

Johdatus Spark-komentoihin
Apache Spark on Hadoopin päälle rakennettu kehys nopeaa laskentaa varten. Se laajentaa MapReducen käsitettä klusteripohjaisessa skenaariossa tehtävän suorittamiseksi tehokkaasti. Spark Command on kirjoitettu Scalassa.
Spark voi käyttää Hadoop-ohjelmaa seuraavilla tavoilla (katso alla):
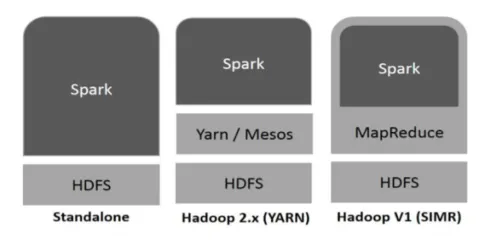
Kuvio 1
https://www.tutorialspoint.com/
- Itsenäinen: Spark otetaan suoraan käyttöön Hadoopin päälle. Spark-työt kulkevat samanaikaisesti Hadoopilla ja Sparkilla.
- Hadoop-lanka: Spark toimii langalla ilman mitään ennakkoasennusta.
- Spark in MapReduce (SIMR): Spark in MapReduce -laitetta käytetään käynnistämään kipinöinti itsenäisen käyttöönoton lisäksi. SIMR: n avulla Spark voidaan käynnistää ja käyttää kuoriansa ilman minkäänlaista järjestelmänvalvojan oikeutta.
Spark-komponentit:
- Apache Spark Core
- Spark SQL
- Spark streaming
- MLIB
- GraphX
Joustavia hajautettuja tietoaineistoja (RDD) pidetään Spark-komentojen perustietorakenteena. RDD on luonteeltaan muuttumaton ja vain luku -tyyppinen. Kaikenlainen laskenta kipinäkomennoissa tapahtuu RDD: n muunnoksilla ja toimilla.
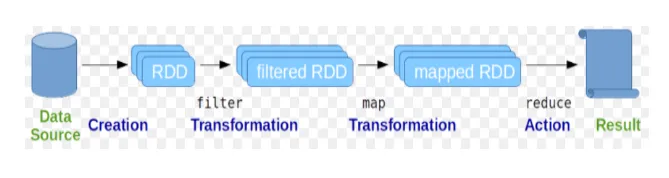
Kuvio 2
Google Kuva
Spark shell tarjoaa välineen käyttäjille vuorovaikutuksessa sen toimintojen kanssa. Spark-komennoilla on paljon erilaisia komentoja, joita voidaan käyttää käsittelemään tietoja interaktiivisessa kuoressa.
Peruskäskykomennot
Katsotaanpa joitain alla esitetyistä Basic Spark -komennoista: -
-
Spark-kuoren käynnistäminen:

Kuvio 3
-
Lue tiedosto paikallisesta järjestelmästä:

Tässä “sc” on kipinäkonteksti. Koska data.txt on kotihakemistossa, se luetaan näin, muuten on määritettävä koko polku.
-
Luo RDD yhdenmukaistamisen avulla

NewData on nyt RDD.
-
Laske RDD-kohteita

-
Kerätä
Tämä toiminto palauttaa kaiken RDD: n sisällön ohjainohjelmaan. Tämä on hyödyllinen virheenkorjauksessa kirjoitusohjelman eri vaiheissa.
-
Lue ensimmäiset 3 tuotetta RDD: stä

-
Tallenna tulostetut / käsitellyt tiedot tekstitiedostoon

Tässä "output" -kansio on nykyinen polku.
Väliset kipinökomennot
1. Suodata RDD: llä
Luodaan uusi RDD kohteille, jotka sisältävät ”kyllä”.

Transformaatiosuodatin on kutsuttava olemassa olevaan RDD: hen suodattaaksesi sanaa “kyllä”, mikä luo uuden RDD: n uuden kohdeluettelon kanssa.
2. Ketjun toiminta

Tässä suodattimen muuntaminen ja laskentatoimi toimivat yhdessä. Tätä kutsutaan ketjutoiminnaksi.
3. Lue ensimmäinen kohta RDD: stä

4. Laske RDD-osiot
Kuten tiedämme, RDD on tehty useista osioista, on tarpeen laskea ei. väliseinät. Koska se auttaa virittämisessä ja vianetsinnässä Spark-komentojen kanssa työskennellessä.

Oletusarvoisesti vähimmäismäärä ei. pf-osio on 2.
5. liittyä
Tämä toiminto yhdistää kaksi taulukkoa (taulukkoelementti on pareittain) perustuen yhteiseen avaimeen. Pariisina RDD: ssä ensimmäinen elementti on avain ja toinen elementti on arvo.
6. Välimuistin tiedosto
Välimuisti on optimointitekniikka. Välimuistissa oleva RDD tarkoittaa, että RDD pysyy muistissa, ja kaikki tulevat laskennat tehdään niille muistissa oleville RDD-tiedoille. Se säästää levyn lukemisaikaa ja parantaa suorituskykyä. Lyhyesti sanottuna, se vähentää tiedonsaantiin kuluvaa aikaa.

Tietoja ei kuitenkaan tallenneta välimuistiin, jos suoritat toiminnon yläpuolella. Tämä voidaan todistaa käymällä verkkosivulla:
http: // localhost: 4040 / varastointi
RDD välimuistiin, kun toimenpide on suoritettu. Esimerkiksi:

Vielä yksi toiminto, joka toimii välimuistin () tapaan, on edelleen olemassa (). Pysyvyys antaa käyttäjille joustavuuden antaa argumentti, joka voi auttaa tietojen välimuistiin tallentamista muistiin, levyyn tai tyhjämuistiin. Pysy ilman mitään argumentteja toimii samalla tavalla kuin välimuisti ().
Advanced kipinäkomennot
Katsotaanpa joitain edistyneemmistä Spark-komennoista, jotka on annettu alla: -
-
Lähetä muuttuja
Broadcast-muuttuja auttaa ohjelmoijaa pitämään jokaisen klusterin koneen välimuistissa olevan ainoan muuttujan lukeman sen sijaan, että toimittaa kyseisen muuttujan kopion tehtävien mukana. Tämä auttaa vähentämään viestintäkustannuksia.
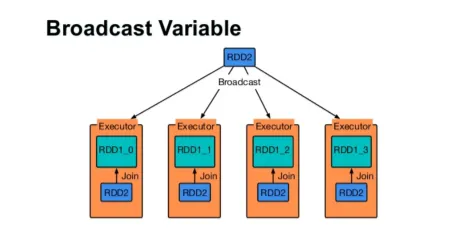
Kuvio 4
Google Kuva
Lyhyesti sanottuna Broadcastted-muuttujalla on kolme pääpiirtää:
- Muuttumaton
- Sovita muistiin
- Hajautettu klusteriin
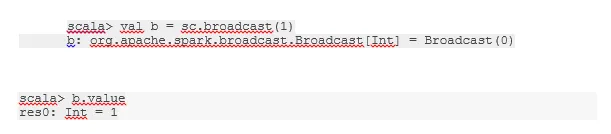
-
akut
Akkumulaattorit ovat muuttujia, jotka lisätään niihin liittyviin toimintoihin. Akkuihin on monia käyttötarkoituksia, kuten laskurit, summat jne.

Koodin varaajan nimi näkyi myös Spark UI -sovelluksessa.
-
Kartta
Karttatoiminto auttaa iteraatiossa kaikilla RDD-riveillä. Kartassa käytettyä toimintoa käytetään jokaisessa RDD-elementissä.
Esimerkiksi RDD: ssä (1, 2, 3, 4, 6), jos käytämme ”rdd.map (x => x + 2)”, saadaan tulos muodossa (3, 4, 5, 6, 8).
-
Flatmap
Litteä kartta toimii samalla tavalla kuin kartta, mutta kartta palauttaa vain yhden elementin, kun taas litteä kartta voi palauttaa elementtiluettelon. Siksi lauseiden jakaminen sanoiksi edellyttää litteää kuvaa.
-
Coalesce
Tämä toiminto auttaa välttämään datan sekoittumista. Tätä käytetään olemassa olevassa osiossa siten, että vähemmän dataa sekoitetaan. Tällä tavoin voimme rajoittaa klusterin solmujen käyttöä.
Vinkkejä kipinökomentojen käyttämiseen
Alla on erilaisia Spark-komentojen vinkkejä ja vinkkejä: -
- Sparkin aloittelijat voivat käyttää Spark-kuorta. Koska Spark-komennot on rakennettu Scalaan, Scalan kipinäkuoren käyttäminen on ehdottomasti hienoa. Python-kipinäkuorta on kuitenkin saatavana, joten jopa jotain voi käyttää, joka on perehtynyt pythoniin.
- Spark-kuorella on paljon vaihtoehtoja klusterin resurssien hallitsemiseksi. Komennon alapuolella voit auttaa sinua tässä:

- Sparkissa pitkien tietoaineistojen käsittely on tavallinen asia. Mutta asiat menevät pieleen, kun huono panos otetaan. On aina hyvä idea pudottaa huonot rivit käyttämällä Spark-suodatintoimintoa. Hyvä panoskokonaisuus on hieno tapa.
- Spark valitsee tietosi varten oman osion omasta. Mutta on aina hyvä käytäntö pitää silmä partitioilla ennen työn aloittamista. Eri osioiden kokeilu auttaa sinua samanaikaisesti työssäsi.
Johtopäätös - kipinökomennot:
Spark-komento on vallankumouksellinen ja monipuolinen iso datamoottori, joka voi toimia eräkäsittelyssä, reaaliaikaisessa prosessoinnissa, tietojen välimuistiin tallentamisessa jne. Sparkilla on rikas sarja koneoppimiskirjastoja, jotka voivat auttaa tietotekijöitä ja analyyttisiä organisaatioita rakentamaan vahvoja, vuorovaikutteisia ja nopeat sovellukset.
Suositellut artikkelit
Tämä on opas Spark-komentoihin. Tässä olemme keskustelleet sekä perus- että edistyneistä Spark-komennoista ja joistain välittömistä Spark-komennoista. Voit myös tarkastella seuraavaa artikkelia saadaksesi lisätietoja -
- Adobe Photoshop -komennot
- Tärkeitä VBA-komentoja
- Tableau-komennot
- Huijauskortti SQL (komennot, ilmaiset vinkit ja temput)
- Spark SQL: n liitostyypit (esimerkit)
- Kipinäkomponentit | Yleiskatsaus ja 6 suosituinta komponenttia