

Kartan esittely Liity pesään
Karttayhteys on ominaisuus, jota käytetään pesän kyselyissä tehostamaan sen nopeutta. Liittyminen on ehto, jota käytetään yhdistämään kahden taulukon tiedot. Joten kun suoritamme normaalin liittymisen, työ lähetetään Map-Reduce -tehtävään, joka jakaa päätehtävän kahteen vaiheeseen - “Map stage” ja “Reduce stage”. Kartta-vaihe tulkitsee syöttötiedot ja palauttaa tulosteen pienentämisvaiheeseen avain-arvo-parien muodossa. Seuraavaksi se menee sekoitusvaiheen läpi, missä ne lajitellaan ja yhdistetään. Pelkistin ottaa tämän lajitellun arvon ja suorittaa liittymistyön.
Taulukko voidaan ladata muistiin kokonaan karttaajassa ja ilman, että sinun on käytettävä Kartta / Vähennys-prosessia. Se lukee tiedot pienemmästä taulukosta ja tallentaa ne muistissa olevaan hash-taulukkoon ja sarjaa sitten sitten hash-muistitiedostoon vähentäen siten aikaa huomattavasti. Se tunnetaan myös nimellä Map Side Join in Hive. Pohjimmiltaan siihen sisältyy liitosten suorittaminen kahden taulukon välillä käyttämällä vain Kartta-vaihetta ja ohittamalla Pienennä-vaihe. Kyselyjen laskennassa voidaan havaita ajan pienentyminen, jos ne käyttävät säännöllisesti pieniä taulukon liittymiä.
Kartan syntaksi Liity pesään
Jos haluamme suorittaa liittymiskyselyn kartta-liittymisellä, meidän on määritettävä avainsanan ”/ * + MAPJOIN (b) * /” alla olevaan lauseeseen:
>SELECT /*+ MAPJOIN(c) */ * FROM tablename1 t1 JOIN tablename2 t2 ON (t1.emp_id = t2.emp_id);
Tässä esimerkissä meidän on luotava 2 taulukkoa, joiden nimillä taulukon nimi1 ja taulukon nimi2 on 2 saraketta: emp_id ja emp_name. Yhden pitäisi olla suurempi tiedosto ja yhden pitäisi olla pienempi.
Ennen kyselyn suorittamista meidän on asetettava alla oleva ominaisuus totta:
hive.auto.convert.join=true
Kartan liittymispyynnön liittymiskysely kirjoitetaan kuten yllä ja saatu tulos on:
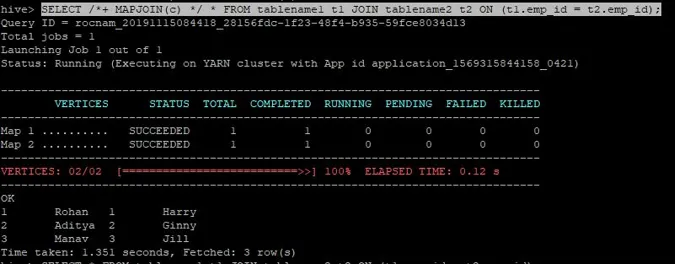
Kysely valmistui 1.351 sekunnissa.
Esimerkkejä kartasta Liity pesään
Tässä on seuraavat esimerkit, jotka mainitaan alla
1. Kartta-liittymäesimerkki
Luokaamme tässä esimerkissä kaksi taulukkoa nimeltään table1 ja table2 100 ja 200 tietueella. Voit viitata alla olevaan komentoon ja kuvakaappauksiin saman suorittamiseksi:
>CREATE TABLE IF NOT EXISTS table1 ( emp_id int, emp_name String, email_id String, gender String, ip_address String) row format delimited fields terminated BY ', ' tblproperties("skip.header.line.count"="1");
>CREATE TABLE IF NOT EXISTS table2 ( emp_id int, emp_name String) row format delimited fields terminated BY ', ' tblproperties("skip.header.line.count"="1");

Nyt lataamme tietueet molempiin taulukoihin käyttämällä alla olevia komentoja:
>load data local inpath '/relativePath/data1.csv' into table table1;
>load data local inpath '/relativePath/data2.csv' into table table2;
Annetaan suorittaa normaali kartta-liittymiskysely heidän henkilötodistuksissaan alla esitetyllä tavalla ja tarkistaa siihen kulunut aika:
>SELECT /*+ MAPJOIN(table2) */ table1.emp_name, table1.emp_id, table2.emp_id FROM table1 JOIN table2 ON table1.emp_name = table2.emp_name;
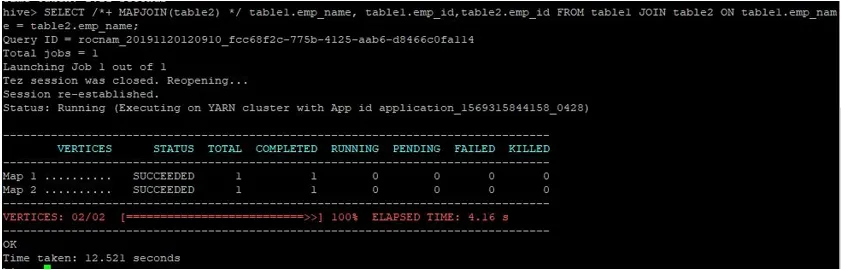
Kuten näemme, normaali kartta-liittymiskysely kesti 12, 521 sekuntia.
2. Bucket-Map Join esimerkki
Käytämme nyt Bucket-map liittyä käyttämään samaa. Kauhattamisessa on noudatettava muutamia rajoituksia:
- Kauhat voidaan yhdistää toisiinsa vain, jos minkä tahansa pöydän kokonais kauhat ovat monta kuin toisessa taulukossa olevien kauhojen lukumäärä.
- Pudottamisessa on käytettävä kauhoitettuja taulukoita. Siksi luodaan sama.
Seuraavassa on komennot, joita käytetään puskuroitujen taulukoiden taulukon1 ja taulukon2 luomiseen:
>>CREATE TABLE IF NOT EXISTS table1_buk (emp_id int, emp_name String, email_id String, gender String, ip_address String) clustered by(emp_name) into 4 buckets row format delimited fields terminated BY ', ';
>CREATE TABLE IF NOT EXISTS table2_buk ( emp_id int, emp_name String) clustered by(emp_name) into 8 buckets row format delimited fields terminated BY ', ' ;

Lisäämme samat tietueet taulukosta1 myös näihin kopioituihin taulukoihin:
>insert into table1_buk select * from table1;
>insert into table2_buk select * from table2;
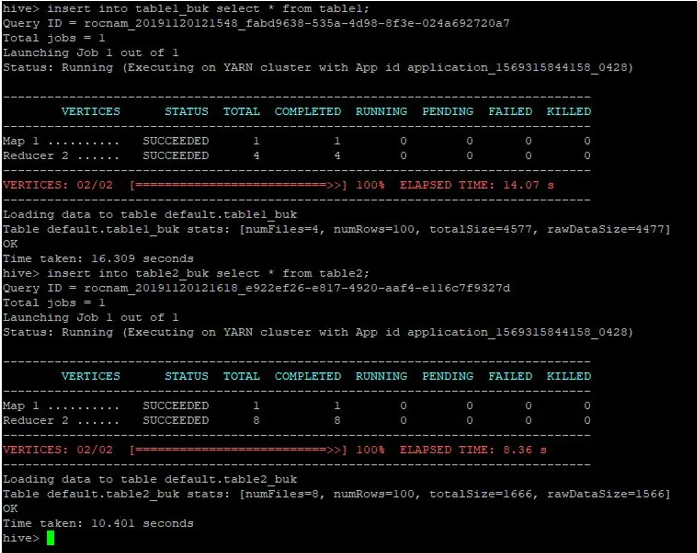
Nyt kun meillä on 2 kauhattaulukkoa, suoritetaan ämpärikartan liittyminen näihin. Ensimmäisessä taulukossa on 4 kauhaa, kun taas toisessa taulukossa on 8 kauhaa, jotka on luotu samaan sarakkeeseen.
Jotta kauhakartta-liittymiskysely toimisi, meidän tulisi asettaa alla oleva ominaisuus todelliseksi pesässä:
set hive.optimize.bucketmapjoin = true
>SELECT /*+ MAPJOIN(table2_buk) */ table1_buk.emp_name, table1_buk.emp_id, table2_buk.emp_id FROM table1_buk JOIN table2_buk ON table1_buk.emp_name = table2_buk.emp_name ;
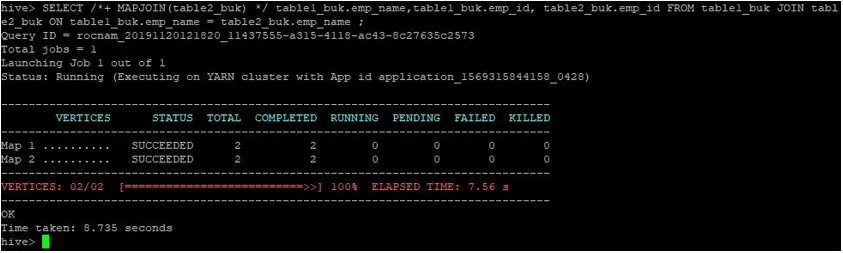
Kuten näemme, kysely saatiin päätökseen 8, 735 sekunnissa, mikä on nopeampaa kuin normaali kartan liittyminen.
3. Lajittele yhdistämiskampanjakartta Liity esimerkkiin (SMB)
SMB voidaan suorittaa pursotettuihin taulukoihin, joissa on sama määrä kauhoja, ja jos taulukot on lajiteltava ja kopioitava yhdistämissarakkeissa. Mapper-taso yhdistää nämä kauhat vastaavasti.
Samoin kuin Bucket-map-liittymässä, taulukkoon1 on 4 kauhaa ja taulukkoon 2 kauhaa. Tässä esimerkissä luomme toisen taulukon, jossa on 4 kauhaa.
SMB-kyselyn suorittamiseksi meidän on asetettava seuraavat pesän ominaisuudet seuraavasti:
Hive.input.format = org.apache.hadoop.hive.ql.io.BucketizedHiveInputFormat;
hive.optimize.bucketmapjoin = totta;
hive.optimize.bucketmapjoin.sortedmerge = totta;
Jotta SMB-liittyminen voidaan suorittaa, siellä on oltava lajiteltuja liittymissarakkeiden mukaisia tietoja. Siksi korvaamme taulukossa 1 olevat tiedot, jotka on koottu seuraavasti:
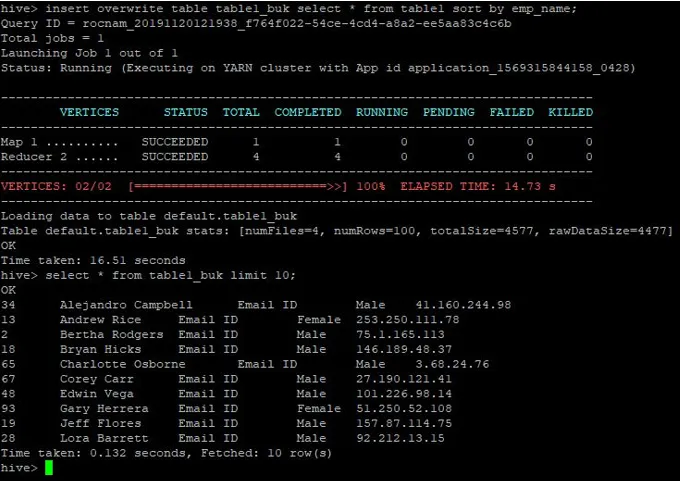
>insert overwrite table table1_buk select * from table1 sort by emp_name;
Tiedot on lajiteltu nyt, mikä näkyy alla olevassa kuvakaappauksessa:
Korvaamme myös tiedot kopioidussa taulukossa 2 seuraavasti:
>insert overwrite table table2_buk select * from table2 sort by emp_name;

Suoritetaan yhdistäminen yli 2 taulukolle seuraavasti:
>SELECT /*+ MAPJOIN(table2_buk) */ table1_buk.emp_name, table1_buk.emp_id, table2_buk.emp_id FROM table1_buk JOIN table2_buk ON table1_buk.emp_name = table2_buk.emp_name ;
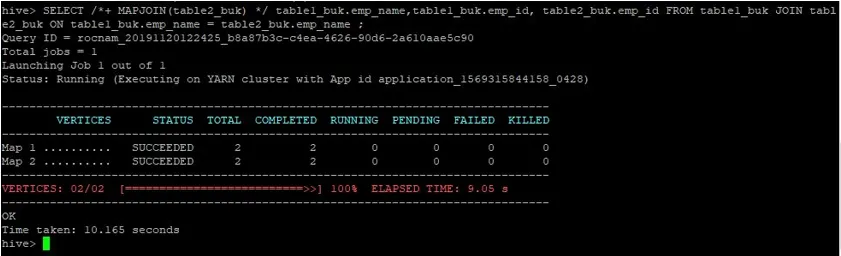
Voimme nähdä, että kysely kesti 10, 165 sekuntia, mikä on jälleen parempi kuin normaali kartan liittyminen.
Luokaamme nyt uusi taulukko taulukolle 2, jossa on 4 kauhaa ja samat tiedot lajiteltu nimellä emp_name.
>CREATE TABLE IF NOT EXISTS table2_buk1 (emp_id int, emp_name String) clustered by(emp_name) into 4 buckets row format delimited fields terminated BY ', ' ;
>insert overwrite table table2_buk1 select * from table2 sort by emp_name;
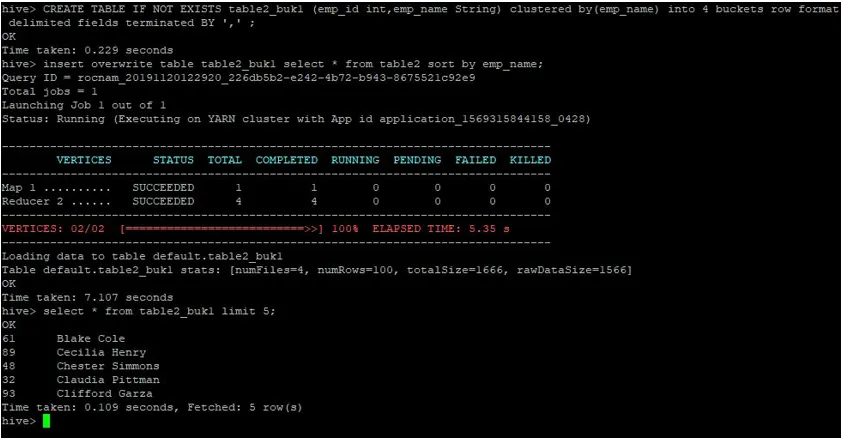
Ottaen huomioon, että meillä on nyt molemmat taulukot, joissa on 4 kauhaa, suorittakaamme jälleen liittymiskysely.
>SELECT /*+ MAPJOIN(table2_buk1) */table1_buk.emp_name, table1_buk.emp_id, table2_buk1.emp_id FROM table1_buk JOIN table2_buk1 ON table1_buk.emp_name = table2_buk1.emp_name ;
Kysely on ottanut 8.851 sekuntia taas nopeammin kuin normaali kartan liittymiskysely.
edut
- Kartan liittyminen vähentää sekoituksessa tapahtuviin lajittelu- ja yhdistämisprosesseihin kuluvaa aikaa ja vähentää vaiheita, minimoiden siten myös kustannukset.
- Se lisää tehtävän suorituskykyä.
rajoitukset
- Samaa taulukkoa / aliasta ei saa käyttää eri sarakkeiden yhdistämiseen samassa kyselyssä.
- Kartan liittymiskysely ei voi muuttaa kokonaisia ulkoisia liitoksia kartan puoleisiksi liitoksiksi.
- Kartan yhdistäminen voidaan suorittaa vain, jos yksi pöydistä on riittävän pieni, jotta se mahtuu muistiin. Siksi sitä ei voida suorittaa, jos taulukkotiedot ovat valtavat.
- Vasemmanpuoleinen liittyminen on mahdollista tehdä karttayhteyteen vain, kun oikea pöydän koko on pieni.
- Oikeanpuoleinen liittyminen on mahdollista tehdä karttayhteyteen vain, kun vasemmanpuoleinen taulukon koko on pieni.
johtopäätös
Olemme yrittäneet sisällyttää parhaat mahdolliset Kartta Join in Hive -pisteet. Kuten yllä olemme nähneet, karttapuolen liittyminen toimii parhaiten, kun yhdellä taulukolla on vähemmän tietoja, jotta työ saadaan valmiiksi nopeasti. Tässä esitetyille kyselyille kulunut aika riippuu tietojoukon koosta, joten tässä näytetty aika on tarkoitettu vain analysointia varten. Karttayhteys voidaan helposti toteuttaa reaaliaikaisissa sovelluksissa, koska meillä on valtava data, mikä auttaa vähentämään verkon I / O-liikennettä.
Suositellut artikkelit
Tämä on opas Map Join in Hive -karttaan. Tässä keskustellaan Map Join in Hive -esimerkkeistä sekä eduista ja rajoituksista. Voit myös tarkastella seuraavaa artikkelia saadaksesi lisätietoja -
- Liittyy Hiveen
- Pesän sisäänrakennetut toiminnot
- Mikä on pesä?
- Pesän komennot