
Johdanto hierarkkiseen klusterointiin
- Äskettäin yksi asiakkaista pyysi tiimiamme tuottamaan luettelon segmentteistä, joilla on tärkeysjärjestys asiakkaidensa sisällä, jotta he voisivat suunnata heille franchising-tuotteen äskettäin lanseerattuihin tuotteisiin. Asiakkaiden segmentointi osittain klusteroinnin avulla (k-keinot, c-sumea) ei selvästikään tuo esiin tärkeysjärjestystä, missä hierarkkinen klusterointi tulee kuvaan.
- Hierarkkinen klusterointi on tietojen erottaminen eri ryhmiin perustuen joihinkin klustereihin kutsuttuihin samankaltaisuusmittauksiin, joiden pääasiallisena tavoitteena on rakentaa hierarkia klustereiden kesken. Periaatteessa kyse on ilman ohjausta ja ominaisuuksien valitseminen samankaltaisuuden mittaamiseksi on sovelluskohtainen.
Tietohierarkian klusteri
- Agglomeratiivinen klusterointi
- Erottava klusterointi
Otetaan esimerkki tiedoista, pisteistä, jotka 5 opiskelija on hankkinut ryhmitelläkseen tulevaa kilpailua varten.
| Opiskelija | Merkit |
| 10 | |
| B | 7 |
| C | 28 |
| D | 20 |
| E | 35s |
1. Agglomeratiivinen klusterointi
- Aluksi katsomme kunkin yksittäisen pisteen / elementin painoa klusterina ja yhdistämme samanlaisia pisteitä / elementtejä uuden klusterin muodostamiseksi uudelle tasolle, kunnes meillä on jäljellä yksi klusteri on alhaalta ylöspäin suuntautuva lähestymistapa.
- Yksittäinen kytkentä ja täydellinen kytkentä ovat kaksi suosittua esimerkkiä agglomeratiivisesta klusteroinnista. Muu kuin keskimääräinen kytkentä ja Centroid-kytkentä. Yhdessä kytkennässä yhdistämme jokaisessa vaiheessa kaksi klusteria, joiden kahta lähintä jäsentä on pienin etäisyys. Täydellisessä kytkennässä yhdistämme pienimmän etäisyyden jäsenet, jotka tarjoavat pienimmän maksimiparin etäisyyden.
- Läheisyysmatriisi, se on hierarkkisen klusteroinnin suorittamisen ydin, joka antaa etäisyyden kunkin pisteen välillä.
- Tehdään läheisyysmatriisi taulukossa annettuihin tietoihimme, koska laskemme kunkin pisteen välistä etäisyyttä muiden pisteiden kanssa, se on asymmetrinen matriisi, jonka muoto on n × n, tapauksessamme 5 × 5 matriisit.
Suosittu menetelmä etäisyyslaskelmiin ovat:
- Euklidian etäisyys (neliö)
dist((x, y), (a, b)) = √(x - a)² + (y - b)²
- Manhattanin etäisyys
dist((x, y), (a, b)) =|x−c|+|y−d|
Euklidista etäisyyttä käytetään yleisimmin, käytämme samaa täällä, ja meillä on monimutkainen kytkentä.
| Student (klusterit) | B | C | D | E | |
| 0 | 3 | 18 | 10 | 25 | |
| B | 3 | 0 | 21 | 13 | 28 |
| C | 18 | 21 | 0 | 8 | 7 |
| D | 10 | 13 | 8 | 0 | 15 |
| E | 25 | 28 | 7 | 15 | 0 |
Läheisyysmatriisin diagonaalielementit ovat aina 0, koska samalla pisteellä olevan pisteen välinen etäisyys on aina 0, joten diagonaalielementit on vapautettu ryhmittelystä.
Tässä iteraatiossa 1 pienin etäisyys on 3, joten yhdistämme A ja B klusteriksi, muodostamme taas uuden läheisyysmatriisin klusterilla (A, B) ottamalla (A, B) klusteripisteeksi 10, ts. Enintään ( 7, 10), joten vasta muodostettu läheisyysmatriisi olisi
| klusterit | (A, B) | C | D | E |
| (A, B) | 0 | 18 | 10 | 25 |
| C | 18 | 0 | 8 | 7 |
| D | 10 | 8 | 0 | 15 |
| E | 25 | 7 | 15 | 0 |
Ieraatiossa 2, 7 on minimietäisyys, joten yhdistämällä C ja E muodostaen uuden klusterin (C, E), toistamme iteraatiossa 1 noudatetun prosessin, kunnes päädymme yksittäiseen klusteriin, tässä lopetamme iteraation 4.
Koko prosessi on kuvattu alla olevassa kuvassa:
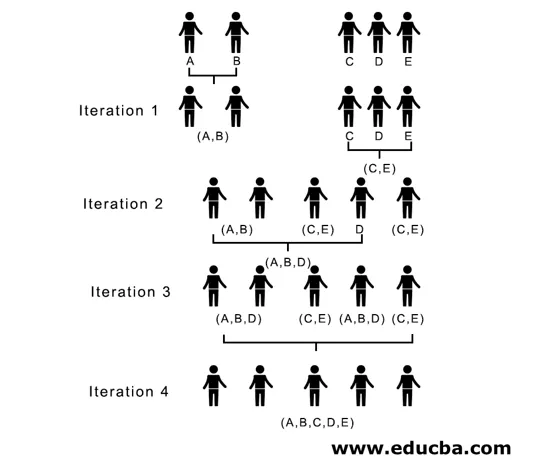
(A, B, D) ja (D, E) ovat 2 ryppyä, jotka muodostuvat iteraatiossa 3, viimeisessä iteraatiossa, jonka voimme nähdä, meillä on yksi klusteri.
2. Erottava klusterointi
Ensinnäkin, pidämme kaikkia pisteitä yhtenä klusterina ja erotamme ne kauimpana etäisyydellä, kunnes loppumme yksittäisillä pisteillä erillisinä klusterina (ei välttämättä voida pysähtyä keskelle, riippuu vähimmäismäärästä elementtejä, joita haluamme kussakin klusterissa) kussakin vaiheessa. Se on vastakohta taajautuvalle klusteroinnille ja se on ylhäältä alas suuntautuva lähestymistapa. Jakautuva klusterointi on tapa toistuva k tarkoittaa klusterointia.
Valinta agglomeratiivisen ja jakavan klusterin välillä riippuu jälleen sovelluksesta, mutta harvat huomioon otettavat seikat ovat:
- Jakaminen on monimutkaisempaa kuin agglomeratiivinen klusterointi.
- Jakautuva klusterointi on tehokkaampaa, jos emme luo täydellistä hierarkiaa yksittäisiin tietopisteisiin.
- Agglomeratiivinen klusterointi tekee päätöksen harkitsemalla paikallisia taustoja ottamatta huomioon alun perin globaaleja malleja, joita ei voida kumota.
Hierarkkisen klusteroinnin visualisointi
Dendogram on erittäin hyödyllinen tapa hierarkkisen klusteroinnin visualisoimiseksi, mikä auttaa liiketoimintaa. Dendogrammit ovat puumaisia rakenteita, jotka tallentavat yhdistämis- ja halkeamisjärjestyksen, jossa pystysuora viiva edustaa klustereiden välistä etäisyyttä, pystysuorien viivojen välistä etäisyyttä ja klustereiden välistä etäisyyttä on suoraan verrannollinen eli toisinpäin, mitä enemmän etäisyyttä klusterit todennäköisesti eroavat.
Voimme käyttää dendogrammia klustereiden määrän päättämiseen, piirrä vain viiva, joka leikkaa dendogrammin pisin pystysuora viiva. Useita pystysuoria viivoja, jotka on leikattu, on tarkasteltavien klusterien lukumäärä.
Alla on esimerkki dendogrammista.
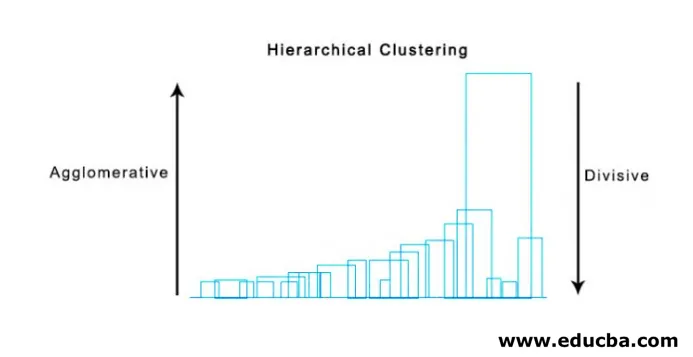
On melko yksinkertaisia ja suoria python-paketteja, ja sen toiminnot suorittavat hierarkkisia klusterointeja ja piirtää dendogrammeja.
- Hierarkia skipyistä.
- Cluster.hierarchy.dendogram visualisointia varten.
Yleiset skenaariot, joissa käytetään hierarkkista klusterointia
- Asiakassegmentointi tuote- tai palvelumarkkinointiin.
- Kaupunkisuunnittelu rakennusten / palveluiden / rakennusten rakennuspaikkojen tunnistamiseksi.
- Sosiaalisen verkoston analyysi, esimerkiksi, tunnistaa kaikki MS Dhoni -fanit mainostaakseen hänen biopaikkansa.
Hierarkkisen klusteroinnin edut
Edut on annettu alla:
- Kun kyseessä on osittainen klusterointi, kuten k-välineet, klusterien lukumäärän tulisi olla tiedossa ennen klusterointia, mikä ei ole mahdollista käytännöllisissä sovelluksissa, kun taas hierarkkisessa klusteroinnissa ei vaadita aiempaa tietoa klusterien lukumäärästä.
- Hierarkkinen klusterointi tuottaa hierarkian, ts. Rakenteen, joka on informatiivisempi kuin osittaisen klusteroinnin palauttamien tasaisten klusterien jäsentämätön joukko.
- Hierarkkinen klusterointi on helppo toteuttaa.
- Tuo esiin tulokset useimmissa skenaarioissa.
johtopäätös
Tyyppisellä klusteroinnilla on suuri ero datan esittämisessä. Hierarkkinen klusterointi on informatiivisempaa ja helppo analysoida, ja se on parempi kuin osittainen klusterointi. Ja se liittyy usein lämpökarttoihin. Unohtamatta samankaltaisuuden tai erilaisuuden laskemiseksi valittuja ominaisuuksia vaikuttaa pääosin sekä klustereihin että hierarkiaan.
Suositellut artikkelit
Tämä on opas hierarkkiseen klusterointiin. Tässä keskustellaan hierarkkisen klusteroinnin ja sen yleisten skenaarioiden johdannosta, eduista, joissa hierarkkista klusterointia käytetään. Voit myös käydä läpi muiden ehdotettujen artikkeleidemme saadaksesi lisätietoja -
- Rypytysalgoritmi
- Klusterointi koneoppimisessa
- Hierarkkinen ryhmittely R: ssä
- Klusterointimenetelmät
- Kuinka poistaa hierarkia taulukosta?