
Ero pesän ja HBase: n välillä
Apache Hive ja HBase ovat Hadoop-pohjaisia suuria tietotekniikoita. He molemmat käyttivät tietoja kyselyihin. Hive ja HBase toimivat Hadoopin päällä ja ne eroavat toisistaan toiminnallisuudestaan. Hive on karttaa vähentävä SQL-murre, kun taas HBase tukee vain MapReducea. HBase tallentaa tietoja avain / arvo tai sarakeperheparien muodossa, kun taas Hive ei tallenna tietoja.
Head to Head erot pesän ja HBasen välillä (Infografia)
Alla on kahdeksan tärkeintä eroa vastaan Hive ja HBase
Keskeiset erot pesän ja HBaasin välillä
- Hbase on ACID-yhteensopiva, kun taas Hive ei.
- Hive tukee osiointi- ja suodatusehtoja päivämäärämuodon perusteella, kun taas HBase tukee automatisoitua osiointia.
- Hive ei tue päivityslausekkeita, kun taas HBase tukee niitä.
- Hbase on nopeampi verrattuna pesään tietojen noutamisessa.
- Hiveä käytetään prosessoidun datan prosessointiin, kun taas HBase, koska se ei ole skeemavapaa, pystyy käsittelemään kaikenlaista dataa.
- Hbase on erittäin (vaakasuunnassa) skaalautuva verrattuna Hiveen.
- Hive analysoi HDFS: n tiedot SQL-kyselyjen tuella ja sitten muuntaa ne mapiksi ja vähentää työpaikkoja. Hbase-ohjelmassa, koska se on reaaliaikainen suoratoisto, se suorittaa operaatiot tietokantaan suoraan osioimalla taulukoihin ja sarakeperheisiin.
- tullessaan tietokyselyyn, pesä käyttää Hive-nimelliskuoria, joka antaa komentoja, kun taas HBase, koska se on tietokanta, käytämme komentoa tietojen käsittelyyn HBase-tietokannassa.
- Käytäksesi pesän kuorea käytämme komentoa pesä. Antamisen jälkeen se näyttää pesältä. .HBase-sovelluksessa annamme yksinkertaisesti käytön nimellä HBase.
Hive vs HBase -vertailutaulukko
| Vertailun perusteet | Pesä | Hbase |
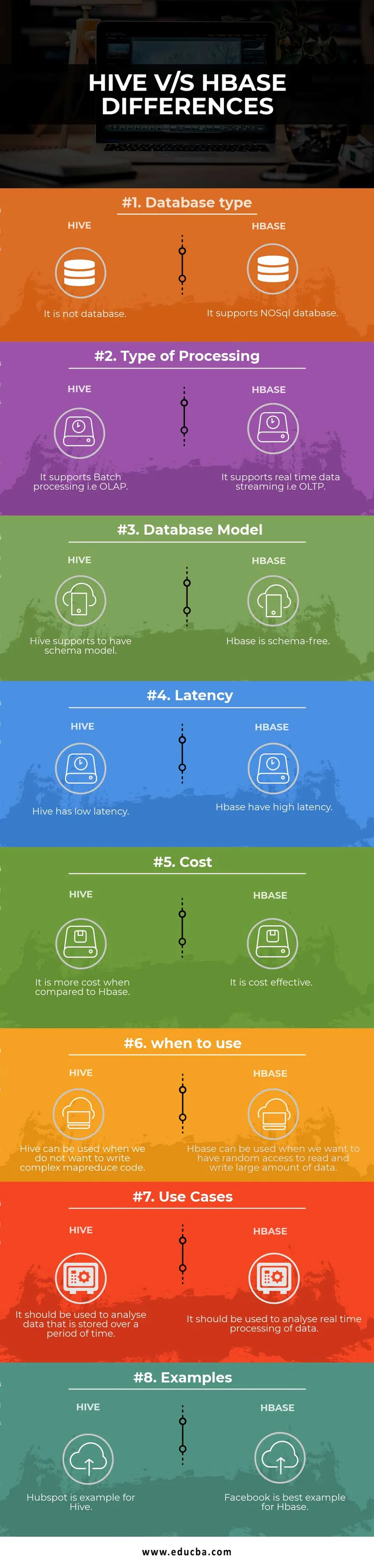
| Tietokantatyyppi | Se ei ole tietokanta | Se tukee NoSQL-tietokantaa |
| Käsittelyn tyyppi | Se tukee eräkäsittelyä eli OLAP: ta | Se tukee reaaliaikaista tiedonsiirtoa eli OLTP: tä |
| Tietokantamalli | Pesä tukee olla mallimallia | Hbase on kaavamaton |
| Viive | Pesällä on pieni viive | Hbase-latenssi on korkea |
| Kustannus | Se on kalliimpaa verrattuna HBaseen | Se on kustannustehokas |
| milloin käyttää | Pesää voidaan käyttää, kun emme halua kirjoittaa monimutkaista MapReduce-koodia | HBase-tietokantaa voidaan käyttää, kun haluamme saada satunnaisen pääsyn lukemaan ja kirjoittamaan suurta määrää dataa |
| Käytä koteloita | Sitä tulisi käyttää tietyn ajanjakson aikana tallennettujen tietojen analysointiin | Sitä tulisi käyttää tietojen reaaliaikaisen käsittelyn analysointiin. |
| esimerkit | Hubspot on esimerkki Hivelle | Facebook on paras esimerkki Hbase-palvelulle |
Eroa koodauksessa pesän ja HBaasin välillä
Keskustelemme nyt Hiveen ja HBase: n peruseroista koodauksessa.
| Vertailun perusteet | Pesä | Hbase |
| Tietokannan luominen | Luo tietokanta (jos sitä ei ole) tietokannan nimi; | Koska Hbase on tietokanta, meidän ei tarvitse luoda erityistä tietokantaa |
| Pudota tietokanta | DROP-TIETOKANTA (JOS TÄYTETYT) TIETOKANNAN NIMI (RAJOITETTU TAI KASKAADI); | NA |
| Taulukon luominen | Luo (väliaikainen tai ulkoinen) taulukko (jos sitä ei ole) PÖYTÄNIMI ((sarakkeen nimen datatyyppi (kommentti-sarake-kommentti), ….)) (Kommenttitaulukko_kommentti) (Rivimuoto rivimuoto) (Tallennettuna tiedostomuodona) | Luo '', '' |
| Taulukon muuttaminen | Vaihda taulukon nimi nimeä uusi nimi
Vaihtoehtoisen taulukon nimi DROP (COLUMN) -sarakkeen nimi Vaihtoehtoinen taulukko name ADD COLUMNS (col-spec (, col-spec ..)) ALTERTABLE name CHANGE sarakkeen nimi uusi nimi uusi tyyppi Vaihtoehtoisen taulukon nimi Vaihda sarakkeet (col-spec (, col-spec ..)) | VAIHDA 'PÖYTÄ-NIMI', NIMI => 'PÄÄNNIMI', VERSIOT => |
| Pöydän poistaminen käytöstä | NA | poista 'TABLE-NAME' -> käytöstä määritetyn taulukon nimen poistamiseksi käytöstä
Disable_all 'r *' -> poistaaksesi kaikki taulukot, jotka vastaavat säännöllistä lauseketta |
| Pöydän ottaminen käyttöön | NA | ota käyttöön PÖYTÄ-NIMI |
| Pudota taulukko | Pudota taulukko, jos olemassa taulukon nimi | Jos haluamme pudottaa taulukon, meidän on ensin poistettava se käytöstä
poista 'taulukon nimi' käytöstä pudota 'taulukon nimi' Samoin voimme käyttää Disable_all ja drop_all poistaaksesi taulukot, jotka vastaavat määritettyä säännöllistä lauseketta. |
| Tietokantojen luettelointi | Näytä tietokannat; | NA |
| Taulukoiden luettelointi tietokannasta | Näytä pöydät; | lista |
| Kuvata taulukon kaavio | kuvaile taulukon nimeä; | kuvaa 'taulukon nimi' |
Integrointi pesän ja HBase
- Asenna ja määritä Hive.
- Asenna ja määritä HBase.
- Sekä pesän että HBase: n integroimiseksi käytämme STEAGE HANDLERSia Hivessä.
- Storage Handlers on SERDE: n, InputFormatin ja OutputFormatin yhdistelmä, joka hyväksyy kaikki ulkoiset kokonaisuudet taulukkona Hivessä.
- Joten tämä ominaisuus auttaa käyttäjää antamaan SQL-kyselyitä riippumatta siitä, onko taulukko Hadoopissa vai NOSQL-pohjaisessa tietokannassa, kuten HBase, MongoDB, Cassandra, Amazon DynamoDB.
- Nyt tarkastelemme yhtä esimerkkiä pesän yhdistämisestä HBaseen HiveStorageHandlerin avulla:
- Ensinnäkin meidän on luotava Hbase-taulukko komennon avulla.
luo 'Opiskelija', 'henkilökohtainen tieto', 'osastoinfo'
-> Henkilökohtaiset tiedot ja osastotiedot luovat kaksi erilaista sarakeperhettä Opiskelija-taulukkoon.
- Meidän on lisättävä joitain tietoja Opiskelijoiden taulukkoon. Esimerkki, kuten alla mainitaan.
laita 'opiskelija', 'sid01', 'henkilökohtainen tieto: nimi', 'Ram'
laita 'opiskelija', 'sid01', 'henkilökohtainen tieto: mailid', ' '
laita 'opiskelija', 'sid01', 'deptinfo: deptname', 'Java'
laita 'Opiskelija', 'sid01', 'deptinfo: joinyear', '1994'
-> Samoin voimme luoda tietoja sid02: lle, sid03: lle …
- Nyt meidän on luotava Hive-taulukko osoittava Hive-taulukko.
- Jokaiselle Hbase-sarakkeelle luomme yhden erityisen taulukon sarakkeelle Hivessä. Tässä tapauksessa luomme 2 taulukkoa Hivessä.
create external table student_hbase(sid String, name String, mailid String)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler with serdeproperties("hbase.columns.mapping"=":key, personalinfo:name, personalinfo:mailid")
tblproperties("hbase.table.name"="student");
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
-> Samoin meidän on luotava pesässä yksityiskohtainen tietotaulukko.
- Nyt voimme kirjoittaa SQL-kyselyn pesässä, kuten alla on mainittu.
select * from student_hbase;
Tällä tavoin voimme integroida Hive HBaseen.
Johtopäätös - pesää vastaan HBase
Kuten keskusteltiin, ne molemmat ovat erilaisia tekniikoita, jotka tarjoavat erilaisia toimintoja, joissa Hive toimii käyttämällä SQL-kieltä, ja sitä voidaan kutsua myös nimellä HQL ja HBase käyttämään avain-arvopareja tietojen analysoimiseksi. Hive ja HBase toimivat paremmin, jos ne yhdistetään, koska pesällä on pieni viive ja ne voivat käsitellä valtavan määrän tietoja, mutta eivät pysty ylläpitämään ajantasaista tietoa. HBase ei tue tietojen analysointia, mutta tukee rivitason päivityksiä suurella määrällä datasta.
Suositeltava artikkeli
Tämä on opas kohtiin Hive vs HBase, niiden merkitys, Head to Head -vertailu, keskeiset erot, vertailutaulukko ja johtopäätökset. Voit myös katsoa seuraavia artikkeleita saadaksesi lisätietoja -
- Apache Pig vs Apache Hive - 12 suosituinta eroa
- Selvitä 7 parasta eroa Hadoopin ja HBasen välillä
- Apache Hive: n 12 parasta vertailua Apache HBase -sovellukseen (Infographics)
- Hadoop vs. pesää - selvitä parhaat erot