
Määritelmä Keskimääräinen muutosalgoritmi
Keskimääräinen siirtymän algoritmi kuuluu ohjaamattomaan oppimiseen, joka luokitellaan klusterointialgoritmiksi. Mean Shift -algoritmin ideologia on, että se osoittaa iteratiivisesti datapisteitä klustereihin siirtymällä kohti pistettä, jolla on korkein tiheyspiste (tila). Keskimääräinen siirtymän taustalla oleva logiikka perustuu käsitteeseen ytimen tiheyden estimointi, jota kutsutaan KDE: ksi.
Keskimääräinen muutosalgoritmin ryhmittely
Fukunagan ja Hostetlerin havaitsemat valvontamattomat oppimistekniikat klusterien löytämiseksi:
- Mean Shift tunnetaan myös moodinhakualgoritmina, joka osoittaa datapisteet klusterille tavalla siirtämällä datapisteitä kohti tiheästi aluetta. Suurinta datapisteiden tiheyttä kutsutaan malliksi alueella. Mean Shift -algoritmissa on sovelluksia, joita käytetään laajalti tietokoneen näkemyksen ja kuvan segmentoinnin alalla.
- KDE on menetelmä arvioida datapisteiden jakautumista. Se toimii sijoittamalla ydin jokaiseen datapisteeseen. Matematiikan ydin on painotusfunktio, joka käyttää painoja yksittäisille datapisteille. Kaikkien ytimien lisääminen luo todennäköisyyden.
Ydintoiminnon on täytettävä seuraavat ehdot:
- Ensimmäinen vaatimus on varmistaa, että ytimen tiheysestimaatti on normalisoitu.
- Toinen vaatimus on, että KDE liittyy hyvin avaruuden symmetriaan.
Kaksi suosittua ytimen toimintoa
Alla on kaksi suosittua ytimen funktiota, joita siinä käytetään:
- Litteä ydin
- Gaussin ydin
- Käytetyn ytimen parametrin perusteella tuloksena oleva tiheysfunktio vaihtelee. Jos ydinparametria ei mainita, Gaussian-ydin kutsutaan oletuksena. KDE käyttää todennäköisyystiheysfunktion käsitettä, joka auttaa löytämään tiedonjaon paikalliset maksimit. Algoritmi toimii saattamalla datapisteet houkuttelemaan toisiaan sallien datapisteiden kohti tiheyden aluetta.
- Tietopisteet, jotka yrittävät lähentyä kohti paikallisia maksimiä, ovat samassa klusteriryhmässä. Toisin kuin K-Means-klusterointialgoritmi, Mean Shift -algoritmin lähtö ei riipu oletuksista datapisteen muodosta ja klustereiden lukumäärästä. Klusterien lukumäärä määritetään algoritmin avulla suhteessa dataan.
- Jotta voimme toteuttaa Mean Shift -algoritmin, käytämme python-pakettia SKlearn.
Keskimääräisen muutosalgoritmin toteutus
Alla on algoritmin toteutus:
Esimerkki # 1
Perustuu Sklearn-oppaan keskimääräisen siirtymän klusterointialgoritmiin. Ensimmäinen katkelma toteuttaa keskimääräisen siirtymän algoritmin 2-ulotteisen tietojoukon klusterien löytämiseksi. Keskimääräisen siirtymän algoritmin toteuttamiseen käytetyt paketit.
Koodi:
fromcluster importMeanShift, estimate_bandwidth
from sklearn.datasets.samples_generator import make_blobs as mb
importpyplot as plt
fromitertools import cycle as cy
Yksi tärkeä asia on huomioida, että käytämme sklearnin make_blobs-kirjastoa tuottamaan datapisteitä, jotka on keskitetty kolmeen sijaintiin. Jotta voimme soveltaa keskimääräisen siirtymän algoritmia generoituihin pisteisiin, meidän on asetettava kaistanleveys, joka edustaa pituuden välistä vuorovaikutusta. Sklearn's Libraryssä on sisäänrakennetut toiminnot kaistanleveyden arvioimiseksi.
Koodi:
#Sample data points
cen = ((1, .75), (-.75, -1), (1, -1)) x_train, _ = mb(n_samples=10000, centers= cen, cluster_std=0.6)
# Bandwidth estimation using in-built function
est_bandwidth = estimate_bandwidth(x_train, quantile=.1,
n_samples=500)
mean_shift = MeanShift(bandwidth= est_bandwidth, bin_seeding=True)
fit(x_train)
ms_labels = mean_shift.labels_
c_centers = ms_labels.cluster_centers_
n_clusters_ = ms_labels.max()+1
# Plot result
figure(1)
clf()
colors = cy('bgrcmykbgrcmykbgrcmykbgrcmyk')
fori, each inzip(range(n_clusters_), colors):
my_members = labels == i
cluster_center = c_centers(k) plot(x_train(my_members, 0), x_train(my_members, 1), each + '.')
plot(cluster_center(0), cluster_center(1),
'o', markerfacecolor=each,
markeredgecolor='k', markersize=14)
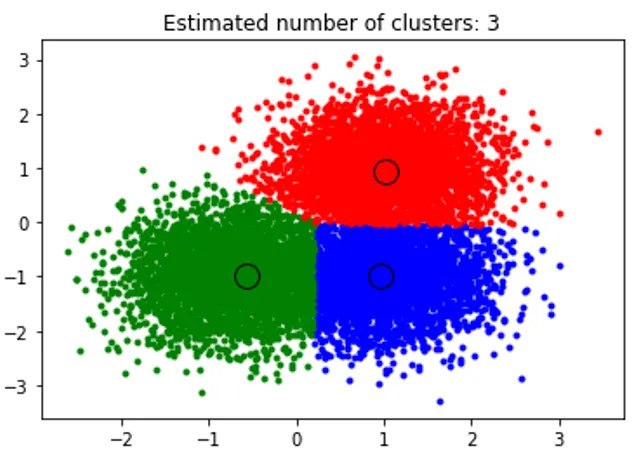
title('Estimated cluster numbers: %d'% n_clusters_)
show()
Yllä oleva katkelma suorittaa klusteroinnin ja löydetty algoritmi keskittyy jokaisessa luomassamme möykkyssä. Voimme nähdä, että alla olevan katkelman piirtämä kuva näyttää keskimääräisen siirtymän algoritmin, joka kykenee tunnistamaan ajoajassa tarvittavien klusterien määrän ja selvittämään sopivan kaistanleveyden, joka edustaa vuorovaikutuksen pituutta.
lähtö:
Esimerkki 2
Perustuu kuvan segmentointiin tietokonevisioissa. Toisessa katkelmassa tutkitaan kuinka syvässä oppimisessa käytetty keskimääräinen siirtymäalgoritmi suorittaa värillisen kuvan segmentointi. Käytämme keskimääräistä muutosalgoritmia tunnistaaksesi alueelliset klusterit. Aikaisemmassa katkelmassa käytimme 2-D-tietojoukkoa, kun taas tässä esimerkissä tutkitaan 3D-tilaa. Kuvan pikseliä käsitellään datapisteinä (r, g, b). Kuva on muunnettava matriisimuotoon siten, että se kukin pikseli edustaa datapistettä kuvassa, johon menemme segmenttiin. Väriarvojen klusterointi avaruuteen palauttaa klusterisarjat, joissa klusterin pikselit ovat samanlaisia kuin RGB-tila. Keskimääräisen siirtymän algoritmin toteuttamiseen käytetyt paketit:
Koodi:
importnumpy as np
fromcluster importMeanShift, estimate_bandwidth
fromdatasets.samples_generator importmake_blobs
importpyplot as plt
fromitertools import cycle
fromPIL import Image
Katkelman alapuolella, jotta alkuperäinen kuva voidaan segmentoida:
#Segmentation of Color Image
img = Image.open('Sample.jpg.webp')
img = np.array(img)
#Need to convert image into feature array based
flatten_img=np.reshape(img, (-1, 3))
#bandwidth estimation
est_bandwidth = estimate_bandwidth(flatten_img,
quantile=.2, n_samples=500)
mean_shift = MeanShift(est_bandwidth, bin_seeding=True)
fit(flatten_img)
labels= mean_shift.labels_
# Plot image vs segmented image
figure(2)
subplot(1, 1, 1)
imshow(img)
axis('off')
subplot(1, 1, 2)
imshow(np.reshape(labels, (854, 1224)))
axis('off')
Luodun kuvan mukaan tämä lähestymistapa kuvien muotojen tunnistamiseen ja alueellisten klustereiden määrittämiseen voidaan tehdä tehokkaasti ilman minkäänlaista kuvankäsittelyä.
lähtö:


Edut ja sovellukset tarkoittavat vaihto-algoritmia
Alla on keskialgoritmin edut ja soveltaminen:
- Sitä käytetään laajalti tietokoneen vision ratkaisemiseen, missä sitä käytetään kuvan segmentointiin.
- Tietopisteiden ryhmittely reaaliajassa mainitsematta klusterien lukumäärää.
- Suorittaa hyvin kuvan segmentoinnissa ja videoseurannassa.
- Vahvempi poikkeaviin.
Plussit keskimääräisen siirtymän algoritmista
Alla on ammattilaisten keskimääräisen siirtymän algoritmi:
- Algoritmin lähtö on riippumaton alustuksista.
- Menettely on tehokas, koska sillä on vain yksi parametri - Kaistanleveys.
- Ei oletuksia tietoklustereiden lukumäärästä ja muodosta.
- Sen suorituskyky on parempi kuin K-Means Clusteringin.
Huonot keskimääräisen muutoksen algoritmi
Alla on keskimääräisen siirtymän algoritmin haitat:
- Kallis suurille ominaisuuksille.
- Verrattuna K-Means-klusterointiin, se on erittäin hidasta.
- Algoritmin lähtö riippuu parametrin kaistanleveydestä.
- Tulos riippuu ikkunan koosta.
johtopäätös
Vaikka se on suoraviivainen lähestymistapa, jota käytettiin ensisijaisesti kuvan segmentointiin, klusterointiin liittyvien ongelmien ratkaisemiseksi. Se on suhteellisen hitaampi kuin K-Means ja se on laskennallisesti kallis.
Suositellut artikkelit
Tämä on opas keskimääräiseen muutosalgoritmiin. Tässä keskustellaan ongelmista, jotka liittyvät kuvan segmentointiin, klusterointiin, etuihin ja kahteen ytimen toimintaan. Voit myös käydä läpi muiden aiheeseen liittyvien artikkeleidemme saadaksesi lisätietoja-
- K- tarkoittaa ryhmittelyalgoritmia
- KNN-algoritmi R: ssä
- Mikä on geneettinen algoritmi?
- Ytimen menetelmät
- Ytimen menetelmät koneoppimisessa
- C ++ -algoritmin yksityiskohtainen selitys