

Johdatus Apache Flumeen
Apache Flume on Data Ingestion Framework, joka kirjoittaa tapahtumapohjaisen tiedon Hadoopin hajautettuun tiedostojärjestelmään. On tunnettu tosiasia, että Hadoop käsittelee suuria tietoja, herää kysymys, kuinka eri web-palvelimilta tuotettu tieto siirretään Hadoop-tiedostojärjestelmään? Vastaus on Apache Flume. Flume on suunniteltu tapahtumapohjaisen datan suuren määrän tietojen syöttämistä Hadoopille.
Mieti tilannetta, jossa verkkopalvelimien määrä luo lokitiedostoja ja näiden lokitiedostojen on lähetettävä Hadoop-tiedostojärjestelmään. Flume kerää nämä tiedostot tapahtumina ja vie ne Hadoopiin. Vaikka Flumea käytetään siirtämiseen Hadoopille, ei ole tiukkaa sääntöä, jonka mukaan määränpään on oltava Hadoop. Flume pystyy kirjoittamaan muille kehyksille, kuten Hbase tai Solr.
Flume-arkkitehtuuri
Apache Flume -arkkitehtuuri koostuu yleensä seuraavista komponenteista:
- Flume Source
- Flume-kanava
- Flume-pesuallas
- Flume Agent
- Flume-tapahtuma
Katsokaamme lyhyesti kutakin Flume-komponenttia
1. Flume Source
Flume-lähde on läsnä tietolähteissä, kuten Face-kirja tai Twitter. Lähde kerää tietoja generaattorilta ja siirtää ne Flume Channel -kanavalle Flume-tapahtumien muodossa. Flume tukee erityyppisiä lähteitä, kuten Avro Flume Source - yhdistää Avro-porttiin ja vastaanottaa tapahtumia Avron ulkoiselta asiakkaalta, Thrift Flume Source - yhdistää Thrift-porttiin ja vastaanottaa tapahtumia ulkoisista Thrift-asiakasvirroista, Spooling Directory Source -lähteestä ja Kafka Flume Source -sivustosta.
2. Flume Channel
Välikauppaa, joka puskuroi Flume Source -lähetyksen tapahtumia, kunnes Sink kuluttaa ne, kutsutaan Flume Channeliksi. Kanava toimii välitietona Lähteen ja Sinkin välillä. Flume-kanavat ovat luonteeltaan transaktionaalisia.
Flume tukee tiedosto- ja muistikanavia. Tiedostokanava on luonteeltaan kestävä, mikä tarkoittaa, että kun data on kirjoitettu kanavalle, sitä ei menetetä, vaikka agentti käynnistyy uudelleen. Muistissa kanavatapahtumat tallennetaan muistiin, joten se ei ole kestävä, mutta luonteeltaan erittäin nopea.
3. Flume-pesuallas
Flume-pesuallas on läsnä tietovarastoissa, kuten HDFS, HBase. Flume-pesuallas kuluttaa tapahtumia kanavalta ja tallentaa ne kohdekauppaan kuten HDFS. Ei ole olemassa sellaista sääntöä, että pesualtaan pitäisi toimittaa tapahtumia Kauppaan, sen sijaan voimme konfiguroida sen siten, että pesuallas voi toimittaa tapahtumia toiselle edustajalle. Flume tukee erilaisia nieluja, kuten HDFS-pesuallas, pesän pesuallas, säästävä pesuallas, Avro-pesuallas.
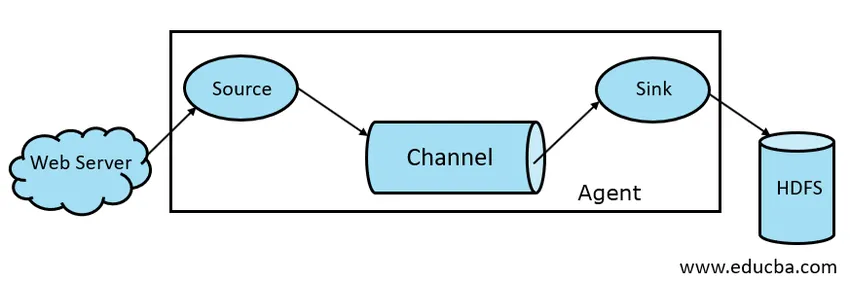
Kuva 1.1 Flume-perusarkkitehtuuri
4. Flume Agent
Flume-agentti on pitkäaikainen Java-prosessi, joka toimii Source - Channel - Sink -yhdistelmässä. Flumassa voi olla useampi kuin yksi agentti. Voimme pitää Flumea yhdistelmänä Flume-agentteja, jotka ovat jakautuneet luonnossa.
5. Flume-tapahtuma
Tapahtuma on Flume-yksikössä siirretty tietoyksikkö . Dataobjektin yleistä esitystä Flumessa kutsutaan tapahtumaksi. Tapahtuma koostuu tavuyksikön hyötykuormasta valinnaisilla otsikoilla.
Flumin toiminta
Flume-agentti on java-prosessi, joka koostuu Source - Channel - Sinkistä sen yksinkertaisimmassa muodossa. Lähde kerää tietoja tiedonkeruulaitteelta tapahtumien muodossa ja toimittaa sen kanavalle. Lähde voi toimittaa useille kanaville vaatimuksen mukaan. Tuuletin on prosessi, jossa yksi lähde kirjoittaa useille kanaville, jotta ne voivat toimittaa useille nieluille.
Tapahtuma on Flumessa lähetettävän tiedon perusyksikkö. Kanava puskuroi tietoja, kunnes Sink on ne syönyt. Sink kerää tiedot kanavalta ja toimittaa ne keskitettyyn tallennustilaan, kuten HDFS tai Sink voi välittää kyseiset tapahtumat toiselle Flume-agentille vaatimuksen mukaisesti.
Flume tukee tapahtumia. Luotettavuuden saavuttamiseksi Flume käyttää erillisiä transaktioita lähteestä kanavalle ja kanavasta uppoon. Jos tapahtumia ei toimiteta, tapahtuma kumotaan ja toimitetaan myöhemmin uudelleen.
Ymmärtääksemme Flume-toimintoa, ottakaamme esimerkki Flume-kokoonpanosta, jossa lähde on spooling-hakemisto ja upotus on Hdfs. Tässä esimerkissä Flume-agentti on yksinkertaisimmassa muodossa, ts. Yhden lähteen, kanavan ja pesimen topologia, joka on määritetty Java-ominaisuustiedoston avulla.
agent1.sources = source1
agent1.sinks = sink1
agent1.channels = channel1
agent1.sources.source1.channels = channel1
agent1.sinks.sink1.channel = channel1
agent1.sources.source1.type = spooldir
agent1.sources.source1.spoolDir = /tmp/spooldir
agent1.sinks.sink1.type = hdfs
agent1.sinks.sink1.hdfs.path = /tmp/flume
agent1.channels.channel1.type = file
Yllä olevassa kokoonpanoesimerkissä agentti on emäs, jolla määrittelemme muut ominaisuudet. Lähde1 ja nielu1 ja kanava1 ovat lähteen, nieluksen ja kanavan nimet, ja niiden tyypit ja sijainnit mainitaan vastaavasti.
Apache Flume -sovelluksen edut
- Flume on luonteeltaan skaalautuva, luotettava ja vikasietoinen. Näitä ominaisuuksia käsitellään yksityiskohtaisesti alla
- Skaalautuva - Flume on skaalautuva vaakatasossa, ts. Voimme lisätä uusia solmuja vaatimuksemme mukaan
- Luotettava - Apache Flume tukee tapahtumia ja varmistaa, että tietoja ei menetetä tiedonsiirtoprosessissa. Sillä on erilaisia tapahtumia lähteestä kanavaan ja kanavasta lähteeseen.
- Flume on muokattavissa ja tarjoaa tukea eri lähteille ja nieluille, kuten Kafka, Avro, kelaushakemisto, säästäväisyys jne.
- Flume-yksikössä yksi lähde voi lähettää dataa useille kanaville ja nuo kanavat vuorostaan lähettävät datan useille nieluille, joten yksi lähde voi lähettää dataa useille nieluille. Tämän mekanismin nimi on Fan out. Flume tukee myös Fan out -toimintoa.
- Flume tarjoaa tasaisen tiedonsiirron, ts. Jos datan lukemisen nopeus kasvaa ja sitten myös datan kirjoitusnopeus kasvaa.
- Vaikka Flume yleensä kirjoittaa tietoja keskitettyyn tallennustilaan, kuten HDFS tai Hbase, voimme määrittää Flume vaatimuksemme mukaan siten, että Sink voi kirjoittaa tietoja toiselle edustajalle. Tämä osoittaa Flumen joustavuuden
- Apache Flume on avoimen lähdekoodin luonne.
johtopäätös
Tässä Flume-artikkelissa käsitellään yksityiskohtaisesti Flume-komponentteja ja Flumen toimintaa. Flume on joustava, luotettava ja skaalautuva alusta tiedonsiirtoon keskitettyyn kauppaan, kuten HDFS. Sen kyky integroitua erilaisiin sovelluksiin, kuten Kafka, Hdfs, Thrift, tekee siitä käyttökelpoisen vaihtoehdon tietojen syöttämiselle.
Suositellut artikkelit
Tämä on opas Apache Flumeen. Tässä keskustellaan Apache Flume -sovelluksen arkkitehtuurista, toiminnasta ja eduista. Saatat myös katsoa seuraavia artikkeleita saadaksesi lisätietoja -
- Mikä on Apache Flink?
- Ero Apache Kafka ja Flume välillä
- Big Data -arkkitehtuuri
- Hadoop-työkalut
- Opi erilaisia JavaScript-tapahtumia