
Johdatus yhtyetekniikoihin
Ensemble oppiminen on koneoppimismenetelmä, joka hyödyntää useita perusmalleja ja yhdistää niiden tuotoksen optimoidun mallin tuottamiseksi. Tämän tyyppinen koneoppimisalgoritmi auttaa parantamaan mallin yleistä suorituskykyä. Täällä yleisimmin käytetty perusmalli on Päätöksen puun luokitin. Päätöspuu toimii periaatteessa useilla säännöillä ja tarjoaa ennustavan tuloksen, missä säännöt ovat solmuja ja heidän päätöksensä ovat heidän lapsensa ja lehden solmut muodostavat lopullisen päätöksen. Kuten päätöksenpuu esimerkissä näkyy.
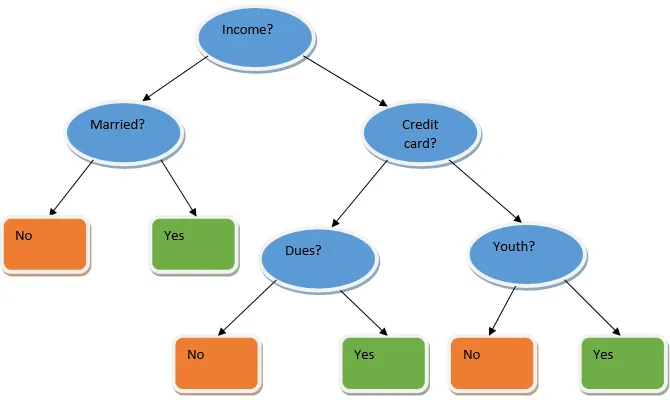
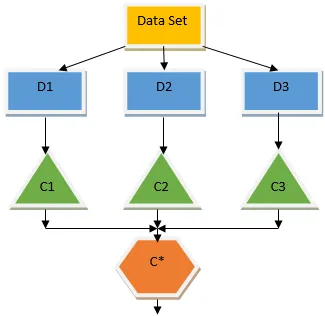
Yllä oleva päätöspuu puhuu periaatteessa siitä, voidaanko henkilölle / asiakkaalle antaa laina vai ei. Yksi lainan kelpoisuusvaatimuksista on, että jos (tulot = kyllä & naimisissa = ei) Sitten laina = Kyllä, joten päätöksentekopuheen luokittelu toimii näin. Yhdistämme nämä luokittelijat useaan perusmalliin ja yhdistämme niiden tuotokset rakentaaksesi yhden optimaalisen ennustavan mallin. Kuva 1.b näyttää kokonaiskuvan ryhmän oppimisalgoritmista.
Yhdistelmätekniikoiden tyypit
Erityyppisiä yhtyeitä, mutta painopisteemme keskittyy seuraaviin kahteen tyyppiin:
- pussitus
- tehostaminen
Nämä menetelmät auttavat vähentämään varianssia ja vääristymistä koneoppimismallissa. Yritäkäämme nyt ymmärtää mikä on puolueellisuus ja varianssi. Bias on virhe, joka syntyy algoritmimme väärien oletusten takia; suuri puolueellisuus osoittaa, että mallimme on liian yksinkertainen / alusasu. Varianssi on virhe, joka johtuu mallin herkkyydestä tietojoukon erittäin pienille vaihteluille; korkea variaatio osoittaa, että mallisi on erittäin monimutkainen / liian suuri. Ihanteellisessa ML-mallissa tulisi olla asianmukainen tasapaino puolueellisuuden ja varianssin välillä.
Bootstrap-aggregointi / pussitus
Pussitus on yhdistelmätekniikka, joka auttaa vähentämään mallimme variaatiota ja välttää siten ylimääräistä asennusta. Pussitus on esimerkki rinnakkaisesta oppimisalgoritmista. Pussitus perustuu kahteen periaatteeseen.
- Käynnistys: Alkuperäisen tietojoukon perusteella eri otospopulaatiot harkitaan korvaavilla.
- Yhdistäminen: Kaikkien luokittelulaitteiden tulosten keskiarvoistaminen ja yksittäisen tuloksen tarjoaminen käyttää tätä varten luokitteluun enemmistöäänestystä ja regressio-ongelman keskiarvoistamista. Yksi kuuluisista koneoppimisalgoritmeista, jotka käyttävät pussituksen käsitettä, on satunnainen metsä.
Satunnainen metsä
Satunnaisessa metsässä satunnaisnäytteestä, joka on poistettu populaatiosta korvaamalla, ja ominaisuusjoukko valitaan kaikkien ominaisuuksien joukosta päätöksentekopuu. Näistä ominaisuuksien alaryhmistä, mikä ominaisuus antaa parhaan jaon, on valittu päätöksentekopuun juureksi. Ominaisuuksien alajoukko on valittava satunnaisesti hinnalla millä hyvänsä, muuten tuotamme vain korreloivan virheen ja mallin varianssi ei parane.
Nyt olemme rakentaneet mallimme väestöstä otetuilla näytteillä, kysymys kuuluu, kuinka validoimme mallin? Koska harkitsemme näytteiden vaihtamista, kaikkia näytteitä ei oteta huomioon ja osaa niistä ei sisälly mihinkään pussiin, joten niitä kutsutaan pussinäytteiksi. Voimme vahvistaa mallimme tällä OOB (out of bag) -näytteellä. Tärkeät parametrit, jotka on otettava huomioon satunnaisessa metsässä, on näytteiden lukumäärä ja puiden lukumäärä. Tarkastellaan 'm' ominaisuuksien osajoukona ja 'p' on ominaisuuksien koko joukko, nyt peukaloiden pääsääntönä on aina ihanteellinen valita
- m as√ja vähimmäissolmun koko 1 luokitteluongelman ratkaisemiseksi.
- m P / 3: na ja vähimmäissolmun koko 5 on regressio-ongelmaan.
M ja p tulisi käsitellä viritysparametreina, kun käsittelemme käytännön ongelmaa. Harjoittelu voidaan lopettaa, kun OOB-virhe on vakiintunut. Yksi hajanaisen metsän haittapuoli on, että kun tietokannassamme on 100 ominaisuutta ja vain muutama ominaisuus on tärkeä, tämän algoritmin suorituskyky on huono.
tehostaminen
Tehostaminen on peräkkäinen oppimisalgoritmi, joka auttaa vähentämään mallimme painotusta ja varianssia joissakin ohjatun oppimisen tapauksissa. Se auttaa myös muuttamaan heikot oppijat vahvoiksi oppijoiksi. Tehostaminen perustuu siihen periaatteeseen, että heikot oppijat sijoitetaan peräkkäin, ja se antaa painon jokaiselle tietopisteelle jokaisen kierroksen jälkeen; enemmän painoa on annettu edellisen kierroksen virheellisesti luokitelulle datapisteelle. Tämä peräkkäinen painotettu menetelmä tietojoukkomme kouluttamiseen on tärkein ero pakkaamiseen verrattuna.
Kuvio3.a näyttää yleisen lähestymistavan tehostamiseen
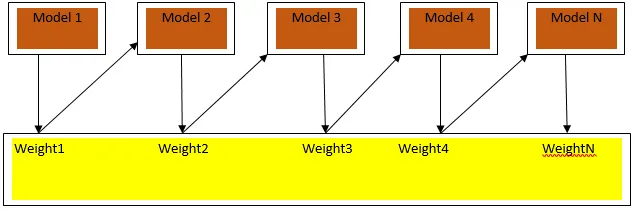
Lopulliset ennusteet yhdistetään painotetun enemmistöäänestyksen perusteella luokittelun yhteydessä ja painotetun summan regression tapauksessa. Laajimmin käytetty tehostamisalgoritmi on adaptiivinen korotus (Adaboost).
Mukautuva tehostaminen
Adaboost-algoritmiin liittyvät vaiheet ovat seuraavat:
- Antamille n datapisteelle määrittelemme tavoiteluokan ja alustamme kaikki painot arvoon 1 / n.
- Sovitamme luokittajat tietojoukkoon ja valitsemme luokituksen, jolla on vähiten painotettu luokitusvirhe
- Annamme luokittelijalle painot peukalon säännöllä perustuen tarkkuuteen, jos tarkkuus on yli 50%, paino on positiivinen ja päinvastoin.
- Päivitämme luokittelulaitteiden painot toiston lopussa; päivitämme lisää painoa luokittelemattomalle pisteelle niin, että seuraavassa iteraatiossa luokittelemme sen oikein.
- Kaikkien iteraatioiden jälkeen saadaan lopullinen ennustetulos perustuen enemmistöäänestykseen / painotettuun keskiarvoon.
Adaboosting toimii tehokkaasti heikkojen (vähemmän monimutkaisten) oppijoiden ja korkean puolueellisuuden luokitusten kanssa. Adaboostingin suurimpia etuja on, että se on nopea, siinä ei ole säkitysparametrien kaltaisia viritysparametreja, emmekä tee oletuksia heikoille oppijoille. Tämä tekniikka ei anna tarkkaa tulosta, kun
- Tietomme sisällä on enemmän poikkeavuuksia.
- Tietojoukko on riittämätön.
- Heikot oppijat ovat erittäin monimutkaisia.
Ne ovat myös alttiita melulle. Vahvistamisen tuloksena syntyneillä päätöspuilla on rajoitettu syvyys ja korkea tarkkuus.
johtopäätös
Ensemble-oppimistekniikoita käytetään laajasti mallin tarkkuuden parantamisessa; meidän on päätettävä, mitä tekniikkaa käytetään tietokantamme perusteella. Näitä tekniikoita ei kuitenkaan suositeta joissain tapauksissa, joissa tulkittavuus on tärkeätä, koska menettämme tulkittavuuden suorituskyvyn parantamisen kustannuksella. Näillä on valtava merkitys terveydenhoitoalalla, jossa pieni suorituskyvyn parannus on erittäin arvokasta.
Suositellut artikkelit
Tämä on opas Ensemble Techniques -tekniikkaan. Tässä keskustellaan johdannosta ja kahdesta tärkeimmästä Ensemble Techniques -tyypistä. Voit myös käydä läpi muiden aiheeseen liittyvien artikkeleidemme saadaksesi lisätietoja-
- Steganografiatekniikat
- Koneoppimistekniikat
- Tiiminrakennustekniikat
- Data Science algoritmit
- Ensemble-oppimisen eniten käytettyjä tekniikoita