
Johdatus vahvistusoppimiseen
Vahvistusoppiminen on eräänlaista koneoppimista, joten se on myös osa tekoälyä, kun järjestelmiin sovelletaan järjestelmiä, jotka suorittavat vaiheet ja oppivat vaiheiden lopputuloksen perusteella saadakseen monimutkaisen tavoitteen, joka asetetaan järjestelmän saavutettavaksi.
Ymmärrä vahvistusoppiminen
Yritetään kokeilla vahvistusoppimista 2 yksinkertaisen käyttötavan avulla:
Tapaus # 1
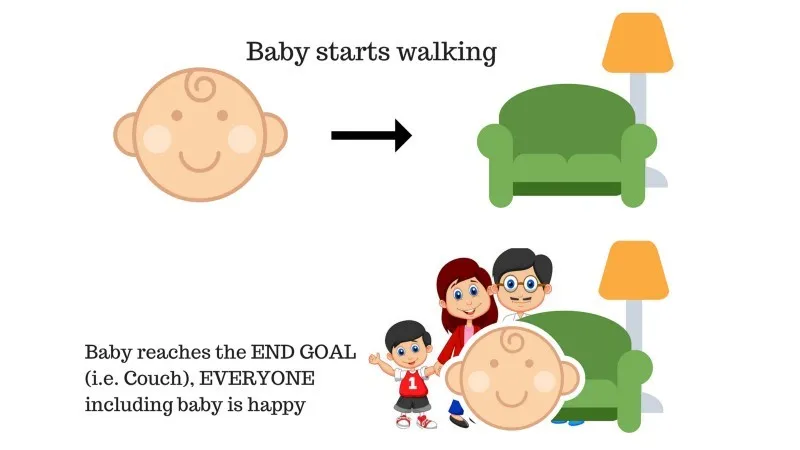
Perheessä on vauva ja hän on juuri alkanut kävellä ja kaikki ovat siitä varsin iloisia. Eräänä päivänä vanhemmat yrittävät asettaa tavoitteen, anna meidän vauvan päästä sohvalle ja nähdä, pystyykö vauva siihen.
Tapauksen 1 tulos: Vauva saavuttaa onnistuneesti penkillä, joten kaikki perheen jäsenet ovat erittäin iloisia nähdessään tämän. Valitulle polulle tulee nyt positiivinen palkkio.
Pisteet: Palkitse + (+ n) → Positiivinen palkinto.
Lähde: https://images.app.goo.gl/pGCXJ1N1bzLAer126
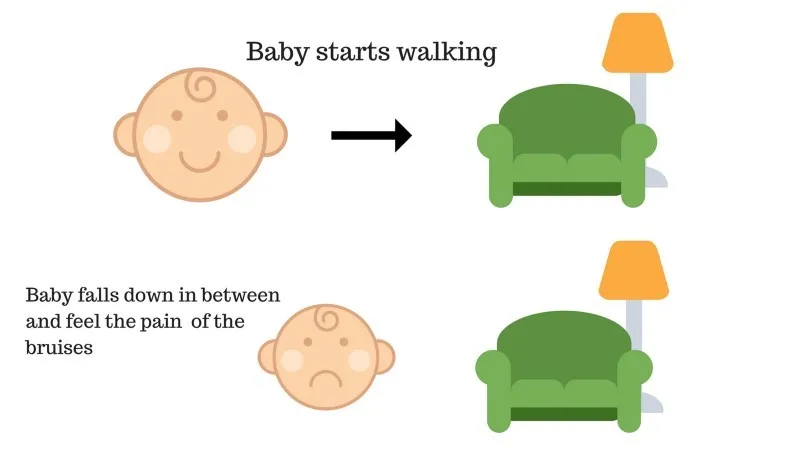
Tapaus 2
Vauva ei päässyt sohvalle ja vauva on pudonnut. Se sattuu! Mikä voi olla syy? Polulla sohvalle saattaa olla joitain esteitä ja vauva oli pudonnut esteisiin.
Tapaus 2: Vauva putoaa esteisiin ja itkee! Voi, se oli huono, hän oppi, olemaan joutumatta esteen ansaan seuraavalla kerralla. Valitulle polulle tulee nyt negatiivinen palkkio.
Pisteet: Palkinnot + (-n) → Negatiivinen palkinto.
Lähde: https://images.app.goo.gl/FRfd8cUqrQRLe6sZ7
Nyt olemme nähneet tapaukset 1 ja 2, vahvistamisoppiminen käsitteellisesti tekee saman, paitsi että se ei ole ihminen, vaan suoritetaan laskennallisesti.
Vahvistuksen käyttö vaiheittain
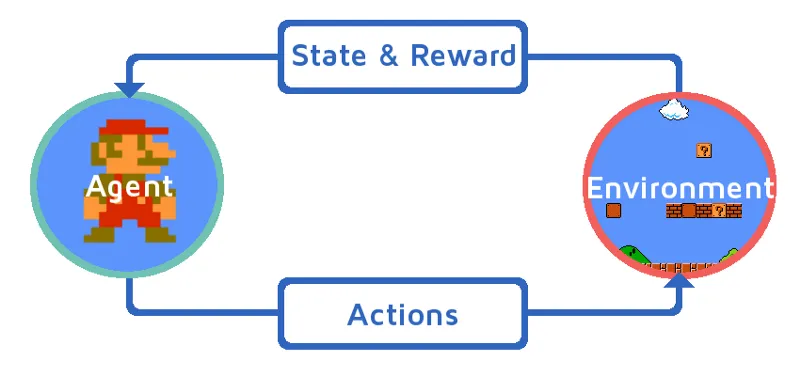
Ymmärtäkäämme vahvistusoppimista tuomalla vahvistusaine vaiheittain. Tässä esimerkissä vahvistusta oppiva agenttimme on Mario, joka oppii pelaamaan yksinään:
Lähde: https://images.app.goo.gl/Kj44uvBzWzMw1QzE9
- Mario-peliympäristön nykytila on S_0. Koska peli ei ole vielä alkanut ja Mario on paikoillaan.
- Seuraavaksi peli aloitetaan ja Mario liikkuu, Mario eli RL-agentti ryhtyy ja toimii, sanotaan A_0.
- Nyt peliympäristön tilasta on tullut S_1.
- Myös RL-edustajalle, eli Mariolle, on nyt annettu jokin positiivinen palkitsemispiste, R_1, luultavasti siksi, että Mario on edelleen elossa eikä mitään vaaraa kokenut.
Nyt yllä oleva silmukka jatkaa toimintaa, kunnes Mario on lopulta kuollut tai Mario saavuttaa määränpäähänsä. Tämä malli tuottaa jatkuvasti toiminnan, palkinnon ja tilan.
Maksimointipalkinnot
Vahvistavan oppimisen tavoitteena on maksimoida palkkiot ottamalla huomioon tietyt muut tekijät, kuten palkkioalennus; selitämme pian kuvion avulla, mitä alennuksella tarkoitetaan.
Alennettujen palkkioiden kumulatiivinen kaava on seuraava:
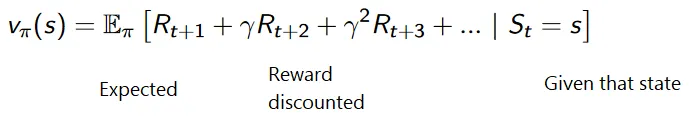
Alennuspalkkiot
Ymmärtäkäämme tämä esimerkin avulla:
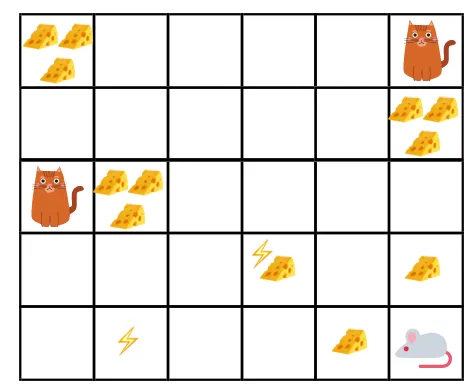
- Annetussa kuvassa tavoitteena on, että pelin hiiren täytyy syödä niin paljon juustoa, ennen kuin kissa syö tai ei saa sähköshokkiin.
- Nyt voimme olettaa, että mitä lähempänä olemme kissaa tai sähköloukkua, sitä todennäköisempää on, että hiiri voi syödä tai järkyttyä.
- Tämä tarkoittaa, että vaikka meillä on täysi juusto lähellä sähköiskua tai kissan lähellä, on vaarallisempaa syödä siellä lähellä olevaa juustoa riskien välttämiseksi.
- Joten vaikka meillä on yksi juusto "block1", joka on täynnä ja on kaukana kissasta ja sähköiskun lohkosta, ja toinen "block2", joka on myös täynnä, mutta on joko lähellä kissaa tai sähköisku, myöhemmälle juustoyksikölle, eli ”lohko2”, alennetaan palkkioita enemmän kuin edellinen.
Lähde: https://images.app.goo.gl/8QrH78FjmRVs5Wxk8
Lähde: https://cdn-images-1.medium.com/max/800/1*l8wl4hZvZAiLU56hT9vLlg.png.webp
Vahvistusoppimisen tyypit
Ohessa on kaksi vahvistusopetuksen tyyppiä sekä niiden edut ja haitat:
1. Positiivinen
Kun käytöksen vahvuus ja taajuus lisääntyvät jonkin tietyn käytöksen esiintymisen vuoksi, se tunnetaan nimellä Positiivinen vahvistusoppiminen.
Edut: Suorituskyky on maksimoitu ja muutos pysyy pidempään.
Haitat: Tulokset voivat vähentyä, jos meillä on liikaa vahvistusta.
2. Negatiivinen
Se on käyttäytymisen vahvistamista, lähinnä negatiivisen termin katoaessa.
Edut: Käyttäytyminen lisääntyy.
Haitat: Vain mallin minimikäyttäytyminen voidaan saavuttaa negatiivisen vahvistusoppimisen avulla.
Missä vahvistusoppimista tulisi käyttää?
Asiat, jotka voidaan tehdä vahvistusoppimisella / esimerkkejä. Seuraavassa on alueita, joilla vahvistusoppimista käytetään nykyään:
- Terveydenhuolto
- koulutus
- Pelit
- Konenäkö
- Liiketoiminnan hallinta
- robotiikka
- Rahoittaa
- NLP (luonnollisen kielen käsittely)
- kuljetus
- energia
Ura vahvistusoppimisessa
Työsivustolta on todellakin raportti, koska RL on raportin mukaan koneoppimisen ala, koneoppiminen on vuoden 2019 paras työ. Alla on raportin tilannekuva. Nykyisten suuntausten mukaan koneoppimisinsinöörien keskimääräinen palkka on 146 085 dollaria ja kasvuvauhti 344 prosenttia.
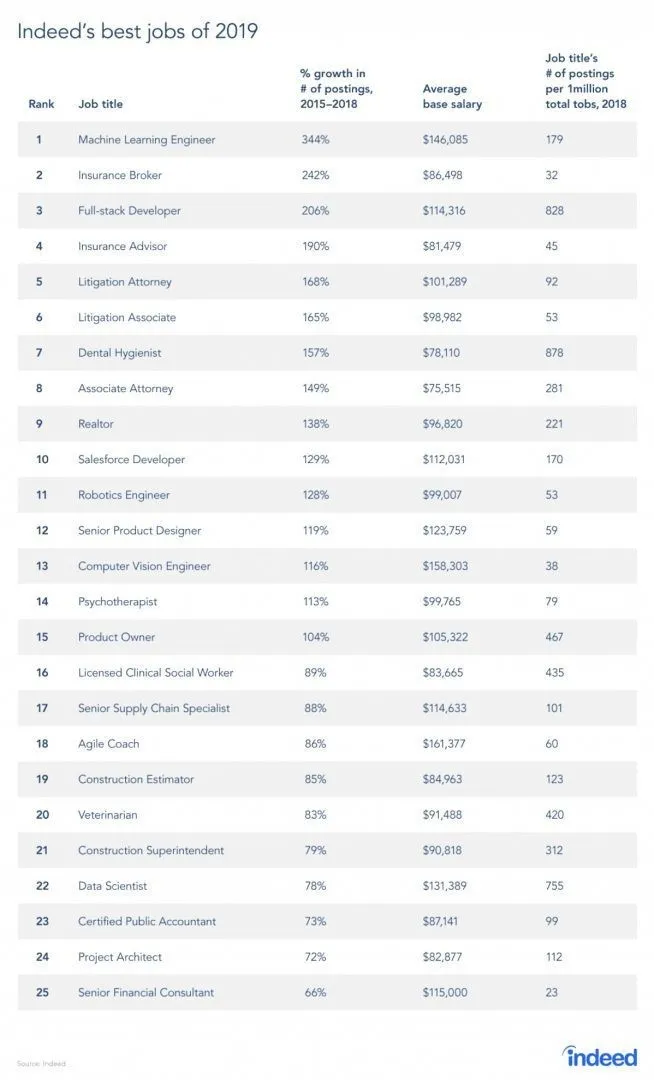
Lähde: https://i0.wp.com/www.artificialintelligence-news.com/wp-content/uploads/2019/03/indeed-top-jobs-2019-best.jpg.webp?w=654&ssl=1
Vahvistustaidot
Alla on vahvistusoppimiseen tarvittava taito:
1. Perustaidot
- Todennäköisyys
- tilasto
- Tietojen mallintaminen
2. Ohjelmointitaidot
- Ohjelmoinnin ja tietotekniikan perusteet
- Ohjelmistojen suunnittelu
- Pystyy soveltamaan Machine Learning -kirjastoja ja algoritmeja
3. Koneoppimisen ohjelmointikielet
- pytonkäärme
- R
- Vaikka on myös muita kieliä, joissa koneoppimismalleja voidaan suunnitella, kuten Java, C / C ++, mutta suosituimpia kieliä ovat Python ja R.
johtopäätös
Aloitimme tässä artikkelissa lyhyellä johdannon oppimisella vahvistumisesta ja pohdimme sitten syvällisesti RL: n toimintaa ja monia RL-mallien toimintaan liittyviä tekijöitä. Sitten olimme laatineet reaalimaailman esimerkkejä ymmärtääksesi vielä paremmin aihetta. Tämän artikkelin loppuun mennessä tulisi olla hyvä ymmärrys vahvistusoppimisen toiminnasta.
Suositellut artikkelit
Tämä on opas Mitä on vahvistusoppiminen ?. Tässä keskustellaan esimerkistä vahvistusoppimallien kehittämiseen liittyvästä toiminnasta ja erilaisista tekijöistä. Voit myös käydä läpi muiden aiheeseen liittyvien artikkeleidemme saadaksesi lisätietoja -
- Koneoppimisen algoritmien tyypit
- Johdatus tekoälyyn
- Keinotekoisen älykkyyden työkalut
- IoT-alusta
- Kuusi parasta koneoppimisen ohjelmointikieltä