

Johdanto RDBMS-haastatteluun liittyviin kysymyksiin ja vastauksiin
Joten jos valmistaudut työhaastatteluun RDBMS: ssä. Olen varma, että haluat tietää yleisimmät 2019 RDBMS -haastattelua koskevat kysymykset ja vastaukset, jotka auttavat sinua murtaamaan RDBMS-haastattelun helposti. Alla on luettelo parhaimmista RDBMS-haastattelukysymyksistä ja vastauksista pelastushetkelläsi.
Siksi meillä on taipumus lisätä 2019 RDBMS -haastattelukysymystä, joita kysytään enimmäkseen haastattelussa
1.Mitä ovat RDBMS: n eri ominaisuudet?
Vastaus:
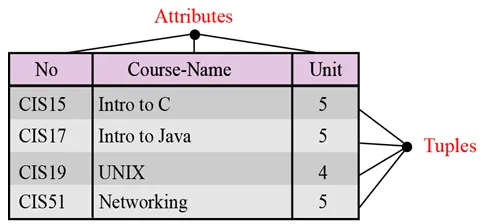
Nimi. Jokaisella relaatiotietokannan suhteella tulisi olla nimi, joka on ainutlaatuinen kaikkien muiden suhteiden välillä.
Attribuutteja. Jokaista relaation saraketta kutsutaan määritteeksi.
Tuples. Jokaista suhteen riviä kutsutaan tupleksi. Tuple määrittelee attribuutin arvojen kokoelman.
2.Selitä ER-malli?
Vastaus:
ER-malli on kokonaisuussuhdemalli. ER-malli perustuu todelliseen maailmaan, joka koostuu kokonaisuuksista ja suhdeobjekteista. Kokonaisuuksia kuvataan tietokannassa määritteillä.
3. Määrittele oliopohjainen malli?
Vastaus:
Oliopainotteinen malli perustuu esinekokoelmiin. Kohteeseen mahtuu arvoja, jotka on tallennettu esimerkiksi muuttujiin objektin sisällä. Kohteet, joilla on samantyyppiset arvot ja täsmälleen samat menetelmät, on ryhmitelty luokkiin.
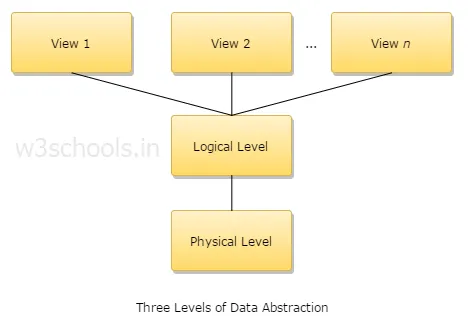
4.Selitä tiedonkeruun kolme tasoa?
Vastaus:
1. Fyysinen taso: Tämä on alhaisin abstraktion taso, ja se kuvaa tietojen tallennustapaa.
2. Looginen taso: Seuraava abstraktiotaso on looginen, se kuvaa, minkä tyyppisiä tietoja tietokantaan tallennetaan ja mikä on näiden tietojen välinen suhde.
3. Katselutaso: Korkein abstraktion taso ja se kuvaa ainoaa koko tietokantaa.
 https://www.w3schools.in/dbms/data-schemas/
https://www.w3schools.in/dbms/data-schemas/
5.Mitä ovat Coddin 12 relaatiotietokantaa koskevat säännöt?
Vastaus:
Coddin 12 sääntöä ovat joukko kolmetoista sääntöä (numeroitu nollasta kahteentoista), jonka on ehdottanut Edgar F. Codd.
Coddin säännöt: -
Sääntö 0: Järjestelmän on oltava suhteellinen, tietokanta ja myös hallintajärjestelmä.
Sääntö 1: Tietosääntö: Jokainen tietokannan tieto on esitettävä yksilöllisesti, nimittäin arvot lähinnä sarakkeissa eri taulukkorivillä.
Sääntö 2: Taattu käyttöoikeussääntö: Kaikkien tietojen on oltava sisäänpääsyisiä. Sanotaan, että tietokannan kaikkien skalaariarvojen on oltava oikein / loogisesti osoitettavissa.
Sääntö 3: Null-arvojen systemaattinen käsittely: DBMS: n on sallittava jokaisen parin pysyminen nollana.
Sääntö 4: Aktiivinen online-luettelo (tietokannan rakenne) relaatiomallin perusteella: Järjestelmän on tuettava verkko-, relaatio- jne. Rakennetta, joka on pääsy sallitulle käyttäjälle säännöllisen kyselyn avulla.
Sääntö 5: Kattava tietojen alikieli: Järjestelmän on avustettava vähintään yhtä relaatiokieltä, joka:
1.On lineaarinen syntaksi
2.Sitä voidaan käyttää sekä interaktiivisesti että sovellusohjelmissa,
3.Se tukee tietomääritysoperaatioita (DDL), datan manipulointitoimenpiteitä (DML), tietoturva- ja eheysrajoitteita sekä tapahtumien hallintaa (aloitus, sitoutuminen ja palauttaminen).
Sääntö 6: Näkymien päivittämissääntö : Järjestelmän on päivitettävä kaikki teoriassa parannettavat näkymät.
Sääntö 7: Korkean tason lisäys, päivitys ja poistaminen: Järjestelmän on tuettava operaattoreiden lisäämistä, päivittämistä ja poistamista.
Sääntö 8: Fyysisen datan riippumattomuus: Fyysisen tason muokkaaminen (tietojen tallennustapa taulukkojen tai linkitettyjen luetteloiden avulla jne.) Ei saa vaatia sovelluksen muuttamista.
Sääntö 9: Loogisen tiedon riippumattomuus: Loogisen tason (taulukot, sarakkeet, rivit jne.) Muokkaaminen ei saa vaatia sovelluksen muuttamista.
Sääntö 10: Eheyden riippumattomuus: Eheyden rajoitukset on yksilöitävä sovellusohjelmista yksilöllisesti ja tallennettava luetteloon.
Sääntö 11: Jakelun riippumattomuus: Tietokannan osien jakautuminen eri paikkoihin ei saisi olla tietokannan käyttäjien nähtävissä.
Sääntö 12: Ei-käännössääntö: Jos järjestelmä tarjoaa matalan tason (ts. Tietueet) -rajapinnan, sitä liitäntää ei voida käyttää järjestelmän kumoamiseen.
6.Mikä on normalisointi? ja mikä selittää erilaisia normalisointimuotoja.
Vastaus:
Tietokannan normalisointi on tietojen järjestämisprosessi datan redundanssin minimoimiseksi. Tämä puolestaan varmistaa tietojen johdonmukaisuuden. Tiedon redundanssiin liittyy monia ongelmia, kuten levytilan tuhlaaminen, tietojen epäjohdonmukaisuus, DML (Data Manipulation Language) -kyselyt hidastuvat. Normalisointimuotoja on erilaisia: - 1NF, 2NF, 3NF, BCNF, 4NF, 5NF, ONF, DKNF.
1. 1NF: - Jokaisessa sarakkeessa olevien tietojen tulisi olla atominumero, useita arvoja erotettu pilkulla. Taulukko ei sisällä toistuvia sarakeryhmiä. Tunnista jokainen tietue yksilöllisesti ensisijaisella avaimella.
2. 2NF: - Taulukon tulee vastata kaikkia 1NF-ehtoja ja siirtää tarpeeton data erilliseen taulukkoon. Lisäksi se luo suhteen näiden taulukoiden välillä vieraita avaimia käyttämällä.
3. 3NF: - 3NF-taulukon tulee täyttää kaikki 1NF: n ja 2NF: n ehdot. 3NF ei sisällä määritteitä, jotka ovat osittain riippuvaisia ensisijaisesta avaimesta.
7. Määritä ensisijainen avain, vieras avain, ehdokasavain, superavain?
Vastaus:
Ensisijainen avain: ensisijainen avain on avain, joka ei salli päällekkäisten arvojen ja nolla-arvojen käyttöä. Ensisijainen avain voidaan määritellä sarake- tai taulukotasolla. Vain yksi pääavain taulukkoa kohti on sallittu.
Vieras avain: vieras avain sallii vain viitatussa sarakkeessa olevat arvot. Se sallii kopioiden tai nolla-arvojen. Se voidaan määritellä saraketasoksi tai taulukkotasoksi. Se voi viitata ainutkertaisen / ensisijaisen avaimen sarakkeeseen.
Ehdokasavain: Ehdokasavain on vähintään superavain, ehdokkaiden avainominaisuuksissa ei ole asianmukaista alaryhmää, joka voi olla superavain.
Supernäppäin : Supernäppäin on joukko relaatiomallin attribuutteja, joista kaikki kaavan attribuutit ovat osittain riippuvaisia. Kaikilla kahdella rivillä ei voi olla sama superavainmääritteiden arvo.
8.Mikä on erityyppinen hakemisto?
Vastaus:
Hakemistot ovat: -
Clustered index: - Se on hakemisto, jolla tiedot fyysisesti tallennetaan levylle. Siksi vain yksi klusteroitu hakemisto voidaan luoda tietokantataulukkoon.
Klusteroimaton hakemisto: - Se ei määrittele fyysistä tietoa, mutta määrittelee loogisen järjestyksen. Tyypillisesti B-puu tai B + -puu luodaan tätä tarkoitusta varten.
9.Mitä ovat RDBMS: n edut?
Vastaus:
• Redundanssin hallinta.
• Rehellisyys voidaan varmistaa.
• Epäjohdonmukaisuus voidaan välttää.
• Tietoja voidaan jakaa.
• Vakio voidaan panna täytäntöön.
10.Nimi joitain RDBMS-järjestelmän alajärjestelmiä?
Vastaus:
Tulon ja lähdön hallinta, tietoturva, kielten käsittely, tallennusten hallinta, kirjaaminen ja palauttaminen, jakelun hallinta, tapahtumien hallinta, muistin hallinta.
11.Mikä on puskurinhallintaohjelma?
Vastaus:
Puskurinhallintaohjelma onnistuu keräämään tietoja levymuistista päämuistiin ja päättämään, mitkä tiedot välimuistissa on nopeampaa käsittelyä varten.
Suositeltava artikkeli
Tämä on opas RDBMS-haastattelukysymysten ja vastausten luetteloon, jotta ehdokas voi helposti hajottaa nämä RDBMS-haastattelukysymykset. Voit myös katsoa seuraavia artikkeleita saadaksesi lisätietoja -
- Tärkeimmät data-analyyttisiä haastattelukysymyksiä
- 13 uskomattomia tietokantatestaushaastattelukysymyksiä ja -vastauksia
- Kymmenen suosituinta haastattelukysymystä ja vastauksia
- 5 hyödyllistä SSIS-haastattelua koskevia kysymyksiä ja vastauksia