

Johdanto hajautukseen DBMS-järjestelmässä
Kun puhumme valtavasta tietokantarakenteesta ja niiden monimutkaisuudesta, on erittäin tehotonta etsiä kaikkia indeksejä, ja halutun datan saavuttaminen muuttuu erittäin epämääräiseksi ja monimutkaiseksi mahdollisuudeksi. Hyödyntämällä hajautustekniikkaa nämä tilat voidaan saavuttaa ja voidaan osoittaa suora osoitin tietämään tietyn tietueen tarkka ja suora sijainti levyllä käyttämättä monimutkaista hakemistorakennetta. Hajaustekniikan tapauksessa tiedot tallennetaan datalohkojen muodossa, joiden osoite generoidaan hyödyntämällä tyypillisesti hajautusfunktiota kutsuttavaa toimintoa. Paikka muistissa, jossa tämä sijaitsee ja tietueet tallennetaan, tunnetaan datalohkoina tai data-kauhana.
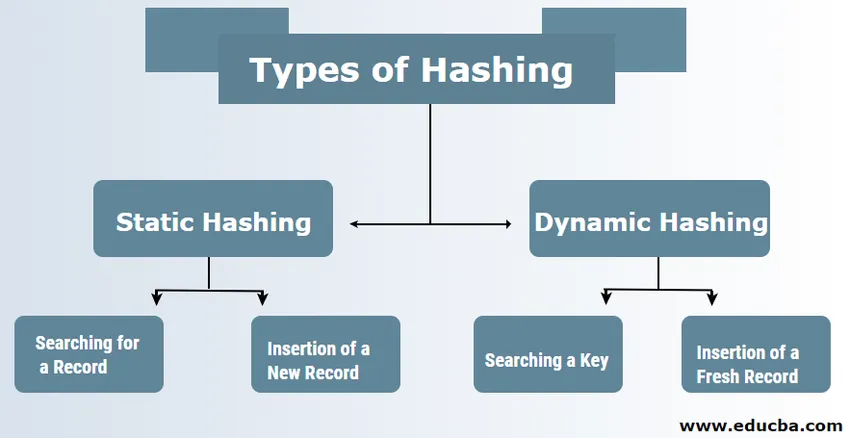
Hajauttamisen tyypit DBMS-järjestelmässä
DBMS: ssä on tyypillisesti kahta tyyppiä hajautustekniikoita:
1. Staattinen hajautus
2. Dynaaminen hajautus
1) Staattinen hajautus
Staattisen hajautuksen tapauksessa muodostettu tietojoukko ja kauhan osoite ovat samat. Tämä tarkoittaa, että jos yritämme luoda osoitteen USER_ID = 113 hyödyntämällä hajautusfunktiomoduulia 5, se antaa meille tulokselle 3 aina saman näköisen kauhan osoitteen. Tässä tapauksessa toimitetun kauhan osoitteessa ei muutu. Siksi kauhojen lukumäärä pysyy vakiona koko toiminnan ajan.
Staattisesti tyypitetyn hashingin toiminta
a. Tietueen etsiminen: Jos tietue on löydettävä, käytetään täsmälleen samaa hajautustoimintoa hakemaan data-kauhan osoite ja polku tallennettavan tiedon kanssa.
b. Uuden tietueen lisääminen : Jos uusi ja tuore tietue asetetaan taulukkoon, tuoreelle tietueelle luodaan osoite hajautusavaimen perusteella, jolloin tietue tallennetaan kyseiseen sijaintiin.
- Tietueen poistaminen: Jotta tietue voidaan poistaa, ensin se on haettava, joka voidaan poistaa. Kun tämä tehtävä on suoritettu, kyseisen muistiosoitteen tietueet on poistettava.
- Tietueen päivitys: Tietueen päivittämiseksi etsimme ensin tietuetta käyttämällä hash-pohjaista toimintoa, ja kun se on tehty, sitten tietorekisterimme voidaan sanoa olevan päivitetyssä tilassa. Jotta voimme lisätä uuden tietueen tiedostoon ja hash-pohjaisesta toiminnosta ja data-kauhasta generoitu osoite ei ole tyhjä tai jos tiedot ovat jo läsnä annetussa osoitteessa. Tätä tilannetta, joka syntyy erityisesti staattisen hajautuksen yhteydessä, voidaan kutsua paremmin kauhan ylivuodosta, ja siksi tämän ongelman ratkaisemiseksi käytetään joitain tapoja, kuten:
(i) Avoin hajautus : Jos hajautustoiminto luo osoitteen, jolle tiedot voidaan nähdä jo tallennetussa tilassa, tällöin kauhan seuraava taso allokoidaan automaattisesti. Tätä mekanismia voidaan kutsua lineaariseksi koetustekniikaksi.
Esimerkiksi, jos R3 on uusi osoite, joka tarvitaan laittamaan, niin hash-pohjainen toiminto generoi osoitteen numerona 102 R3-osoitteelle. Luotu osoite on täydessä tilassa, ja siksi järjestelmän on tarkoitus etsiä uutta tietoryhmää, joka on 113, ja osoittaa R3 kyseiselle data-ryhmälle.
(ii) Suljettu hajautus: Kun kauhat ovat täysin täynnä, uudelle kauhalle osoitetaan sitten tietylle hajotustulokselle, joka yhdistetään heti aiemmin suoritetun jälkeen, ja siksi tätä menetelmää kutsutaan Ylivuotoketjutustekniikaksi.
Esimerkiksi R3 on uusi osoite, joka vaaditaan laittamaan uuteen taulukkoon. Hajautustoimintoa käytetään osoitteen generoimiseksi numerona 110 siihen. Tämä ämpäri puolestaan on täynnä eikä siksi voi vastaanottaa uutta tietoa, ja siksi uusi ämpäri asetetaan lopussa 100: n jälkeen.
2) Dynaaminen hajautus
Tällaista hash-pohjaista menetelmää voidaan käyttää ratkaisemaan staattisen perustuvan hajauttamisen perusongelmat, kuten esimerkiksi kauhan ylivuoto, koska data-kauhat voivat kasvaa ja kutistua koon ollessa enemmän tilaa optimoiva tekniikka, ja siksi sitä kutsutaan laajennettavaksi hash-pohjainen menetelmä. Tässä menetelmässä hajautus tehdään dynaamiseksi, mikä tarkoittaa, että insertioaktiivisuus tai poisto on sallittua antamatta heikkoa suorituskykyä.
a. Avaimen etsiminen: Laske tarvittavan avaimen hash-pohjainen osoite ja tarkista, kuinka monta bittiä käytetään hakemistossa, joka tunnetaan nimellä i. Sitten ne, jotka ovat vähiten merkitseviä I-biteistä, otetaan hakemistosta, joka antaa käsityksen hakemiston hakemistosta. Hyödyntämällä indeksiarvoa, siirry hakemistoon löytääksesi kauhan osoitteen nykyisiä tietueita varten.
b. Tuoreen tietueen lisääminen : Aluksi sinun on noudatettava täsmälleen samaa hakumenettelyä, jonka on päätyttävä johonkin ämpäriin. Etsi tilaa kyseisestä kauhasta ja laita tietueet sen sisälle. Jos luotu ämpäri on täydellinen ja täynnä, ämpäri jaetaan ja tietueet jaetaan uudelleen.
Esimerkiksi numeroiden 2 ja 4 kaksi viimeistä bittiä ovat 00. Joten ne menevät kauhaan B0 ja niin edelleen moduulifunktion mukaan. Näppäimellä 9 on osoite 10001, jonka on oltava läsnä ensimmäisessä kauhassa, mutta se jaetaan ja siirtyy uuteen kauhaan B1, ja tämä jatkuu, kunnes kaikki kauhat ja avaimet ovat dynaamisesti hajautettu. Hajautustoimintoa käytetään tavalla, jossa hajautustoiminnolla valitaan sarake ja sen arvo osoitteen luomiseksi. Enimmäisajat hash-toiminto käyttää ensisijaista avainta, jota puolestaan käytetään datalohkon osoitteiden luomiseen. Se on yksinkertainen matemaattinen toiminto, jossa pääavainta voidaan pitää myös datalohkon osoitteena, mikä tarkoittaa, että jokainen rivi, jolla on sama osoite kuin ensisijaisella avaimella, tallennetaan datalohkoon.
Suositellut artikkelit
Tämä on opas Hashingiin DBMS-järjestelmässä. Tässä keskustellaan johdannosta ja erityyppisistä hajauttamisista DBMS: ssä, joka sisältää staattisen ja dynaamisen hajautuksen yhdessä esimerkkien kanssa. Saatat myös katsoa seuraavia artikkeleita saadaksesi lisätietoja -
- Tietomallit DBMS: ssä
- DBMS-järjestelmän edut
- Tietojen integroinnin työkalu
- Mikä on RDBMS?