

Ero Hadoopin ja HBase: n välillä
Hadoop on avoimen lähdekoodin Java-kehys, jota käytetään hallitsemaan ja käsittelemään valtavaa määrää jäsenneltyä ja jäsentämätöntä tietoa. Hadoop on massiivisesti skaalautuva, joten sitä käytetään suurten datatyökuormien käsittelemiseen. Suuret tiedot tallennetaan, käsitellään ja käsitellään luotettavassa ja laajennettavassa klusterissa. HBase (Hadoop-tietokanta) on ei-relatiivinen ja ei vain SQL eli NoSQL-tietokanta, joka toimii Hadoopin päällä hajautettuna ja skaalautuvana isoina tietovarastoina. Se on avoimen lähdekoodin tietokanta, johon tiedot tallennetaan rivien ja sarakkeiden muodossa, siinä solussa on sarakkeiden ja rivien leikkauspiste.
Alla on Hadoop-arkkitehtuurin ydinkomponentit:
- Hadoopin hajautettu tiedostojärjestelmä (HDFS): Hadoop sisältää hajautetun tallennusjärjestelmän, Hadoopin hajautettu tiedostojärjestelmä (HDFS). HDFS on isäntä-orja-arkkitehtuuri, joka tallentaa tietoja klusterin yli. Tiedot, jotka isäntäsolmu on jakanut useille slave-solmuille lomakelohkossa. Pääsolmua kutsutaan Namenodeksi ja orjasolmuja kutsutaan Datanodeksi. HDFS on helposti laajennettavissa ja tallentaa valtavan määrän dataa Datanodeihin. HDFS: llä on konfiguroitava replikaatiotekijä oletusarvolla 3, jota voidaan muokata.
- MapReduce: MapReduce on ohjelmointimalli, joka prosessoituu rinnakkain valtavan määrän tietojoukkoja verkon kautta. MapReduce viittaa kahteen erilaiseen tehtävään: kartoittaa syöttötiedot, joissa tiedot, jotka on jaettu tuplaksi kutsuttuihin tietojoukkoihin, ja vähentää tehtävää, vie nämä tuplat kartalta syöttönä ja yhdistää muodostaen alkuperäisen tulosteen.
- Lanka: YARN tarkoittaa vielä yhtä resurssinavigoijaa, joka laskee resursseja, kuten hallitsee prosessoria ja muistia, ajoittaa resurssipyynnöt.
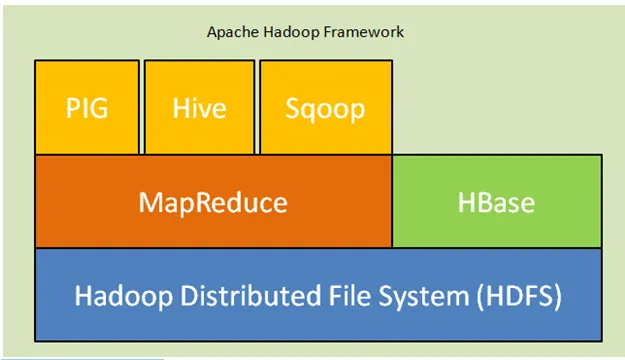
Kuva Apache Hadoop Framework
Aluepalvelin palvelee tietoja lukemiseen / kirjoittamiseen. Kaikki HBase-tiedot tallennetaan HDFS-tiedostoon. HDFS Datanode tallentaa tiedot, joita aluepalvelin hallitsee. HDFS Namenode pitää metatietotietoja kaikista tiedostoja sisältävistä fyysisistä datalohkoista.
Versiointia käytetään seuraamaan solujen muutoksia, mikä pitää sisällön version mukana. Tästä lähtien voidaan hakea mikä tahansa sisältöversio. Jokainen solun arvo sisältää 'versio' -attribuutin suhteessa aikaleimoon solun noutamiseksi. Jokainen kartan arvo on keskeytymätön tavujoukko. Kartta indeksoidaan rivinäppäimellä, sarakkeenäppäimellä ja aikaleimalla. HBase-arkkitehtuuri on erittäin skaalautuvaa, harvaa, hajautettua, pysyvää ja moniulotteisesti lajiteltua karttaa.
Head to Head -vertailu Hadoopin ja HBasen välillä (infografia)
Alla on 7 parasta eroa Hadoopin ja HBasen välillä
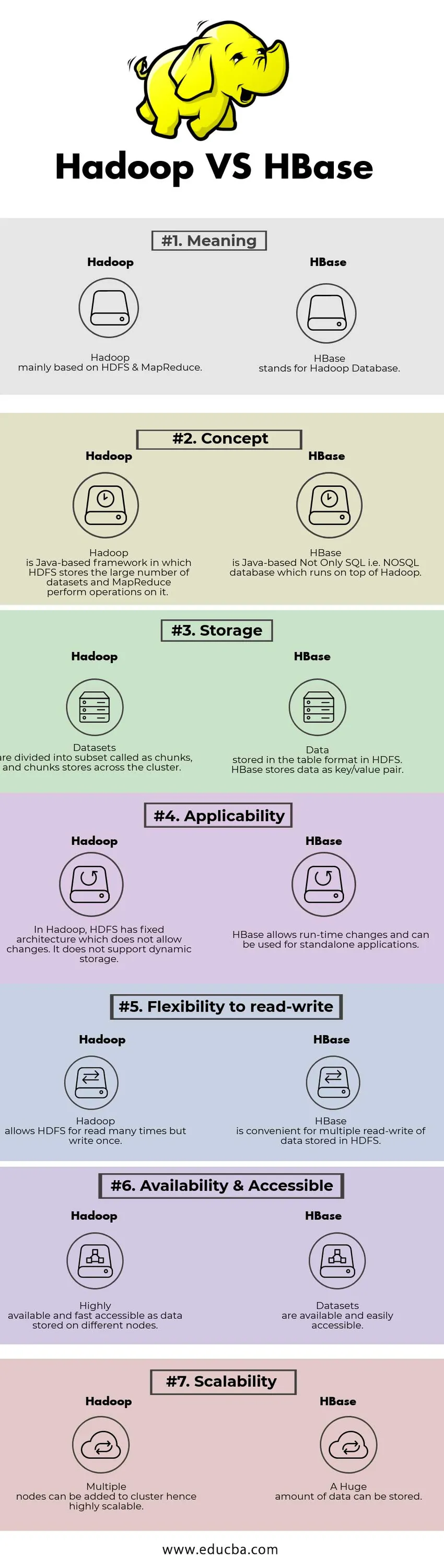
Keskeiset erot Hadoop vs. HBase välillä
Ero Hadoopin ja HBase: n välillä selitetään alla esitetyissä kohdissa:
- Hadoop ei sovellu online-analyyttiseen käsittelyyn (OLAP) ja HBase on osa Hadoop-ekosysteemiä, joka tarjoaa satunnaisen reaaliaikaisen pääsyn (luku / kirjoitus) tietoihin Hadoop-tiedostojärjestelmässä.
- Hadoop-kehys on rakenteellisesti vikasietoinen ja tukee nopeaa tiedonsiirtoa solmujen välillä jopa järjestelmävirheiden aikana. HBase on ei-relatiivinen ja avoimen lähdekoodin Ei vain SQL-tietokanta, joka toimii Hadoopin päällä. HBase kuuluu CP-tyypin CAP (johdonmukaisuus, saatavuus ja osiotoleranssi) -lauseen.
- Hadoop sopii parhaiten eräanalyysien suorittamiseen. Yksi suurimmista haitoista on kuitenkin kyvyttömyys suorittaa reaaliaikaista analyysiä, joka on tietotekniikka-alan trendivaatimus. HBase puolestaan pystyy käsittelemään suuria tietojoukkoja, eikä se ole sopiva eräanalyysille. Sen sijaan sitä käytetään kirjoittamaan / lukemaan tietoja Hadoopista reaaliajassa.
- Sekä Hadoop että HBase kykenevät käsittelemään jäsenneltyä, osittain jäsentämätöntä ja jäsentämätöntä tietoa. Hadoopissa HDFS: ltä puuttuu muistin prosessointimoottori, joka hidastaa data-analyysin prosessia; koska se käyttää tavallista vanhaa MapReducea siihen. HBase, päinvastoin, ylpeilee muistin prosessointimoottorilla, joka lisää huomattavasti luku- / kirjoitusnopeutta.
- Hadoop on erittäin läpinäkyvä suorittaessaan data-analyysiä. Toisaalta HBase, joka on NoSQL-tietokanta taulukkomuodossa, noutaa arvot lajittelemalla ne eri avainarvoihin.
Hadoop vs. HBase -vertailutaulukko
| VERTAILUN PERUSTEET | Hadoop | HBase |
| merkitys | Hadoop perustuu pääasiassa HDFS: ään ja MapReduceen. | HBase tarkoittaa Hadoop-tietokantaa. |
| Konsepti | Hadoop on Java-pohjainen kehys, johon HDFS tallentaa suuren määrän tietojoukkoja ja MapReduce suorittaa siihen operaatiot. | HBase on Java-pohjainen paitsi SQL eli NoSQL-tietokanta, joka toimii Hadoopin päällä. |
| varastointi | Aineistot jaetaan alajoukkoon, jota kutsutaan paloiksi, ja palat tallentuvat klusterin poikki. | Tiedot tallennetaan taulukkomuodossa HDFS: ään. HBase tallentaa tiedot avain / arvo-pariksi. |
| sovellettavuus | Hadoopissa HDFS: llä on kiinteä arkkitehtuuri, joka ei salli muutoksia. Se ei tue dynaamista tallennusta. | HBase sallii ajoajan muutokset ja sitä voidaan käyttää erillisissä sovelluksissa. |
| Joustavuus lukea ja kirjoittaa | Hadoop sallii HDFS: n lukea useita kertoja, mutta kirjoittaa kerran. | HBase on kätevä useaan luku- ja kirjoitustietoon, joka on tallennettu HDFS: ään |
| Saatavuus ja saatavuus | Erittäin saatavissa ja nopeasti saatavilla eri solmuihin tallennettuna datana. | Tietoaineistot ovat saatavilla ja helposti saatavilla |
| skaalautuvuus | Useita solmuja voidaan lisätä klusteriin siten erittäin skaalautuva. | Voidaan tallentaa valtava määrä tietoa. |
Johtopäätös - Hadoop vs HBase
Hadoop-arkkitehtuuri perustuu pääasiassa HDFS: ään ja MapReduce-ohjelmaan. HBase on Hadoop-järjestelmän tukikomponentti. HBase pystyy isännöimään valtavia taulukoita ja tarjoamaan nopean satunnaisen pääsyn käytettävissä oleviin tietoihin, kun taas HDFS soveltuu suurten tiedostojen tallennukseen. Sekä Hadoop että HBase tarjoavat nopean pääsyn tietoihin, mutta HBase-luku- / kirjoitusoperaatiot voidaan suorittaa, ja HDFS: lle lukea useita kertoja ja kerran kirjoitus voidaan suorittaa. Tässä artikkelissa kuvailtiin ymmärrystä Hadoopista ja HBaseista, korostettiin lyhyesti ominaisuuksia ja verrattiin viisaasti.
Suositeltava artikkeli
- Apache Hadoop vs Apache Spark | 10 parasta vertailua, jotka sinun on tiedettävä!
- Hadoop vs. pesää - selvitä parhaat erot
- HBase vs. Cassandra - kumpi on parempi (infografia)
- Apache Hive: n 12 parasta vertailua Apache HBase -sovellukseen (Infographics)
- Hadoop vs Spark: Mitkä ovat ominaisuudet