

Splunk-haastattelun kysymykset ja vastaukset - Johdanto
Joten olet vihdoin löytänyt unelmatyösi Splunkista, mutta mietit miten Splunk-haastattelu saadaan halki ja mitkä voisivat olla todennäköiset Splunk-haastattelukysymykset vuodelle 2018. Jokainen haastattelu on erilainen ja myös työn laajuus on erilainen. Pitäen tämän mielessä olemme suunnitelleet yleisimmät Splunk-haastattelua koskevat kysymykset ja vastaukset vuodelle 2018 auttamaan sinua menestymään haastattelussa.Alla on hyödyllisimmät Splunk-haastattelua koskevat kysymykset ja vastaukset. Nämä tärkeimmät kysymykset on jaettu kahteen osaan seuraavasti:
Osa 1 - Splunk-haastattelukysymykset (perus)
Tämä ensimmäinen osa kattaa Splunk-haastattelun peruskysymykset ja vastaukset.
1. Mikä on Splunk? Miksi Splunkia käytetään koneiden tietojen analysointiin?
Vastaus:
Yksi käytetyimmistä analytiikkatyökaluista on Microsoft Excel, ja sen haittana on, että Excel pystyy lataamaan vain 1048576 riviä ja koneetiedot ovat yleensä valtavia. Splunk on kätevä käsiteltäessä koneella tuotettua dataa (iso data). Palvelimien, laitteiden tai verkkojen tiedot voidaan helposti ladata Splunkiin ja voidaan analysoida tarkistaaksesi mahdollisen uhan näkyvyyden, vaatimustenmukaisuuden, turvallisuuden jne. Sitä voidaan myös käyttää sovellusten seurantaan.
2. Selitä kuinka Splunk toimii
Vastaus:
Tämä on yleinen Splunk-haastattelukysymys, jota haastattelussa esitetään. Tiedot ladataan Splunkiin kuormatraktorilla, joka toimii rajapintana Splunk-ympäristön ja ulkomaailman välillä, sitten nämä tiedot välitetään indeksoijalle, missä tiedot joko tallennetaan paikallisesti tai pilveen. Indeksi indeksoi konetiedot ja tallentaa ne palvelimelle. Hakupää on graafinen käyttöliittymä, jonka Splunk tarjoaa tietojen etsimiseen ja analysointiin (etsii, visualisoi, analysoi ja suorittaa useita muita toimintoja).
Käyttöönottopalvelin hallitsee kaikkia Splunk-komponentteja, kuten indeksoija, huolitsija ja hakupää Splunk-ympäristössä. 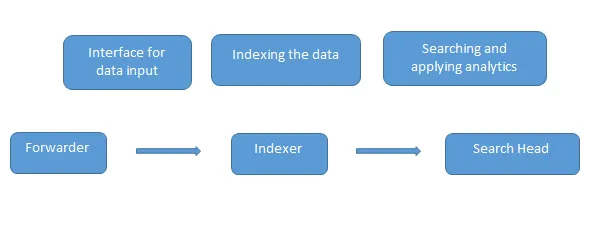
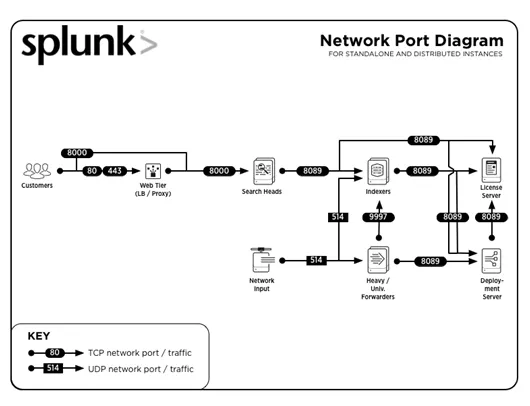
3. Mitkä ovat yleiset porttinumerot, joita Splunk käyttää?
Vastaus :
Yleiset porttinumerot, joilla palveluita ajetaan (oletuksena), ovat:
| palvelu | Porttinumero |
| Hallinta / REST-sovellusliittymä | 8089 |
| Hakupää / hakemisto | 8000 |
| Hakupää | 8065, 8191 |
| Indeksi-klusterin vertaisolmu / hakupää klusterin jäsen | 9887 |
| Indexer | 9997 |
| Indexer / Kuormatraktori | 514 |
Siirrytään seuraavaan Splunk-haastattelukysymykseen.
4. Miksi käyttää vain Splunkia?
Vastaus:
Splunkille on monia vaihtoehtoja, jotka antavat sille paljon kilpailua, jotkut niistä ovat alla:
• ELK / Logstash (avoin lähdekoodi)
Elastista hakua käytetään etsimiseen, kuten Splunkissa oleva hakupää, Log Stash on tietojen keräämiseen, joka on samanlainen kuin Splunkissa käytetty kuormatraktori, ja Kibanaa käytetään tietojen visualisointiin (hakupää tekee saman Splunkissa)
• Graylog (avoimen lähdekoodin kaupallinen versio)
Graylog on jälleen yksi työkalu, joka sai nimen viime vuonna julkaisullaan 1.0. Samoin kuin ELK-pinossa, Graylogilla on myös erilaisia komponentteja, joissa se käyttää Elasticsearchia ydinkomponenttinsa, mutta tiedot tallennetaan Mongo DB: hen ja Apache Kafka -sovellukseen. Sillä on kaksi versiota, yksi ydinversio, joka on saatavana ilmaiseksi, ja yritysversio, joka sisältää toimintoja, kuten arkistoinnin.
• Sumo Logic (pilvipalvelu)
Joten mikä tekee Splunkista parhaan kaikista, on se, että Splunk tulee yhtenä pakettina tiedonkeruulaitetta, varastoa ja sisäänrakennettua analytiikkatyökalua. Splunk on myös skaalautuva ja tarjoaa tukea / ammatillista apua yritysversioonsa.
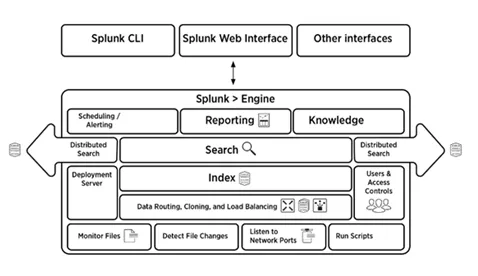
5. Selitä lyhyesti Splunk-arkkitehtuuri
Vastaus:
Alla oleva kuva antaa lyhyen yleiskuvan Splunk-arkkitehtuurista ja sen komponenteista.
Osa 2 - Splunk-haastattelukysymykset (Advanced)
Katsokaamme nyt edistyneitä Splunk-haastattelukysymyksiä.
6. Mitkä ovat Splunk-arkkitehtuurin komponentit?
Vastaus:
Splunk-arkkitehtuurissa on neljä komponenttia. He ovat:
- Indeksi: Indeksoi koneen tiedot
- Huolitsija: Eteenpäin lokit hakemistoon
- Hakupää: Tarjoaa GUI-hakua
- Käyttöönottopalvelin: Hallitsee Splunk-komponentteja (hakemisto, huolitsija ja hakupää) hajautetussa ympäristössä
7. Anna muutamia käyttötapoja tietoobjekteja.
Vastaus :
Tämä on Splunk-haastattelussa usein kysyttyjä kysymyksiä. Tietoobjekteja voidaan käyttää monilla aloilla. Muutamia esimerkkejä ovat:
Sovellusten seuranta: Tätä voidaan käyttää sovellusten seuraamiseen reaaliajassa konfiguroiduilla hälytyksillä, jotka ilmoittavat järjestelmänvalvojille / käyttäjille, kun sovellus kaatuu.
Fyysinen turvallisuus: Tulvan / tulivuoren jne. Tapauksessa tietoja voidaan käyttää oivalluksen saamiseksi, jos organisaatiosi käsittelee sellaisia tietoja.
Verkkoturva: Voit luoda turvallisen ympäristön sisällyttämällä mustien luetteloon tuntemattomien laitteiden IP-osoitteen ja vähentää siten tiedonvuodot missä tahansa organisaatiossa.
Työntekijöiden hallinta: Työntekijöiden katoaminen on yksi haasteista, joihin kaikki organisaatiot kohtaavat, ja irtisanomisaikana työntekijän toimintaa voidaan seurata organisaation tietojen suojaamiseksi, seuraamalla siten heidän toimintaa ja rajoittamalla muuta irtisanomisajan työntekijää tekemättä samaa .
8.Selitä hakukerroin (SF) ja replikaatiotekijä (RF)
Vastaus:
Näitä terminologioita käytetään Splunk-klusterointitekniikoissa. Indekseriklusteri on erityisesti määritetty ryhmä Splunk Enterprise -indeksereitä, joka toistaa ulkoista tietoa ja jota käytetään katastrofien palautukseen.
Splunk-dokumentaatiohaun kannalta tekijä voidaan kuvata seuraavasti: ”Hakemiskelpoisten kopioiden määrä tiedoista, joita indeksointiryhmä ylläpitää. Hakutekijän oletusarvo on 2 ”, kun taas replikaatiotekijä määritellään klusterin ylläpitämän datan kopioiden lukumääräksi.
Indeksi-klusterissa on sekä haku- että replikaatiotekijä, kun taas hakupään klusterissa on vain hakutekijä
Siirrytään seuraavaan Splunk-haastattelukysymykseen.
9. Mitä Splunk-kauhat ovat? Selitä kauhan elinkaari.
Vastaus:
Hakemistot, joihin indeksoitu data tallennetaan, tunnetaan nimellä Splunk-kauhat, ja niissä on tietyn ajanjakson tapahtumat. Splunk-kauhan elinkaari sisältää neljä vaihetta kuuma, lämmin, kylmä, jäädytetty ja sulatettu.
- Kuuma - Tämä ämpäri sisältää äskettäin indeksoidut tiedot ja on avoinna kirjoittamista varten.
- Lämmin - Kun tiedot putoavat kuumaan ämpäri, riippuen tietosääntöistään, se siirtyy lämpimiin kauhoihin
- Kylmä - Seuraava vaihe lämpimän jälkeen on kylmä vaihe, jossa tietoja ei voi muokata.
- Jäädytetty - Oletuksena indeksoija poistaa tiedot jäädytetyistä kauhoista, mutta ne voidaan myös arkistoida.
- Sulatettu - Tietojen hakeminen arkistoiduista tiedostoista (jäädytetty ämpäri) tunnetaan sulatuksena.
10. Miksi meidän pitäisi käyttää Splunk-hälytystä? Mitkä ovat eri vaihtoehdot hälytyksiä määritettäessä?
Vastaus:
Tila, joka on tarkkana mahdollisten virheiden varalta, tunnetaan hälytyksenä, ja Splunk-ympäristössä ympäristöhälytyksiä voi syntyä mahdollisten yhteysvirheiden tai tietoturvaloukkauksien tai käyttäjän luomien sääntöjen rikkomusten vuoksi.
Esimerkiksi lähettämällä ilmoituksia tai raportin käyttäjistä, jotka eivät ole kirjautuneet sisään, kun he ovat käyttäneet kolme yritystään portaalissa, sovelluksen järjestelmänvalvojalle.
Hälytysten asettamisessa käytettävissä olevat eri vaihtoehdot ovat:
- Voidaan luoda verkkohookki, joka kirjoittaa hälytykset hipchattiin tai GitHubiin.
- Lisää tuloksia, .csv tai pdf tai viestin rungon mukaisesti, jotta hälytyksen perimmäinen syy voidaan tunnistaa.
- Lippuja voidaan luoda ja hälytyksiä voidaan käyttää koneesta tai IP: stä.
Suositeltava artikkeli
Tämä on opas luetteloon hajautettujen haastattelujen kysymyksistä ja vastauksista, jotta hakija voi helposti hajottaa nämä hajautettuun haastatteluun liittyvät kysymykset ja vastaukset. Voit myös tarkastella seuraavia artikkeleita saadaksesi lisätietoja -
- SAS-järjestelmän haastattelukysymykset - 10 hyödyllistä kysymystä
- 10 erinomaista Tableau-haastattelukysymystä, jotka sinun on tiedettävä
- 15 menestyneintä Oracle-haastattelua koskevaa kysymystä ja vastausta
- Verkkoturvahaastattelukysymykset - suosituimmat ja eniten kysyttyjä
- Splunk vs Nagios