

Johdatus Hadoop-arkkitehtuuriin
Hadoop Architecture on avoimen lähdekoodin kehys, joka auttaa käsittelemään suuria tietoaineistoja helposti. Se auttaa luomaan sovelluksia, jotka käsittelevät valtavaa dataa nopeammin. Se hyödyntää hajautettuja laskentakonsepteja, joissa tiedot jakautuvat klusterin eri solmuihin. Hadoopilla rakennetut sovellukset hyödyntävät hyödykkeitä. Nämä tietokoneet ovat helposti saatavana markkinoilta halvalla. Tämä tulos saavuttaa suuremman laskentatehon alhaisilla kustannuksilla. Kaikki Hadoopissa olevat tiedot sijaitsevat HDFS: ssä paikallisen tiedostojärjestelmän sijasta. HDFS on Hadoop-hajautettu tiedostojärjestelmä. Tämä malli perustuu datapaikkaan, jossa laskennallinen logiikka lähetetään dataa sisältävän klusterin solmuille. Tämä logiikka on vain logiikkaa, joka kokoaa ohjelman.
Hadoop-arkkitehtuuri
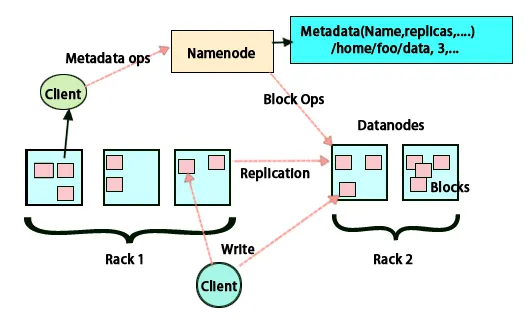
Tämän arkkitehtuurin perusidea on, että koko varastointi ja käsittely suoritetaan kahdessa vaiheessa ja kahdella tavalla. Ensimmäinen vaihe on prosessointi, joka suoritetaan Map vähentää ohjelmointia, ja toinen tapa on tallentaa tiedot, jotka tehdään HDFS: llä. Siinä on isäntä-orja-arkkitehtuuri tallennusta ja tietojenkäsittelyä varten. Hadoopin tietojen tallennuksen isäntäsolmu on nimissolmu. Siellä on myös isäntäsolmu, joka suorittaa seurannan ja suuntaa tietojen käsittelyn hyödyntämällä Hadoop Map Reduce -sovellusta. Orjat ovat muita Hadoop-klusterin koneita, jotka auttavat tietojen tallentamisessa ja suorittavat myös monimutkaisia laskelmia. Jokaiselle slave-solmulle on osoitettu tehtäväseuranta ja datosolmulla on job tracker, joka auttaa prosessien suorittamisessa ja synkronoinnissa tehokkaasti. Tämän tyyppinen järjestelmä voidaan asettaa joko pilveen tai paikan päällä. Nimi-solmu on yksi vikakohta, kun se ei toimi korkean saatavuuden tilassa. Hadoop-arkkitehtuurissa on myös mahdollisuus ylläpitää stand by Name -solmua järjestelmän suojaamiseksi virheiltä. Aikaisemmin oli toissijaisia nimisolmuja, jotka toimivat varmuuskopiona, kun ensisijainen nimisolmu oli alhaalla.
FSimage ja Muokkaa lokia
FSimage- ja Edit Log -toiminnot varmistavat tiedostojärjestelmän metatietojen pysyvyyden pysyäkseen ajan tasalla kaikista tiedoista, ja nimisolmu tallentaa metatiedot kahteen tiedostoon. Nämä tiedostot ovat FSimage ja muokkausloki. FSimagen tehtävä on pitää täydellinen tilannekuva tiedostojärjestelmästä tiettynä ajankohtana. Järjestelmään jatkuvasti tehtävät muutokset on pidettävä kirjaa. Nämä asteittaiset muutokset, kuten tiedoston uudelleennimeäminen tai tiedostoon liittäminen, tallennetaan muokkauslokiin. Kehys tarjoaa paremman vaihtoehdon sen sijaan, että luodaan uusi FSimage joka kerta. Parempi vaihtoehto on mahdollisuus tallentaa tiedot samalla kun uusi tiedosto FSimagelle. FSimage luo uuden tilannekuvan joka kerta, kun muutoksia tehdään. Jos Nimi-solmu epäonnistuu, se voi palauttaa aiemman tilansa. Toissijainen nimisolmu voi myös päivittää kopionsa aina, kun FSimage-sovelluksessa tapahtuu muutoksia ja muokata lokit. Siten se varmistaa, että vaikka nimissolmu on alhaalla, toissijaisen nimisolmun läsnä ollessa ei tapahdu mitään tietojen menetystä. Nimesolmu ei vaadi näiden kuvien lataamista toissijaiseen nimisolmuun.
Tietojen kopiointi
HDFS on suunniteltu käsittelemään tietoja nopeasti ja tarjoamaan luotettavaa tietoa. Se tallentaa tietoja koneisiin ja suuriin klustereihin. Kaikki tiedostot tallennetaan sarjassa lohkoja. Nämä lohkot toistetaan vikasietoisuuden vuoksi. Käyttäjät voivat päättää lohkon koon ja replikaatiotekijän ja määrittää käyttäjän vaatimusten mukaisesti. Oletusarvon mukaan replikointikerroin on 3. Replikointikerroin voidaan määrittää tiedoston luomishetkellä ja sitä voidaan muuttaa myöhemmin. Kaikki päätökset, jotka koskevat näitä replikoja, tehdään nimissolmulla. Nimesolmu lähettää sykelyöntiä ja estää raporttia säännöllisin väliajoin klusterin kaikille datasolmuille. Sydämen sykkeen saaminen merkitsee, että datasolmu toimii oikein. Lohkoraportti määrittelee luettelon kaikista datasolmussa olevista lohkoista.
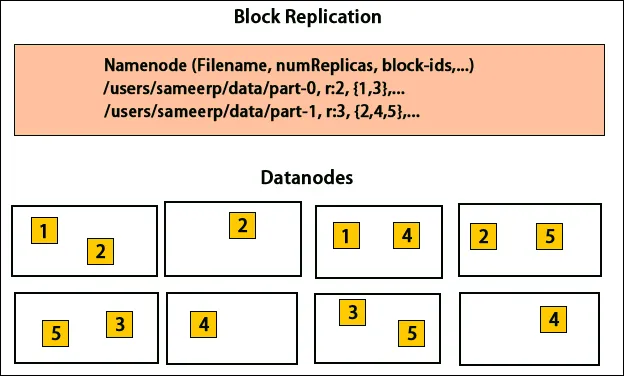
Kopioiden sijoittaminen
Kopioiden sijoittaminen on erittäin tärkeä tehtävä Hadoopissa luotettavuuden ja suorituskyvyn kannalta. Kaikki eri datalohot sijoitetaan erilaisiin telineisiin. Replikan sijoituksen toteuttaminen voidaan suorittaa luotettavuuden, saatavuuden ja verkon kaistanleveyden käytön mukaan. Tietokoneiden klusteri voidaan levittää eri telineille. Samaan telineeseen voidaan sijoittaa enintään kaksi solmua. Kolmas kopio tulisi asettaa toiselle telineelle datan luotettavuuden lisäämiseksi. Telineen kaksi solmua kommunikoivat eri kytkimien kautta. Nimesolmussa on kunkin datasolmun telineiden tunnus. Mutta kaikkien solmujen sijoittaminen erilaisiin telineisiin estää kaiken tiedon katoamisen ja sallii useiden telineiden kaistanleveyden käytön. Se vähentää myös telineiden välistä liikennettä ja parantaa suorituskykyä. Myös telinevian todennäköisyys on hyvin pieni verrattuna solmuvikaan. Se vähentää kokonaisverkon kaistanleveyttä, kun tietoja luetaan kahdesta erillisestä telineestä kolmen sijaan.
Kartta pienennä
Map Reduce -sovellusta käytetään HDFS: ään tallennettujen tietojen käsittelemiseen. Se kirjoittaa hajautettua tietoa hajautettuihin sovelluksiin, mikä varmistaa suurten tietomäärien tehokkaan käsittelyn. Ne käsittelevät suurissa klustereissa ja vaativat hyödykettä, joka on luotettava ja vikasietoinen. Map-reduktin ydin voi olla kolme operaatiota, kuten kartoitus, parien kerääminen ja tuloksena olevan tiedon sekoittaminen.
Johtopäätös - Hadoop-arkkitehtuuri
Hadoop on avoimen lähdekoodin kehys, joka auttaa vikasietoisessa järjestelmässä. Se voi tallentaa suuria määriä dataa ja auttaa luotettavien tietojen tallentamisessa. Kaksi osaa tietojen tallentamisesta HDFS: ään ja käsittelemiseen kartan avulla vähentävät apua asianmukaisessa ja tehokkaassa työskentelyssä. Sillä on arkkitehtuuri, joka auttaa hallitsemaan kaikkia datalohkoja ja myös viimeisintä kopiota tallentamalla se FSimage- ja muokkauslokiin. Replikointikerroin auttaa myös tietojen kopioinnissa ja saamisessa takaisin vikatilanteissa. HDFS siirtää myös poistetut tiedostot roskakoriin hakemaan tilaa optimaalisesti.
Suositellut artikkelit
Tämä on ollut opas Hadoop-arkkitehtuurille. Tässä olemme keskustelleet arkkitehtuurista, kartan pienentämisestä, kopioiden sijoittamisesta, datan replikoinnista. Voit myös käydä läpi muiden ehdotettujen artikkeleidemme saadaksesi lisätietoja -
- Ryhdy Hadoop-kehittäjäksi
- Johdanto Androidiin
- Mikä on Tableau? | Yleiskatsaus
- Mikä on MapReduce Hadoopissa?