

Syvän oppimisen haastattelua koskevat kysymykset ja vastaukset
Nykyään syväoppimista pidetään yhtenä nopeimmin kasvavasta tekniikasta, jolla on valtava kyky kehittää sovellus, jonka on havaittu vaikeaksi jonkin aikaa sitten. Puheentunnistus, kuvan tunnistaminen, mallien löytäminen tietojoukosta, esineiden luokittelu valokuvissa, merkkitekstien luominen, itse ajavat autot ja monet muut ovat vain muutamia esimerkkejä, joissa Deep Learning on osoittanut sen merkityksen.
Joten olet vihdoin löytänyt unelmatyösi syväoppimisesta, mutta mietit miten syvän oppimisen haastattelu halkaistaan ja mitkä voisivat olla mahdollisia syvän oppimisen haastatteluun liittyviä kysymyksiä. Jokainen haastattelu on erilainen ja myös työn laajuus on erilainen. Pitäen tämän mielessä olemme suunnitelleet yleisimmät syvä oppimisen haastatteluun liittyvät kysymykset ja vastaukset auttaaksesi sinua menestymään haastattelussa.
Alla on muutama syvä oppimishaastattelu -kysymys, joita kysytään usein haastattelussa ja jotka auttaisivat myös testaamaan tasojasi:
1. osa - Syvän oppimisen haastattelua koskevat kysymykset (perus)
Tämä ensimmäinen osa kattaa syväoppimishaastattelun peruskysymykset ja vastaukset
1. Mikä on syväoppiminen?
Vastaus:
Koneoppimisen alue, joka keskittyy syviin keinotekoisiin hermoverkkoihin, jotka ovat aivojen löyhästi inspiroimia. Aleksei Grigorevitš Ivakhnenko julkaisi ensimmäisen syväoppimisverkoston yleisen päällikön. Nykyään sitä sovelletaan useilla aloilla, kuten tietokonenäkö, puheentunnistus, luonnollinen kielenkäsittely.
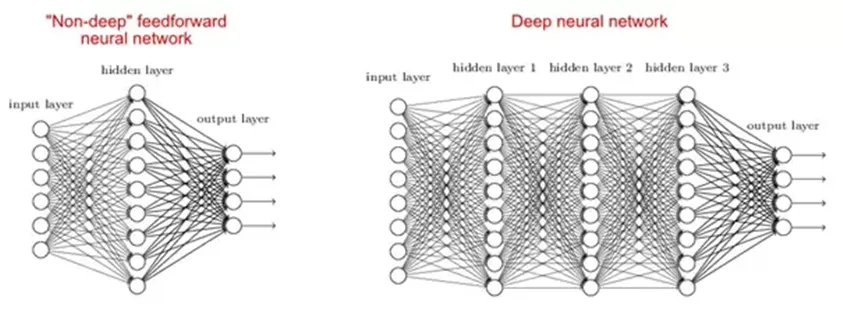
2. Miksi syvät verkot ovat parempia kuin matalat?
Vastaus:
On tutkimuksia, joiden mukaan sekä matalat että syvät verkot mahtuvat mihin tahansa toimintoon, mutta koska syvissä verkoissa on useita piilotettuja kerroksia, jotka ovat usein erityyppisiä, joten ne pystyvät rakentamaan tai poistamaan parempia ominaisuuksia kuin matalat mallit, joissa on vähemmän parametreja.
3. Mikä on kustannustoiminto?
Vastaus:
Kustannusfunktio on hermoverkon tarkkuuden mitta annetulle harjoitusnäytteelle ja odotetulle tuotokselle. Se on yksi arvo, ei-vektori, koska se antaa hermoverkon suorituskyvyn kokonaisuutena. Se voidaan laskea seuraavasti: Keskimääräinen neliövirhefunktio: -
MSE = 1nΣi = 0n (Y i-Yi) 2
Missä Y ja haluttu arvo Y on mitä haluamme minimoida.
Siirrymme seuraavaan syväoppimishaastattelu-kysymykseen.
4. Mikä on kaltevuuslasku?
Vastaus:
Gradientin laskeutuminen on pohjimmiltaan optimointialgoritmi, jota käytetään oppimaan parametrien arvo, joka minimoi kustannustoiminnon. Se on iteratiivinen algoritmi, joka liikkuu jyrkimmän laskeutumisen suuntaan gradientin negatiivin määrittelemällä tavalla. Laskemme kullekin parametrille kustannustoiminnon gradienttilaskun ja päivitämme parametria seuraavalla kaavalla: -
Θ: = Θ-αd∂ΘJ (Θ)
Missä Θ - on parametrivektori, α - oppimisnopeus, J (Θ) - on kustannusfunktio.
5. Mikä on lisääntyminen?
Vastaus:
Backpropagation on harjoitusalgoritmi, jota käytetään monikerroksisessa hermoverkossa. Tässä menetelmässä siirrämme virhe verkon päästä kaikkiin verkon sisällä oleviin painoihin ja sallimme siten gradientin tehokkaan laskennan. Se voidaan jakaa useisiin vaiheisiin seuraavasti: -
Treenaustietojen eteneminen eteenpäin tuotannon tuottamiseksi.
Kun käytetään tavoitearvoa ja lähtöarvon virhejohdannaista, voidaan laskea suhteessa ulostulon aktivointiin.
Kun sitten jatkamme virheen johdannaisten laskemista suhteessa edellisen ulostulon aktivointiin, jatkamme tätä kaikille piilotetuille tasoille.
Käytämme aiemmin laskettuja johdannaisia tuotosta ja kaikkia piilotettuja kerroksia varten, laskemme virhejohdannaiset painon perusteella.
Ja sitten päivitämme painot.
6. Selitä seuraavat kolme gradientin laskeutumisen vaihtoehtoa: erä, stokastinen ja minierä?
Vastaus:
Stokastinen kaltevuuslasku : Tässä käytetään vain yhtä harjoitusesimerkkiä kaltevuuden ja päivitysparametrien laskemiseen.
Erägradientin laskeutuminen : Täällä lasketaan koko tietojoukon gradientti ja suoritetaan päivitys jokaisessa iteraatiossa.
Mini-erägradientin laskeutuminen : Se on yksi suosituimmista optimointialgoritmeista. Se on variantti stokastisesta gradientin laskeutumisesta ja tässä käytetään yhden harjoitusesimerkin sijasta näytteiden minierää.
Osa 2 - Syvän oppimisen haastattelut (Advanced)
Katsokaamme nyt syventäviä syvä oppimisen haastattelukysymyksiä.
7. Mitkä ovat pienerägradienttien laskeutumisen edut?
Vastaus:
Alla on minierägradienttien laskeutumisen edut
• Tämä on tehokkaampaa verrattuna stokastiseen gradientin laskeutumiseen.
• Yleistäminen etsimällä tasaiset minimit.
• Mini-erät antavat apua koko harjoittelujoukon kaltevuuden lähentämiseen, mikä auttaa meitä välttämään paikallisia minimiä.
8. Mikä on datan normalisointi ja miksi me tarvitsemme sitä?
Vastaus:
Datan normalisointia käytetään jälkivalmistuksen aikana. Tietojen normalisoinnin pääasiallinen motiivi on vähentää tai poistaa tietojen redundanssia. Tässä skaalataan arvoja, jotta ne sopivat tietylle alueelle paremman lähentymisen saavuttamiseksi.
Siirrymme seuraavaan syväoppimishaastattelu-kysymykseen.
9. Mikä on painon alustus hermoverkoissa?
Vastaus:
Painon alustaminen on yksi erittäin tärkeistä vaiheista. Huono painoalusta voi estää verkon oppimista, mutta painoarvojen paikkansapitäminen auttaa antamaan nopeamman lähentymisen ja paremman kokonaisvirheen. Biases voidaan yleensä alustaa nollaan. Painojen asettamisen sääntö on oltava lähellä nollaa olematta liian pieni.
10. Mikä on autokooderi?
Vastaus:
Autokooderi on itsenäinen koneoppimisalgoritmi, joka käyttää takaisinprosessointiperiaatetta, jossa tavoitearvot asetetaan yhtä suureiksi toimitetuille syötteille. Sisäisesti siinä on piilotettu kerros, joka kuvaa koodia, jota käytetään tulon esittämiseen.
Jotkut autoenkooderia koskevat keskeiset tosiasiat ovat seuraavat: -
• Se on ohjaamaton ML-algoritmi, joka on samanlainen kuin pääkomponenttianalyysi
• Se minimoi saman objektiivisen toiminnan kuin pääkomponenttianalyysi
• Se on hermoverkko
• Neuraaliverkon kohdelähtö on sen tulo
11. Onko OK yhdistää kerroksen 4 ulostulosta kerroksen 2 tuloon?
Vastaus:
Kyllä, tämä voidaan tehdä ottaen huomioon, että kerroksen 4 lähtö on edellisestä aikavaiheesta kuten RNN: ssä. Lisäksi meidän on oletettava, että edellinen syöttöerä korreloi joskus nykyisen erän kanssa.
Siirrymme seuraavaan syväoppimishaastattelu-kysymykseen.
12. Mikä on Boltzmann-kone?
Vastaus:
Boltzmann-konetta käytetään optimoimaan ongelman ratkaisu. Boltzmann-koneen tehtävänä on periaatteessa painojen ja määrän optimointi annetulle ongelmalle.
Joitakin tärkeitä seikkoja Boltzmann Machine -
• Se käyttää toistuvaa rakennetta.
• Se koostuu stokastisista neuroneista, jotka koostuvat yhdestä kahdesta mahdollisesta tilasta, joko 1 tai 0.
• Tässä olevat hermosolut ovat joko adaptiivisessa (vapaa tila) tai puristuneita (jäätyneessä tilassa).
• Jos sovellamme simuloitua hehkutusta erillisellä Hopfield-verkolla, siitä tulee Boltzmann Machine.
13. Mikä on aktivointitoiminnon rooli?
Vastaus:
Aktivointitoimintoa käytetään epälineaarisuuden lisäämiseen hermoverkkoon auttamalla sitä oppimaan monimutkaisempia toimintoja. Ilman jota hermoverkko pystyisi vain oppimaan lineaarista funktiota, joka on sen tulotietojen lineaarinen yhdistelmä.
Suositellut artikkelit
Tämä on opas luetteloon syvän oppimisen haastattelua koskevista kysymyksistä ja vastauksista, jotta hakija voi helposti hajottaa nämä syvän oppimisen haastattelua koskevat kysymykset. Voit myös katsoa seuraavia artikkeleita saadaksesi lisätietoja
- Opi kymmenen hyödyllisintä HBase-haastattelua koskevaa kysymystä
- Hyödyllisiä koneoppimishaastatteluun liittyviä kysymyksiä ja vastauksia
- 5 suosituinta tiedehaastattelukysymystä
- Tärkeitä Ruby-haastatteluun liittyviä kysymyksiä ja vastauksia