

Eroja Sqoopin ja Flumin välillä
Sqoop on tuote Apache-ohjelmistosta. Sqoop poimii hyödyllistä tietoa Hadoopista ja siirtää sitten ulkoisiin tietovarastoihin. Sqoopin avulla voimme tuoda tietoja RDBMS: stä tai keskusyksiköstä HDFS: ään. Flume on myös Apache-ohjelmistosta. Se kerää ja siirtää luodut rekursiiviset tiedot. Apache Flume ei rajoitu vain lokitietojen yhdistämiseen, vaan tietolähteet ovat muokattavissa, joten Flumea voidaan käyttää valtavien tietomäärien siirtämiseen. Paras tapa kerätä, yhdistää ja siirtää suuria määriä tietoja Hadoopin hajautetun tiedostojärjestelmän ja RDBMS: n välillä on käyttää työkaluja, kuten Sqoop tai Flume.
Keskustelemme näistä kahdesta yleisesti käytetystä työkalusta edellä mainittuun tarkoitukseen.
Mikä on Sqoop
Sqoopin käyttämiseksi käyttäjän on määritettävä työkalun käyttäjä, jota haluat käyttää, ja argumentit, jotka hallitsevat tiettyä työkalua. Voit sitten viedä tiedot takaisin RDBMS: ään Sqoopin avulla. Sqoopin vientitoiminnoilla poistetaan hyödyllistä tietoa Hadoopista ja viedään ne ulkoisiin jäsenneltyihin tietovarastoihin. Se toimii eri tietokantojen, kuten Teradata, MySQL, Oracle, HSQLDB, kanssa.
- Sqoop-arkkitehtuuri: -
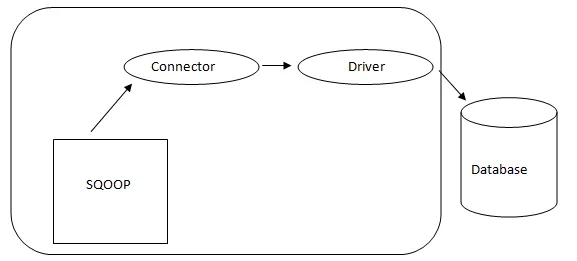
Sqoopin arkkitehtuuri
Sqoopin liitin on tietyn tietokantalähteen liitännäinen, joten on olennaista, että se on osa Sqoopin perustamista. Huolimatta siitä, että ohjaimet ovat tietokantakohtaisia kappaleita ja jakelua eri tietokantatoimittajien välillä, Sqoop itse mukana toimitetaan erityyppisillä liittimillä, joita käytetään vallitsevaan tietokanta- ja tietovarastointijärjestelmään. Siksi Sqoop toimittaa myös monenlaisia liittimiä laatikosta. Sqoop tarjoaa kytkettävän komponentin ihanteelliseen verkkoon ja ulkoiseen järjestelmään. Sqoop-sovellusliittymä tarjoaa hyödyllisen rakenteen uusien liittimien kokoamiseksi, ja siksi kaikki tietokantaliittimet voidaan pudottaa Sqoopin asennukseen liitettävyyden aikaansaamiseksi eri tietojärjestelmiin.
Mikä on Flume
Apache Flume ei rajoitu vain lokitietojen yhdistämiseen, vaan tietolähteet ovat muokattavissa, joten Flumea voidaan käyttää kuljettamaan valtavia määriä tietoja, mukaan lukien, mutta rajoittumatta, sähköpostiviestit, sosiaalisen median luomat tiedot, verkkoliikennetiedot ja melkein kaikki tietolähde mahdollinen.
Flume-arkkitehtuuri: - Flume-arkkitehtuuri perustuu moniin ydinkonsepteihin:
- Flume Event - sitä edustaa tiedonsiirtoyksikkö, jolla on tavu hyötykuorma ja merkkijonojoukot valinnaisilla merkkijonot. Flume pitää tapahtumaa vain yleisenä tavujoukkona.
- Flume Agent - Se on JVM-prosessi, joka isännöi komponentteja, kuten kanavia, pesuallasta ja lähteitä. Sillä on mahdollisuus vastaanottaa, tallentaa ja välittää tapahtumia ulkoisesta lähteestä seuraavalle tasolle.
- Flume Flow - se on ajankohta, jolloin tapahtuma luodaan.
- Flume Client - se tarkoittaa käyttöliittymää, jossa asiakas toimii tapahtuman lähtöpisteessä ja toimittaa sen Flume-agentille.
- Lähde - Lähde on lähde, joka kuluttaa tietyn muodon tapahtumia ja toimittaa sen tietyn mekanismin kautta.
- Kanava - se on passiivinen myymälä, jossa järjestetään tapahtumia, kunnes pesuallas poistaa sen edelleen kuljetusta varten.
- Allas - Se poistaa tapahtuman kanavalta ja laittaa sen ulkoiseen arkistoon, kuten HDFS. Se tukee tällä hetkellä teksti- ja sekvenssitiedostojen luomista ja tukee molempien tiedostotyyppien pakkaamista.
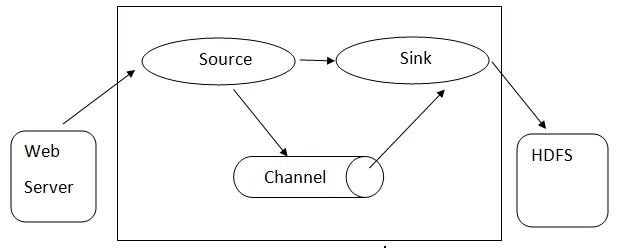
Flumen arkkitehtuuri
Head to Head -vertailu Sqoop vs Flume (Infografia)
Alla on 7 parhainta vertailua Sqoop vs. Flume välillä

Tärkeimmät erot Sqoop vs. Flume välillä
Tiedämme nyt, että Sqoop vs. Flume -tuotteiden välillä on monia eroja, tässä on alla esitetyt tärkeimmät erot niiden välillä -
1. Sqoop on suunniteltu vaihtamaan joukkotietoja Hadoopin ja relaatiotietokannan välillä.
Flumea käytetään tietojen keräämiseen eri lähteistä, jotka tuottavat tietoja tietystä käyttötapauksesta, ja sitten tämän suuren tietomäärän siirtäminen hajautetuista resursseista yhteen keskitettyyn arkistoon.
2. Sqoop sisältää myös joukon komentoja, joiden avulla voit tarkistaa työskentelemäsi tietokannan. Siksi voimme pitää Sqoopia kokoelmana siihen liittyviä työkaluja.
Kun päivämäärää kerätään, Flume skaalaa tietoja vaakatasossa ja useita Flume-agentteja voidaan asettaa toimintaan päivämäärän keräämiseksi ja aggregoimiseksi. Sen jälkeen datalokit siirretään keskitettyyn tietovarastoon, ts. Hadoop Distributed File System (HDFS).
3. Tärkein tekijä Flume-laitteen käytössä on, että tietoja on tuotettava jatkuvasti ja suoratoistoisesti. Samoin Sqoop soveltuu parhaiten tilanteisiin, joissa tietosi elää tietokantajärjestelmissä, kuten MySQL, Oracle, Teradata, PostgreSQL
Sqoop vs Flume (vertailutaulukko)
| Vertailun perusteet | SQOOP | Flume |
|
Perusluonto | Sqoop toimii hyvin kaikkien RDBMS-järjestelmien kanssa, joissa on JDBC (Java Database Connectivity), kuten Oracle, MySQL, Teradata jne. | Flume toimii hyvin streaming-tietolähteessä, joka tuottaa jatkuvasti kuten lokit, JMS, hakemisto, kaatumisraportit jne. |
| Tietovirta | Sqoop, jota käytetään erityisesti rinnakkaiseen tiedonsiirtoon. Tästä syystä lähtö voi olla useassa tiedostossa | Flumea käytetään datan keräämiseen ja yhdistämiseen, koska se on hajautunut. |
| Ohjatut tapahtumat | Sqoop ei johda tapahtumista. | Flume on täysin tapahtumavetoinen. |
| Arkkitehtuuri | Sqoop noudattaa liitinpohjaista arkkitehtuuria, joka tarkoittaa liittimiä, osaa muodostaa yhteyden toiseen tietolähteeseen. | Flume noudattaa edustajapohjaista arkkitehtuuria, jossa siihen kirjoitettu koodi tunnetaan edustajana, joka vastaa datan noutamisesta. |
| Missä käyttää | Käytetään ensisijaisesti tietojen nopeampaan kopiointiin ja sitten tietojen analyyttisten tulosten tuottamiseen. | Käytetään yleensä tiedon keräämiseen, kun yritykset haluavat analysoida malleja, perussyitä tai tunteellisia analyysejä lokien ja sosiaalisen median avulla. |
| Esitys | Se vähentää liiallisia tallennus- ja käsittelykuormia siirtämällä ne muihin järjestelmiin ja on nopea suorituskyky. | Flume on vikasietoinen, kestävä ja siinä on kestävä luotettavuusmekanismi varautumisen ja palautumisen kannalta. |
| Julkaisuhistoria | Apache Sqoopin ensimmäinen versio julkaistiin maaliskuussa 2012. Nykyinen vakaa julkaisu on 1.4.7 | Apache Flume -sovelluksen ensimmäinen vakaa versio 1.2.0 julkaistiin kesäkuussa 2012. Nykyinen vakaa versio on Apache Flume Versio 1.8.0. |
Johtopäätös - Sqoop vs Flume
Kuten edellä opit Sqoop ja Flume, ovat pääasiassa kahta Data Ingestion -työkalua, joka on Big Data -maailma. Jos joudut syöttämään tekstitietoja lokitiedoista Hadoop / HDFS-tiedostoon, Flume on oikea valinta siihen. Jos tietojasi ei luoda säännöllisesti, Flume toimii edelleen, mutta se on ylimääräinen tapaus tässä tilanteessa. Samoin Sqoop ei sovellu parhaiten tapahtumapohjaiseen tietojenkäsittelyyn.
Suositellut artikkelit
Tämä on opas eroihin Sqoop vs Flume, niiden merkitys, Head to Head vertailu, keskeiset erot, vertailutaulukko ja johtopäätökset. Tämä artikkeli koostuu kaikista hyödyllisistä eroista Sqoopin ja Flumin välillä. Voit myös katsoa seuraavia artikkeleita saadaksesi lisätietoja
- Hadoop vs Teradata - Hyödyllisiä eroja oppimiseen
- 5 tärkeintä eroa Apache Kafka ja Flume välillä
- Big Data vs. Apache Hadoop - 4 suosituinta vertailua, joka sinun on opittava
- 5 tärkeintä eroa Apache Kafka ja Flume välillä
- Tärkeä tekstin louhinta vs. luonnollisen kielen käsittely - viisi vertailua