

Johdanto tiedonlouhintaan
Tämä on tiedon louhintamenetelmä, jota käytetään sijoittamaan dataelementit samanlaisiin ryhmiin. Ryhmä on menettely, jolla dataobjektit jaetaan alaluokkiin. Klusteroinnin laatu riippuu käytetystä menetelmästä. Klusterointia kutsutaan myös datasegmentiksi, koska suuret tietoryhmät jaetaan samankaltaisuuksiltaan.
Mitä klusterointi on tiedon louhinnassa?
Klusterointi on tiettyjen objektien ryhmittely niiden ominaisuuksien ja yhtäläisyyksien perusteella. Tiedon louhinnan osalta tämä menetelmä jakaa tiedot, jotka sopivat parhaiten haluttuun analyysiin, käyttämällä erityistä liittymisalgoritmia. Tämän analyysin avulla objekti ei voi olla osa tai tiukasti osa klusteria, jota kutsutaan tämän tyyppiseksi kovaksi osioitumiseksi. Sileät osiot viittaavat kuitenkin siihen, että jokainen samassa asteessa oleva objekti kuuluu klusteriin. Tarkempia jakoja voidaan luoda kuten useiden klusterien objekteja, yksi klusteri voidaan pakottaa osallistumaan tai jopa ryhmäsuhteisiin voidaan rakentaa hierarkkisia puita. Tämä tiedostojärjestelmä voidaan asettaa paikoilleen eri tavoin erilaisten mallien perusteella. Nämä erilliset algoritmit koskevat kaikkia malleja ja erottavat niiden ominaisuudet sekä tulokset. Hyvä klusterointialgoritmi pystyy tunnistamaan klusterin riippumatta klusterin muodosta. Klusterointialgoritmissa on 3 perusvaihetta, jotka esitetään alla
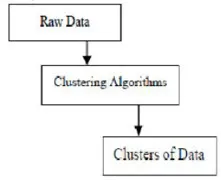
Klusterointialgoritmit tiedonlouhinnassa
Äskettäin kuvattujen klusterimallien mukaan monia klustereita voidaan käyttää osioimaan tiedot datajoukkoon. On sanottava, että jokaisella menetelmällä on omat edut ja haitat. Algoritmin valinta riippuu tietojoukon ominaisuuksista ja luonteesta.
Tietojen louhinnan klusterointimenetelmät voidaan näyttää alla
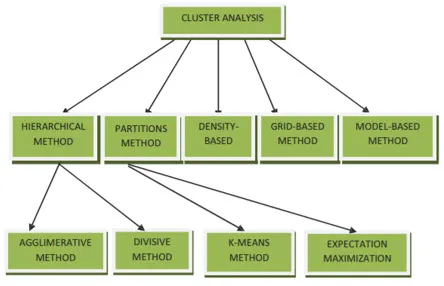
- Osiointiperusteinen menetelmä
- Tiheyspohjainen menetelmä
- Centroidipohjainen menetelmä
- Hierarkkinen menetelmä
- Ruudukkoon perustuva menetelmä
- Malliperusteinen menetelmä
1. Osiointiperusteinen menetelmä
Osioalgoritmi jakaa tiedot moniin osajoukkoihin.
Oletetaan, että osiointialgoritmi rakentaa osion tiedoista, koska k ja n ovat esineitä, jotka ovat tietokannassa. Siksi jokainen osio esitetään muodossa k ≤ n.
Tämä antaa käsityksen siitä, että tiedot luokitellaan k-ryhmiin, jotka voidaan näyttää alla
Kuvio 1 näyttää alkuperäiset kohdat klusteroinnissa

Kuvio 2 osoittaa osio klusteroinnin algoritmin soveltamisen jälkeen
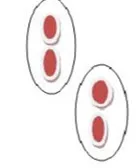
Tämä osoittaa, että jokaisella ryhmällä on ainakin yksi objekti, samoin kuin jokaisen objektin, täytyy kuulua tarkalleen yhteen ryhmään.
2. Tiheyspohjainen menetelmä
Nämä algoritmit tuottavat klusterit määritettyyn sijaintiin perustuen tietojoukon osallistujien korkeaan tiheyteen. Se yhdistää joitain ryhmäjäsenten ryhmäjäsenyyksiä klustereissa tiheysstandarditasolle. Tällaiset prosessit voivat toimia vähemmän ryhmän pinta-alojen havaitsemisessa.
3. Centroidipohjainen menetelmä
Lähes jokaiselle klusterille viitataan arvovektorilla tämän tyyppisessä os-ryhmittelytekniikassa. Verrattuna muihin klustereihin, jokainen objekti on osa klusteria, jolla on pienin eroarvo. Klusterien lukumäärä tulisi olla ennalta määritetty, ja tämä on suurin tämäntyyppinen algoritmi-ongelma. Tämä menetelmä on lähinnä tunnistamisaihetta ja sitä käytetään laajasti optimointiongelmiin.
4. Hierarkkinen menetelmä
Menetelmä luo hierarkkisen hajoamisen tietylle dataobjektijoukolle. Hierarkkisen hajoamisen muodostumisen perusteella voimme luokitella hierarkkiset menetelmät. Tämä menetelmä annetaan seuraavasti
- Agglomeratiivinen lähestymistapa
- Erottava lähestymistapa
Agglomeratiivinen lähestymistapa tunnetaan myös nimellä Button-Up Approach. Tässä aloitamme jokaisesta esineestä, joka muodostaa erillisen ryhmän. Se sulauttaa edelleen kohteita tai ryhmiä lähellä toisiaan
Erotteleva lähestymistapa tunnetaan myös ylhäältä alas suuntautuvana lähestymistapana. Aloitamme kaikista samassa klusterissa olevista objekteista. Tämä menetelmä on jäykkä, ts. Sitä ei voida koskaan kumota, kun fuusio tai jako on valmis
5. Ruudukkoon perustuva menetelmä
Ruudukkoon perustuvat menetelmät toimivat objektitilassa sen sijaan, että tietoja jaettaisiin ruudukkoon. Ruudukko on jaettu datan ominaisuuksien perusteella. Tätä menetelmää käyttämällä ei-numeerista tietoa on helppo hallita. Tietotilaus ei vaikuta ruudukon osiointiin. Ruudukkoon perustuvan mallin tärkeä etu tarjoaa nopeamman suoritusnopeuden.
Hierarkkisen klusteroinnin edut ovat seuraavat
- Sitä voidaan soveltaa mihin tahansa attribuutityyppiin.
- Se tarjoaa joustavuuden suhteessa rakeisuustasoon.
6. Malliperusteinen menetelmä
Tämä menetelmä käyttää hypoteesimallista, joka perustuu todennäköisyysjakaumaan. Klusteroimalla tiheysfunktio tämä menetelmä paikallistaa klusterit. Se kuvastaa tietopisteiden alueellista jakaumaa.
Klusteroinnin soveltaminen tiedon louhintaan
Klusterointi voi auttaa monilla aloilla, kuten biologiassa, kasveissa ja niiden ominaisuuksien mukaan luokitelluissa eläimissä sekä markkinoinnissa. Klusterointi auttaa tunnistamaan tietyn asiakasrekisterin asiakkaat samalla tavalla. Useissa sovelluksissa, kuten markkinatutkimuksessa, kuvailutunnistuksessa, datan ja kuvankäsittelyssä, klusterointianalyysiä käytetään suuressa määrin. Klusterointi voi myös auttaa asiakaskunnan mainostajia löytämään erilaisia ryhmiä. Ja heidän asiakasryhmänsä voidaan määritellä ostamalla malleja. Biologiassa sitä käytetään kasvien ja eläinten taksonomioiden määrittämiseen, geenien luokitteluun, joilla on samanlainen toiminnallisuus, ja käsitykseen populaatiolle ominaisista rakenteista. Maapallon havainnointitietokannassa klusterointi helpottaa myös samankaltaisten käyttöalueiden löytämistä maalle. Se auttaa tunnistamaan taloryhmiä talon tyypin, arvon ja määränpään perusteella. Asiakirjojen ryhmittely verkossa on hyödyllinen myös tiedon löytämisessä. Klusterianalyysi on työkalu, jolla saadaan tietoa datan jakautumisesta kunkin klusterin ominaisuuksien tarkkailemiseksi tiedon louhintatoimintona.
johtopäätös
Klusterointi on tärkeää tiedon louhinnassa ja sen analysoinnissa. Tässä artikkelissa olemme nähneet kuinka klusterointi voidaan tehdä soveltamalla erilaisia klusterointialgoritmeja ja sen soveltamista todellisessa elämässä.
Suositeltava artikkeli
Tämä on opas kohtaan Mikä on klusterointi tiedon louhinnassa. Tässä keskustelimme klusteroinnin käsitteistä, määritelmistä, ominaisuuksista, soveltamisesta datanlouhintaan. Voit myös käydä läpi muiden ehdotettujen artikkeleidemme saadaksesi lisätietoja -
- Mikä on tietojenkäsittely?
- Kuinka tulla Data Analyst?
- Mikä on SQL-injektio?
- Mikä on SQL Server?
- Yleiskatsaus tietokaivosarkkitehtuuriin
- Klusterointi koneoppimisessa
- Hierarkkinen klusterointialgoritmi
- Hierarkkinen ryhmittely | Agglomeratiivinen ja jakautuva klusterointi