietoihin graafisten kaavioiden avulla. Pohjimmiltaan uutta tietoa, jonka voit saada tiedoista, vain tutkimalla tietoja.
3. Tietojen valmistelu
Seuraavaksi tulee tietojen valmisteluvaihe. Tähän sisältyy vaiheita, kuten asiaankuuluvan tiedon valitseminen, datan integrointi yhdistämällä tietojoukot, puhdistamalla se, käsittelemällä puuttuvat arvot joko poistamalla tai sisällyttämällä ne, käsittelemällä virheellisiä tietoja poistamalla ne, tarkista myös, onko poikkeajia laatikkokohtaina ja käsittele niitä . Rakentamalla uutta tietoa, johda uusia ominaisuuksia olemassa olevista. Alusta tiedot haluttuun rakenteeseen, poista ei-toivotut sarakkeet ja ominaisuudet. Tietojen valmistelu on aikaavievin, mutta väitetysti tärkein vaihe koko elinkaaren ajan. Mallisi on yhtä hyvä kuin tietosi.
4. Tutkimusaineistoanalyysi
Tässä vaiheessa saadaan käsitys ratkaisusta ja siihen vaikuttavista tekijöistä ennen varsinaisen mallin rakentamista. Tietojen jakautumista ominaisuuden eri muuttujien välillä tutkitaan graafisesti pylväsdiagrammeilla. Eri ominaisuuksien väliset suhteet kaadetaan graafisten esitysten, kuten sirontakaavioiden ja lämpökarttojen avulla. Monia muita datan visualisointitekniikoita käytetään laajasti kaikkien ominaisuuksien tutkimiseen erikseen ja yhdistämällä niitä muihin ominaisuuksiin.
5. Tietojen mallintaminen
Datan mallintaminen on tietoanalyysin ydin. Malli vie valmistetun datan syötteenä ja tuottaa halutun tulosteen. Tämä vaihe sisältää sopivan tyyppisen mallin valitsemisen, onko ongelma luokitteluongelma vai regressio-ongelma vai klusterointiongelma. Kun olet valinnut malliperheen, sen perheen erilaisista algoritmeista, meidän on valittava huolellisesti algoritmit niiden toteuttamiseksi ja toteuttamiseksi. Meidän on viritettävä kunkin mallin hyperparametrit halutun suorituskyvyn saavuttamiseksi. Meidän on myös varmistettava, että suorituskyvyn ja yleistävyyden välillä on oikea tasapaino. Emme halua mallin oppivan tietoja ja toimivan heikosti uusissa tiedoissa.
6. Mallin arviointi
Täällä malli arvioidaan sen tarkistamiseksi, onko se valmis ottamaan käyttöön. Malli testataan näkymättömällä datalla, arvioidaan huolellisesti harkittujen arviointimittarien avulla. Meidän on myös varmistettava, että malli on todellisuuden mukainen. Jos emme saa tyydyttävää tulosta arvioinnissa, meidän on toistettava koko mallintamisprosessi uudelleen, kunnes haluttu mittatason taso on saavutettu. Kaikkien tietoteknisten ratkaisujen, koneoppimismallien, kuten ihmisenkin, tulisi kehittyä, niiden tulisi kyetä parantamaan itseään uudella tiedolla, sopeutumaan uuteen arviointitietoon. Voimme rakentaa useita malleja tietylle ilmiölle, mutta monet niistä voivat olla puutteellisia. Malliarviointi auttaa meitä valitsemaan ja rakentamaan täydellisen mallin.
7. Mallin käyttöönotto
Tarkan arvioinnin jälkeen malli otetaan lopulta käyttöön halutussa muodossa ja kanavalla. Tämä on viimeinen vaihe tietojen tieteen elinkaaren aikana. Jokainen yllä selitetty datatieteiden elinkaaren vaihe on tutkittava huolellisesti. Jos jokin vaihe suoritetaan väärin, se vaikuttaa seuraavaan vaiheeseen ja koko työ menee hukkaan. Esimerkiksi, jos tietoja ei kerätä oikein, menetät tiedot etkä rakenna täydellistä mallia. Jos tietoja ei puhdisteta kunnolla, malli ei toimi. Jos mallia ei arvioida kunnolla, se epäonnistuu todellisessa maailmassa. Jokaiseen vaiheeseen tulisi kiinnittää asianmukaista huomiota, aikaa ja vaivaa liiketoiminnan ymmärtämisestä mallin käyttöönottoon asti.
Suositellut artikkelit
Tämä on opas tietojen tieteen elinkaareen. Tässä keskustellaan datatieteiden elinkaaren yleiskatsauksesta ja vaiheista, jotka muodostavat datan tieteen elinkaaren. Voit myös käydä liittyvien artikkeleidemme läpi saadaksesi lisätietoja
- Johdatus datatieteen algoritmeihin
- Data Science vs. Ohjelmistosuunnittelu | 8 parasta hyödyllistä vertailua
- Tietojenkäsittelytekniikoiden erotyypit
- Tietotekniset taidot tyypeillä