
Johdanto pesääryhmään
Ryhmittele nimellä, kuten nimestä voi päätellä, se ryhmittää tietueen, joka täyttää tietyt vaatimukset. Tässä artikkelissa tarkastellaan HIVEn ryhmää. Vanhoissa RDBMS-järjestelmissä, kuten MySQL, SQL jne., Ryhmittely on yksi vanhimmista käytetyistä lauseista. Nyt se on löytänyt paikkansa samalla tavalla tiedostopohjaisessa tallennuksessa, joka tunnetaan nimellä HIVE.
Tiedämme, että pesä on ylittänyt monet vanhat RDBMS-järjestelmät käsitellessään valtavia tietoja ilman, että myyjät käyttäisivät penniäkään tietokantojen ja palvelimien ylläpitämiseen. Meidän täytyy vain määrittää HDFS käsittelemään pesää. Yleensä siirrymme taulukoihin, koska loppukäyttäjä pystyy tulkitsemaan sen rakennetta ja tiedustelemaan, koska tiedostot ovat heille kömpelöitä. Mutta meidän piti tehdä tämä maksamalla myyjille palvelimien tarjoaminen ja tietojen ylläpitäminen taulukkojen muodossa. Joten Hive tarjoaa kustannustehokkaan mekanismin, jossa hyödynnetään tiedostopohjaisia järjestelmiä (tapa, jolla pesä tallentaa tietojaan) sekä taulukoita (taulukkorakenne loppukäyttäjille kyselyä varten).
Ryhmittele
Ryhmittelemällä käyttää tietoja luokittelemaan Hive-taulukon määriteltyjä sarakkeita. Ajattele esimerkiksi, että sinulla on taulukko väestölaskentatiedoilla jokaisesta kaupungista kaikista osavaltioista, joissa kaupungin nimi ja osavaltion nimi ovat yksi sarakkeista. Nyt kyselyssä, jos ryhmittelemme valtioiden mukaan, kaikki tietyn valtion eri kaupunkien tiedot ryhmitellään toisiinsa ja tiedot voidaan helposti visualisoida paremmin nyt ennen tapaa, jolla ryhmää sovellettiin.
Syntettipesäryhmän syntaksi
Ryhmän lausekkeen mukainen yleinen syntaksi on seuraava:
SELECT (ALL | DISTINCT) select_expr, select_expr, …
FROM table_reference
(WHERE where_condition) (GROUP BY col_list) (HAVING having_condition) (ORDER BY col_list)) (LIMIT number);
tai yksinkertaisempia kyselyjä varten,
from Group By
Select department, count(*) from the university.college Group By department;
Tässä osastolla tarkoitetaan yhtä yliopistotietokannassa olevaa korkeakoulujen taulukon sarakkeita, ja sen arvo on erilainen laitoksilla, kuten taiteet, matematiikka, tekniikka jne. Katsotaanpa nyt esimerkkejä ryhmien esittelystä.
Olen luonut mallipöydässä deck_of_cards osoittamaan ryhmää. Sen luomistaulukon lause on seuraava:
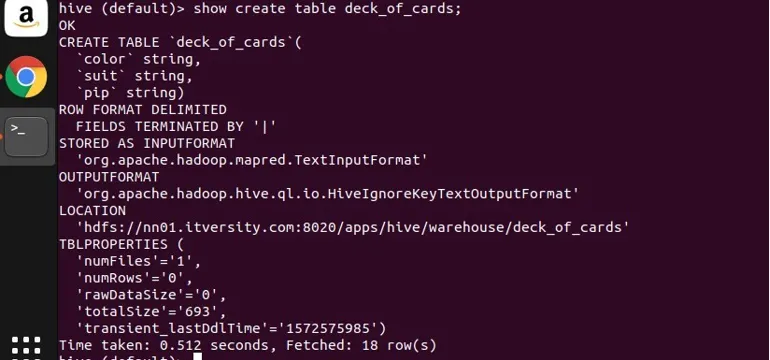
näet ylhäältä, että siinä on kolme merkkijono saraketta väri, puku ja pip. Saanen kirjoittaa kyselyn ryhmitellä tiedot värin mukaan ja saada niiden lukumäärä.
select color, count(*) from deck_of_cards group by color;
Hive periaatteessa vie yllä olevan kyselyn muuntaaksesi sen kartan pienentämisohjelmaksi luomalla vastaavan Java-koodin ja jar-tiedoston ja suorittamalla sen sitten. Tämä prosessi voi viedä vähän aikaa, mutta se voi ehdottomasti käsitellä suuria tietoja verrattuna perinteiseen RDBMS: ään. Katso alla oleva kuvakaappaus yksityiskohtaisella lokilla yllä olevan kyselyn suorittamiseksi.
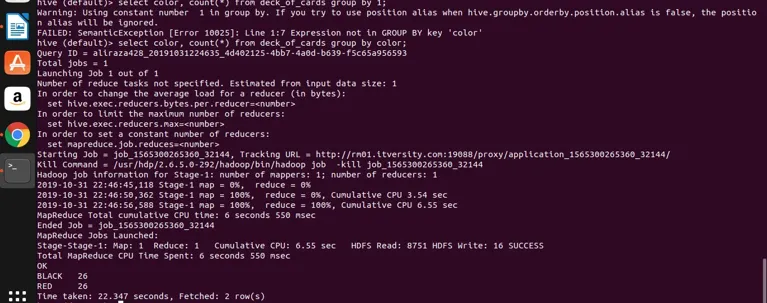
voit nähdä, että MUSTA on 26 ja PUNAINEN on 26.
Soveltakaamme nyt ryhmittelyä kahteen sarakkeeseen (väri ja puku sekä ryhmämäärä) ja katso tulos alla.
Select color, suit, count(*) from deck_of_cards group by color, suit
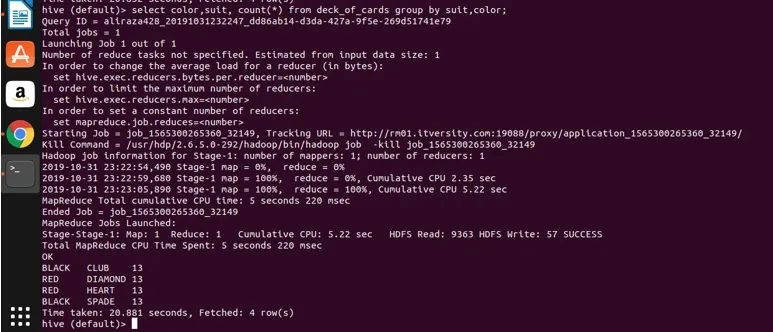
Pohjimmiltaan Club-, Spade-yläpuolella on neljä erillistä ryhmää, joiden väri on musta ja Diamond ja sydän ovat punaisia.
Tuloksen tallentaminen ryhmästä syystä toiseen taulukkoon
Myös pesä, kuten mikä tahansa muu RDBMS, tarjoaa ominaisuuden lisätä tietoja taulukon lauseiden luomiseen. Tarkastellaan tuloksen tallentamista valitusta lausekkeesta ryhmää käyttämällä toiseen taulukkoon. Annan käyttää itse yllä olevaa kyselyä, jossa olen käyttänyt kahta saraketta ryhmässä.
create table cards_group_by
as
select color, suit, count(*) from deck_of_cards
group by color, suit;
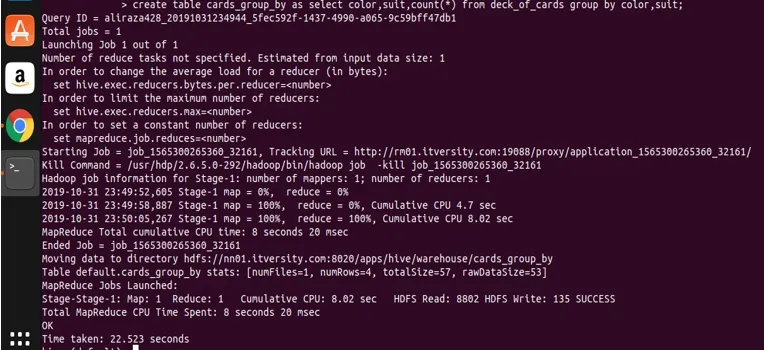
anna meidän nyt tehdä kysely luodusta taulukosta nähdäksesi ja vahvistaaksesi tiedot.

Rajoitetaan nyt ryhmän tulosta käyttämällä lauseketta. Kuten yleisessä syntaksissa esitetään, voimme soveltaa rajoitusta ryhmään käyttämällä. Käytän tässä ordser_items-taulukkoa ja sen rakenne on seuraava kuvailevasta lauseesta.
hive (retail_db_ali)> describe order_items;
OK
order_item_id int
order_item_order_id int
order_item_product_id int
order_item_quantity tinyint
order_item_subtotal float
order_item_product_price float
Time taken: 0.387 seconds, Fetched: 6 row(s)
select order_item_id, order_item_order_id from order_items group by order_item_id, order_item_order_id having order_item_order_id=5;
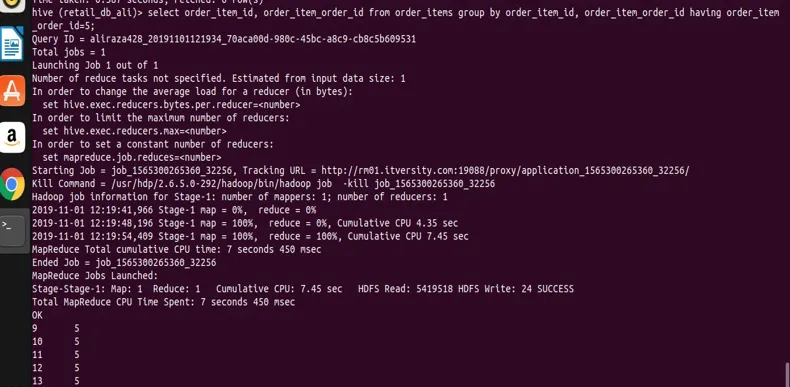
voit nähdä tuloksesta kuvakaappauksen, että meillä on tietueita vain arvoilla order_item_order_id 5.
Ryhmä: Yhdessä tapauksen kanssa
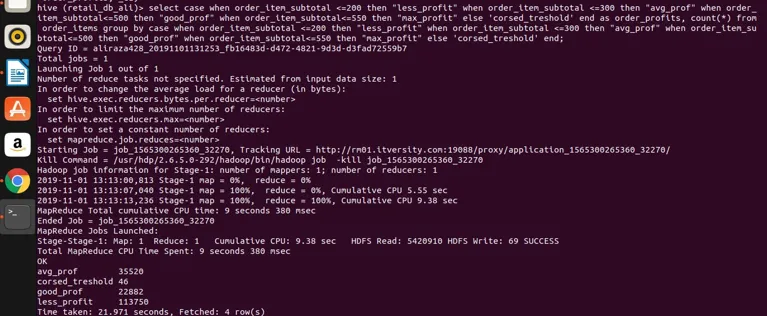
Katsokaamme nyt vähän monimutkaisia kyselyjä, jotka sisältävät CASE-lauseita ryhmän kanssa. Sovellamme tätä order_items-taulukkoon. Alla näemme, että voimme luokitella ei-kasvavat sarakkeet, joihin emme voi soveltaa ryhmää lausekkeen avulla suoraan.
Select
case
when order_item_subtotal <=200 then "less_profit"
when order_item_subtotal <=300 then "avg_prof"
when order_item_subtotal<=500 then "good_prof"
when order_item_subtotal<=550 then "max_profit"
else 'corsed_treshold'
end
as order_profits,
count(*) from order_items
group by
case
when order_item_subtotal <=200 then "less_profit"
when order_item_subtotal <=300 then "avg_prof"
when order_item_subtotal<=500 then "good_prof"
when order_item_subtotal<=550 then "max_profit"
else 'corsed_treshold'
end;
suorittakaamme se tulossa tulosten saavuttamiseksi
Johtopäätös - pesän ryhmä
joten voimme nähdä, että olemme ryhmitelleet order_item_subtotal neljään eri luokkaan (jos huomaat, että order_item_subtotal on yhdistämätön sarake ja suoraa ryhmää ei voida soveltaa siihen), ja olemme ryhmitelleet ne yhteen ja saaneet myös heidän laskennan arvot, jotka täyttävät valitussa lausekkeessa määritellyn alueen. Tässä yksinkertainen sääntö, jos sarake ei ole merkitsevä ja valittu lauseke on monimutkainen, niin mitä tahansa valitun lausekkeen siellä on, jonka tulisi myös olla läsnä ryhmässä lauselausekkeella. Joten olemme nähneet, kuinka kuuluisa lauseke RDBMS-lausekeryhmä voidaan myös soveltaa pesään ilman rajoituksia. Sitä voidaan käyttää yksinkertaisiin valittuihin lausekkeisiin. Yhdistä ja suodata lausekkeita, liitä lausekkeita ja myös monimutkaisia CASE-lausekkeita.
Suositellut artikkelit
Tämä on opas Hive Group By: lle. Tässä keskustellaan ryhmästä syntaksin avulla esimerkkejä pesäryhmästä erilaisin ehdoin ja toteutuksella. Voit myös katsoa seuraavia artikkeleita saadaksesi lisätietoja -
- Liittyy Hiveen
- Mikä on pesä?
- Pesän arkkitehtuuri
- Pesän toiminto
- Pesän tilauksen tekijä
- Pesän asennus
- MySQL: n kuusi suosittua liittymistyyppiä ja esimerkkejä